Das aktuelle Konzept mit Baustein R (2 identisch strukturierte Dateien GEM und DSGA/DSGR) für Demografische Sondergruppen eignet sich gut für grobkörnige Prognosen, z.B. für eine Gesamtstadtprognose:
- die GEM-Datei enthält die Bevölkerungspyramide der Stadt ohne Sonderguppen
- die DSGA/DSGR-Datei enthält die Bevölkerungspyramide aller Sondergruppen absolut/als Rate
- die Datei DSGA/DSGR wird riesig, ist aber fast leer.
- will man unterschiedliche demografische Sondergruppen
(z.B. JVA's und Altenheime (AH)) unteschiedlich behandeln,
so müsste man mehrere Dateien (z.B. DSGA_JVA und DSGA_AH) einführen.
Alternativ können demografische Sondergruppen als einzelne Gebiete
der gem-Datei modelliert werden.
Die Eigenschaften der Gebiete werden in der Datei reftyp festgelegt.
Enthält ein Gebiet einen Typ 0, z.B. Typ Geburtenraten TYG = 0,
dann sind alle Geburtenraten für dieses Gebiet gleich 0.
Mit einer neuen Spalte TYAGF (Typ Altersgruppenfortschreibung) in REFTYP
legt man fest, ob für das Gebiet normale Altersgruppenfortschreibung gilt.
TYAGF ist nicht wie z.B. "Typ Geburtenraten" ein Index in eine
Ratendatei "fruc", sondern hat 2 vordefinierte Werte:
| 0 | Gebiet ohne Altersgruppenfortschreibung Geburten, Sterbefälle, Wanderungen können (müssen aber nicht) durch einen Typ Geburten, Sterbefälle, ... bei dem alle Raten 0 sind, ausgeschlossen werden. Eine Zeile in reftyp.csv für eine demografische
Sondergruppe sieht typischerweise wie folgt aus:103;DSG xy;0;0;0;0;0;0;0;0;0;0;12
|
|---|---|
| 1 | Gebiet mit Altersgruppenfortschreibung |
Damit kann man Demografische Sondergruppen in unterschiedlicher Granularität modellieren:
- ein Gebiet enthält die Bevölkerung aller Sondergruppen
- man fasst jeden Typ Demografische Sondergruppe (Altenheim, Justizvollzugsanstalt, ...) in jeweils einem Gebiet zusammen
- Jede Einrichtung (Altenheim Kieferngarten, Altenheim Sendling, JVA Stadelheim, ...) wird für die Prognose ein eigenes Gebiet (und bei Bedarf nach der Prognose zu höheren Aussageneinheiten aggregiert)
Weitere Beiträge:
- Taxonomie demografischer Sondergruppen (m-?) (Altenheim, Asyl-/Flüchtlings-unterkunft, Internat, Jugenheim, Kaserne, Kloster, Krankenhaus, Strafanstalt, Schwesternwohnheim, Studentenheim, ...) und ihrer Eigenschaften (demografische Entwicklung, Altersfortschreibung, ...)
- Vorschlag Dr. Tüllmann
- Weitergehendes Diskussionspapier Lindemann
- (s) sobald ANSTI/ANSTE
(blank: unbekannt, 0: Wohnheim, 1: normale Adresse, 2: Anstalt)
im Datensatz Bewegung vorliegt,
kann folgende Erweiterung der Berechnung
Makrodateien aus Statistikdatensatz Bestand und Bewegung benutzt werden:
Abbildung R02/R02U2/ANSTI/ANSTE
Der Wert "blank: unbekannt" wird als 9 codiert, da die kleinräumige Gliederung in den Makrodateien keine Leerstellen enthalten darf.4e 4 Stellen R02 + ANSTE 3i 3 Stellen R02 + ANSTI #123e 3 Stellen R02 + ANSTE - Vorschlag Utz Lindemann für Lenkungsgruppe 20151130 SIKURS Sonderbevölkerung
- (s) abermalige Konzeptänderung "goaf" wurde wieder verworfen
. . . . . .
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Um die Einarbeitung eines Systemexperten in das Programm zu erleichtern wurde ein Entwicklerhandbuch, grobes eva.htm, feines Datenflussdiagramm sikurs.htm erstellt.
{kind=link}
Die Ausgabedatei rea.csv enthält Wanderung in die Außentypen gegliedert nach Typ Rückbau, Außentyp und demographisch Gliederung.
Alternativ könnte man wegzug.csv um den Anteil Außenwanderung aus Rückbau erweitern (Problem Differenzierung NTYQWA, NTYREA oder NGZ).
Die Reihenfolge der Spalten in neubauzu.csv und rueckbauweg.csv wurde geändert in
neubauzu.csv : Jahr, Erstbezugstyp, Außentyp, Anteil rueckbauweg.csv: Jahr, Rückbauendauszugstyp, Außentyp, AnteilDie Ausgabedateien BEW, BEWAGG, BEWGEM, BEWGEMAGG werden um die neuen Ströme erweitert
- Rückbauendauszug nach außen
- Rückbauendauszug nach innen
- Binnenzuzug aus Rückbauendauszug
- ZB Binneneinzug ohne Erstbezug und Rückbauendauszug
- II Inneneinzug ohne Erstbezug und Rückbauendauszug
Der Baustein X (X1/X2) wurde gestrichen, weil man dessen Wirkung durch die Datei
neubauzu.csv (später umbenannt in nebqqa.csv) #Jahr;Erstbezugstyp;Außentyp;Anteil *;*;*;0erzielen kann.
Überarbeitung Rückbaualgorithmus nach Vorgaben Methodenexperte (mit Integration Ausgabedatei rea.csv in wegzug.csv)
Verbesserung freie Wohnkapazität bei Neubau und Rückbau für Innenwanderung
Für folgende kleinräumige Prognose (beispiel/rueckbau_total)
ist der Baustein noch nicht gut geeignet:
Jedes Gebiet entspreche einem Block (oder Wohnadresse).
Ein Gebiet = Block soll vollständig rückgebaut werden (Endbevölkerung = 0).
Die dazu nötige Anzahl Rückbauendauszieher (ruckbaub)
und die Aufteilung der Rückbauendauszugsbevölkerung (reaq)
kann man nur durch aufwändiges systematisches variieren der Werte
(Extra/Eigen Scripts/Start/rueckbau_total.pl)
ermitteln.
- Erstellung Testbeispiele, in denen jeder Baustein mindestens
einmal vorkommt mit zusätzlichen Plausibilitätschecks.
Hauptmaske/Extras/Eigene Scripts/Start
Sammelprognose.pl oder
shortcut: D:\trunk\Sikurs\scripts\run.bat Sammelprognose.pl -i=D:\trunk\Sikurs\Beispiel\baustein -p=0 -t=1 -d=1
Ordner: .../Beispiel/baustein - Neue Regel Methodenassistent
(Die Regeln sind im Methodenassistenten als Kommentar hinterlegt
(grep #! TkAssi.pm))
- Wenn Baustein N2 N3 N4 und Baustein K2 K3 K4, dann nur in den Kombinationen N2 K2, N3 K3, N4 K4
- Bei T2 immer NTYA > 1 erlauben (bei T1: NTYA = 1)
- Bei K1-K4 und N>1 wird auf das Einlesen von zuvol.csv verzichtet, das die Anpassungsinformation aus saldvol.csv kommt (Beispiel Herr Bolz)
- Fehlerbehebung Baustein R1/2, B1, M1, I1, P4, E1:
Bei der Aufstellung der Strommatrix wird geprüft, ob die Zielbevölkerung negativ ist und korrigiert, bei R1/2 darf die Zielbevölkerung bzw. Untergrenze aber negativ sein.
- Bei der Anpassung der Außen-Zu/Weg-züge muss zusätzlich
der Rückbauendauszug berücksichtigt werden.
- Bei der Innenwanderung wird der Rückbauendauszug auch zusätzlich
berücksichtigt, die verbessert das Ergebnis, aber die Obergrenze
Gebiet wird im Beispiel beispiel/baustein/M1B1K1I1P2D2E1R1G1S1W1Y1
immer noch leicht überschritten.
- Für alle Bausteine P1-P4 wurde eine Prüfung eingebaut,
ob die Zielwerte/Entwicklungsgrenzen erreicht wurden.
Negativer Zuzug in N4B1K4R1 war falsch (bei Zielwert Wanderungsbilanz (Baustein N) keine Berücksichigung der Demografischen Sondergruppen nötig), deshalb Umwandlung negativen Zuzug in Wegzug (!WNZIW) unnötig
Berücksichtigung Innenwanderung bei der Berechnung der freien Wohnkapazität der Gebietseinheiten ergänzt.
mit sehr vielen Gebieten bei denen viele Balken der Bevölkerungspyramide nicht besetzt sind, werden möglich durch
Extras/Eigene Scripts/Start/microsim.plleitet GEM und REFTYP aus DSTBEST differenziert nach Haushalten ab- die Maximalzahl Stellen für die Gebietskennziffer in der GEM-Datei und REFTYP-Datei wurde von 9 auf 18 verdoppelt.
- die Größe der REFTYP-Datei läßt sich durch Vorgabe signifikanter Stellen beim Zugriff auf die REFTYP-Datei reduzieren.
- ab einem Schwellwert werden die Datenstrukturen für die Gebiete und die Binnenwandeungsmatrix als Sparse-Matrizen aufgebaut, was Speicherplatz und Rechenzeit spart
- wenn die GEM-Ausgangsdaten ganzzahlig sind, kann ganzzahlig mit der Monte-Carlo Methode gerechnet werden. Dies verhindert, dass aus der dünn besetzten Ausgangs-GEM-Datei nach wenigen Jahren eine voll (wenn auch mit sehr kleinen Werten) besetzte GEM-Datei wird.
- die Innenwanderung nach freier Wohnkapazität kann bei Baustein I1 beschleunigt werden
Durchgeführte Beispielrechnungen
- bloecke_neu: Blöcke (K3, I1, D1, W1)
5 Stellen R02, 3409 Blöcke, 492098 Einwohner, 144 Einwohner pro Block, zu 22% besetzte GEM-Datei bei 2 BG, 2 GG
Prognose langsam aber machbar.
[2387551922 0]Monte-Carlo Methode
um Faktor 5 schneller.
!SPARSEGEM 50
nur um 5% schneller - Prog_adress: Postadressen (C2, K2, I1, G1, S1)
6 Stellen R02, 62689 Postadressen, 509005 Einwohner, 8,11 Einwohner pro Adresse
zu 3,7% besetzte GEM-Datei bei 1 BG, 2 GG
d.h. von Single in Einfamilenhaus bis 1000 Personen in Hochhaus
Die Datei reftyp läßt sich durch Streichen der letzten 4 Stellen im Gebietskennzeichen von 62696 Sätzen auf 2842 Sätze reduzieren - haushalt_anonym (T1)
303905 Haushalte, 571641 Personen, 1,88 Personen pro Haushalt
Anonymisierte Beispieldaten R03, R02, HHNR (KERNHH), A03
Für die Ermittlung von GKZ für reftyp und gem gibt es folgende Varianten (siehe haushalt_anonym/gemref(ast).pl)- sig + lfd + KERNHH (15 Stellen)
sigR02 ist die Anzahl signifikaner Stellen von R02 in Bereich 0-7
lfd ist eine laufend Nummer der Postadresse R03 mit gleicher R02 mit 11 - sigR02 Stellen
KERNHH ist die 4-stellige laufende Nummer des Haushalts an einer Postadresse
Extras/Eigene Scripts/Start/microsim.pl
ist eine Beispielprogramm für die Ableitung von GEM und REFTYP aus dstbest differenziert nach Haushalten.
MitEinwohner/Prognose/Berechnen Notiz !option($MONTE_CARLO 1) !option($ZOMBIE 0) !option($RANDOMLIMIT 1000) !option($MBF 3)
können Sie Ihre erste Prognose auf Basis Haushalten starten - R03U1 + R03U2 + R03U3 + KERNHH (5+4+2+4 Stellen)
R03U3 ist der Hausnummerzusatz, z.B. "1 ", "A ", "B1"
Da das Gebietskennzeichen in SIKURS numerisch mit max. 18 Stellen sein muss, muss man diese Codierung in Zahlen umwandeln.
Alternativ könnte man in SIKURS das Gebietskennzeichen auf alphanumerisch umstellen. - lfd
die R03+KERNHH (Postadressen+Haushalte) werden durchnummeriert, im Gebietsnamen von REFTYP speichert man R03U1 + R03U2 + R03U3 + KERNHH sowie optional weitere Felder (z.B. R01, R02) - 5 Stellen von R01 + 4 Stellen laufende Nummer Haushalt.
GEM hat 571641 Datensätze und 303904 GKZ=Haushaltschlüssel
REFTYP hat 764 Schlüssel aus den ersten 5 Stellen von R01
classic Klassische deterministische Prognose 1 - 10 10 Monte-Carlo Prognosen mean Mittelwert der Monte-Carlo-Prognosen 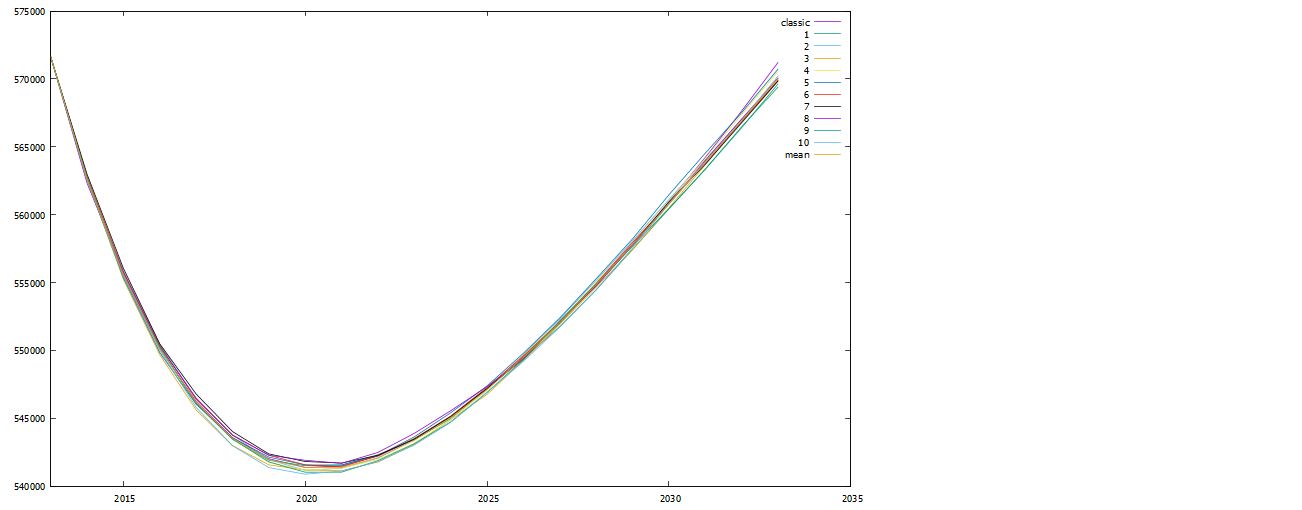
- sig + lfd + KERNHH (15 Stellen)
- .../sikurs/beispiel/haushalt
enthält synthetische Testbeispiele für Haushalte
- tiny.ini (T1)
REFTYP mit 2 Gebieten
GEM mit 7 Personen in 3 Haushalten - big.ini (T1)
NGZ Haushalte mit je Vater, Mutter, 1 Kind
NGZ wird im Reiter Generic-Beispiel
[1000000 ] Anzahl Gebietseinheiten
vorgegeben
REFTYP mit NGZ Sätzen
GEM mit 3*NGZ Sätzen - t2k5.ini (K5)
wie big.ini, aber mit Außenwegzug und Außenzuzug und mit reftyp wie huge.ini.
Funktioniert mit 7.000.000 Haushalten zu je 3 Personen - t2k5i1d1r2.ini (K5 I1 D1 R2)
wie t2k5.ini + Binnenwanderung, Neubau und Demografischen Sondergruppen - huge.ini (T1)
NGZ Single-Haushalte mit zufälligem Alter und Geschlecht
NGZ wird im Reiter Generic-Beispiel
[20000000 ] Anzahl Gebietseinheiten
vorgegeben
(mit 4 GByte Hauptspeicher NGZ bis zu 25 Millionen)
REFTYP mit einem Satz
GEM mit NGZ Personen = NGZ Haushalten
- tiny.ini (T1)
- gem-Ausgangsdatei und alle gem-Ergebnisse nach gem.csv ausgeben
Die Ausgabedateien agg, bew(gem(agg)), strom, wegzug, zuzug enthalten die Zeitreihe aller Prognosejahre.
Diese Konvention sollte man auf gemYYYY und gebamYYYY ausdehnen.
Mit dem Zeitreihentool kann man bei der Prognose oder anschließend alle gem-Dateien in die Datei zr_gem.csv zusammenfassen.
Es wäre praktischer gleich bei der Prognose auf die Ausgabedateien gem2013.csv, gem2015.csv, ... zu verzichten und stattdessen die gem-Ausgabgsdatei gem2012.csv und alle Ergebnisse nach gem.csv zu schreiben.
Option kann getestet werden durch:Einwohner/Prognose/Notiz !GEMALL 0 - (Voreinstellung) Ausgabe gem2013.csv, gem2014.csv, ... !GEMALL 1 - Ausgabe aller Prognosejahre in gem.csv !GEMALL 2 - Ausgabe gem-Ausgangsdatei und alle Prognosejahre in gem.csv (wie bei zr_gem.csv)
- Ab Protokollumfang 2 Ausgabe nach Außentypen differenzierten Außenzuzug und
Außenwegzug ins Protokoll, jedoch ohne die demographische Differenzierung
der Ausgabedateien zuzug.csv, wegzug.csv.
Damit kann man die Plausibilität der Außenwanderung ohne aufwändige Aufbereitung der Dateien zuzug.csv und wegzug.csv prüfen. - Die Formatierung der Zahlen im Protokoll und csv-Dateien könnte man ändern:
- Einstellung
- Format (fixed, scientific, defaultfloat)
- precision (15)
- Tausender Trennzeichen [v]
- Dies ergibt je nach Ländereinstellung
- "" oder "german" 123.456,78
- "english" 123,456.78
- "swiss" 123'456.78
- Einstellung
Bei Baustein G1 Eckwert für Geburten stimmen die Fruchtbarkeitsindikatoren nicht, bei Baustein S1 Eckwert für Sterbefälle stimmem Lebenserwartung und rohe Sterberate nicht.
Lösung:
Ausgabe der bei der Prognose ermittelten Anpassungsfaktoren
in die Datei frucfak.csv bzw. strbfak.csv:
# Jahr: Anpassungsfaktor Geburten bzw Sterberate 1992;0,8175Bei G0 bzw. S0, d.h. bei fehlender Datei ist dieser Anpassungsfaktor 1 Multiplikation der Raten mit diesen Anpassungsfaktoren
Das Indikatortool prüft, ob Baustein G1 oder S1 vorliegt und liest dann die Dateien frucfak bzw. strbfak und berechet die tatsächlichen Geburten- bzw. Sterberaten.
Da nachfolgender gnuplot Fehler #1279 (09.09.2013) behoben ist, Voreinstellung für Ausgabeformat bei Visualisierung/Zeitreihen/XY-Plot/Flächenplot (TkVEck) von wxt zu windows zurückändern
29.12.3013 "Bastian Märkisch" markisch@users.sf.net bug fixed+closed
# problem gnuplot 4.6.3 - plots 2003 .. 2005 - should plot until 2007 # work around # a) set term wxt # b) no 'fillstyle transparent solid 0.75' set term windows set yrange [0:*] plot '-' with filledcurves lt 1 fillstyle transparent solid 0.75 2003 3000 0 2004 4000 0 2005 4775 0 2006 4775 0 2007 4775 0 eAb gnuplot 5.0 wird
range [0:1] reverse statt
range [1:0] verwendet.
Dies betrifft die diversen Pyramiden-Anzeigen.
Bei Thematischer Karte
Text [1,-3,-2,-4] Merkmalsnummerwird Merkmal 1 (positiv) als Text, und die negativen Merkmale 3, 2, 4 als tooltip ausgegeben
#[bugs:#1587] 30.03.2015 gnuplot 5 has problems with 'grid' + 'gif animate'
# fixed in 5.1
set term gif animate delay 200 loop 0
set grid
set output 'bug.gif'
do for [i = 0:5] {
plot sin(x+i)
}
Visualisierung/Pyramiden/Einzelpyramiden Option
- kein grid
- grid
- Perzentilegrid
- Bilanzkurve
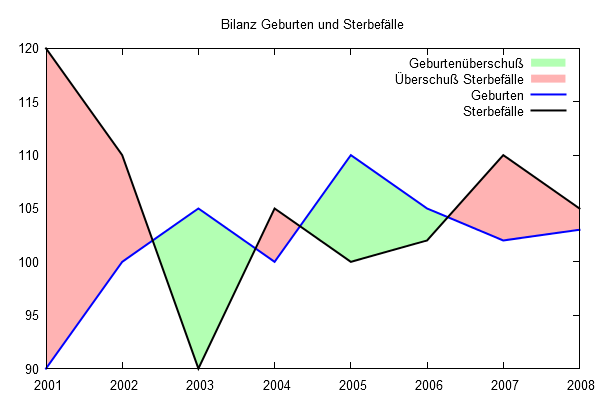
Hauptmaske/Extras/Eigene Scripts/Start- bilanz_bewegung.pl
- z.B. Geburten, Sterbefälle, Überschuß Geburten/Sterbefälle
wenn man die Datei editiert, kann man mit weiteren Bilanzen experimentieren
Hauptmaske/Visualisierung/Zeitreihen/X/Y-Plot
Auswahl bewgemagg.csv
führt ebenfalls zu obiger BilanzkurveBei der Prognose kann man im Reiter
Ausgabe Differenzierung Ausgabedateien [ 2] Gebiet
die Differenzierung der Datei bewgemagg.csv und der Bilanzkurven festlegen. - Kacheldiagramm mit Google Charts
- Visualisierung Ausgangsbevölkerung und Änderung der Bevölkerung
für Prognosen mit sehr vielen Gebieten (z.B. 10000) und vielen
Typen oder Aggregaten (z.B. 100):
Hauptmaske/Visualisierung/Zeitreihen/Kacheldiagramm (experimentell) oder
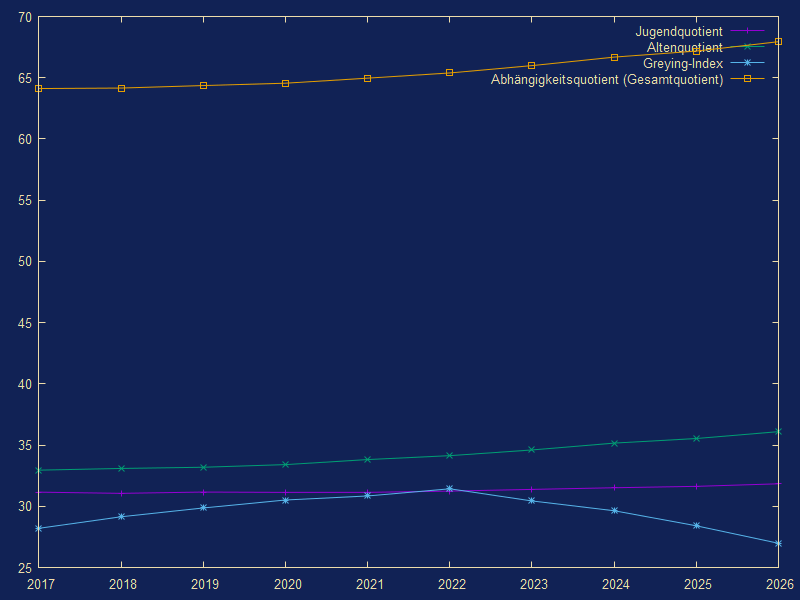
Hauptmaske/Extras/Eigene Scripts/Start/treemap.pl - Beispiel aus Anwenderorientiertem Handbuch mit Altenquotient (AQ) als Farbe Prognose08_01
- Ein 4-stufiges Kacheldiagramm
(Deutschland, Bundesland, Kreis, Gemeinde) nach dem amtlichen Gemeindeschlüssel AGS
mit beliebigem Attribut für Kachelgröße und -farbe
Hauptmaske/Extras/Eigene Scripts/Start/treemap_csv.pl
Der Benutzer erstellt eine csv-Datei nach folgendem SchemaS ;V ;G ;F ;Kommentar UG ; ; ; ;Untersuchunsgebiet ohne Vaterknoten 1 ;UG; ; ;Aggregat 1 unter UG 2 ;UG; ; ; 11 ;1 ; ; ;11 unter 1 12 ;1 ; ; ; 21 ;2 ; ; ; 25 ;2 ; ; ; 111;11;70;-5;111 unter 11 mit 70 Kachelgröße und -5 Kachelfarbe 112;11;60; 7; 121;12;40; 3; 122;12;50;-8; 214;21;30; 6; 217;21;65; 9; 252;25;75;-2; 253;25;20; 4;
Legende
Die Aggregate haben keine Werte für Größe und Farbe, weil diese über die zugehörigen Gebiete aggregiert werden.S numerischer oder alphanumerischer Schlüssel für Gebiet oder Aggregat V Schlüssel für zugehöriges Aggregat (Vater) G Attribut für Kachelgröße F Attribut für Kachelfarbe
- Visualisierung Ausgangsbevölkerung und Änderung der Bevölkerung
für Prognosen mit sehr vielen Gebieten (z.B. 10000) und vielen
Typen oder Aggregaten (z.B. 100):
- Blasendiagramm
auf Basis mit Google Charts
mit Koorelation dreier Indikatoren (z.B. Geburtenrate, Lebenserwartung,
typisierte Bevölkerung)
Bedienung:
im ersten Schritt erstellt der Benutzer aus den Ergebnis-csv-Dateien des Indikator-Tools eine csv-Datei mit 5 Spalten- Gebietskennzeichen
- Indikator 1
- Indikator 2
- Typ/Aggregatsschlüssel
- Indikator 3
Hauptmaske/Extras/Eigene Scripts/Start/bubble_chart.pl
Auswahl Eingabe-/Ausgabedatei - Liniendiagramm
kann aufgerufen werden in Befehle nach der Prognose:
call qw(linechart.pl zr_gem);
- Tooltips
Bei Einzelpyramiden könnte man bei jedem "Maus über Balkenende" einen Tooltip "BG 1, GG 2; 423.5" einblenden.
Dies würde bei den Terminal-Typen windows, wxt, qt, svg, canvas funktionieren.plot '-' using 1:2:3 with labels hypertext point pt -1 251.41234 0.5 "Altersgruppe 0\n229.23" ...
Im Rahmen einer Anwenderunterstützung wurde bei der Berechnung Raten aus Bestand und Bewegung Prüfungen auf fehlerhafte Eingabedaten erweitert und bei Anpassung Fruchtbarkeitsraten an Ziel-TFR die Möglichkeit durch einen Faktor
$c->()
Altergruppen von der Anpassung auszuschließen,
und durch die Formel $f->($y/12)
die Geburtenraten der Mütter jährlich um 1/12 Jahr zu verschieben, ergänzt,
sowie die Online-Hilfe (incl. Sterberaten nach Vorgabe Lebenserwartung)
überarbeitet.
Hadwiger-Funktion
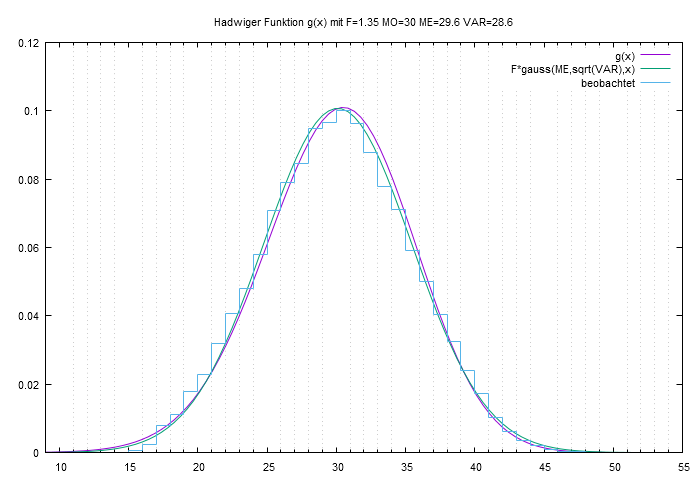
Auf Vorschlag von Herrn Hanika wird die Hadwiger-Funktion genutzt
- Gewinnung Gesamtfertilität F, Modal- MODE, Mittelwert MEAN und Varianz VAR aus fruc-Datei
- Extrapolation obiger Kennzahlen für die Prognosejahre
- Berechnung der Geburtenrate einer Altersgruppe für die Prognose mit der Hadwiger-Funktion mit den exptrapolierten Parametern
- visualisieren:
eine fruc-Datei lesen, und pro Typ, Bevölkerungsgruppe eine Pyramide der Eingangsdaten, eine Hadwiger-Kurve mit den Kennwerten F, MO, ME, VAR zeichnen (ähnlich Bild oben) - Hadwiger-Parameter berechnen
fruc2001.csv, fruc2002.csv, ..., fruc2010.csv lesen und Hadwiger-Parameter ausgeben:hadwiger_analyse.csv: #Jhr;T:B;F ;MODE;MEAN;VAR (T=Typ Geburtenrate B=Bevölkerungsgruppe) 2001;1;1;1,1535;29,5;29,8;25,9264 2001;1;2;1,5731;27,5;28,1;30,8067 ... 2010;1;1;1,1351;31,4;31,6;26,3242 2010;1;2;1,1535;28,1;28,5;25,9264
- mit dem vorhandenen Tool Eingabdaten/Dynamisieren/Extrapolieren Überlegungen zur Fortschreibung der Hadwiger-Parameter anstellen
- Hadwiger-Parameter in fruc-Dateien umsetzten:
- mit Tool Hadwiger-Synthese:
Erstellung einer Datei für zukünftige Hadwiger-Parameter durch den Benutzer:hadwiger_syynthese.csv: #Jhr;T:B;F ;MODE;MEAN;VAR (T=Typ Geburtenrate B=Bevölkerungsgruppe) 2011;1;1;1,1366;31,5;31,8;26,9264 2011;1;2;1,5731;27,5;28,1;25,8067 ... 2029;1;1;1,1451;32,4;32,9;29,3242 2029;1;2;1,1515;29,7;29,9;25,9264
Berechnung Ausgabedateien fruc2011.csv, ..., fruc2029.csv durch das Tool.
- durch direkte Eingabe in eine fruc-Datei (siehe sikurs/beispiel/beisp_1/Hadwiger_Weibull.ini):
fruc2019.csv: #tyg;bg; ag ;Hadwiger ag F MO ME VAR 1; 1;0..98;hadwiger($3 1,28 32,9 31,7 30,7) 1; 2;0..98;hadwiger($3 1,42 30,4 29,1 28,6) ...
Die Funktionhadwigerberechnet die Fruchtbarkeit in der Mitte der vorgegebenen Altergruppe.
Wenn man will, kann man in einer einzigen fruc-Datei die Entwicklung der Hadwiger-Parameter über die Zeit vorgeben, z.B.- der Modalwert MODE von 29 im Jahr 2019 steige jedes Pronosejahr um einen Monat
- der Mittelwert MEAN sei immer ein Jahr wengier als der Modalwert
- die Gesamtfruchtbarkeit F von 1,2 falle pro Jahr um 0,01
- die Varianz 36 bleibe konstant
fruc2019.csv: #! list(1) #! let($MO (29 + ($JAHR - 2019)/12)) #! let($ME ($MO - 1)) #! let($F (1,2 - ($JAHR - 2019)/100)) 1..$NTYG;1..$NBG;12..54;hadwiger($3 $F $MO $ME 36)
Nach der Prognose findet man im Versions-Unterverzeichnis die expandierte fruc-Datei.
- mit Tool Hadwiger-Synthese:
Vorteile der Hadwiger-Funktion
- die Reduktion der Fruchtbarkeitspyramide auf 4 Parameter
(schiefe Gauss-Kurve)
entspricht einer "intelligenten" Glättung.
- die 4 Parameter kann man versuchen in die Zukunft zu extrapolieren
- durch (lineare) Regression aus historischen Daten
- durch Annahmen (neue Familienpolitik bewirkt ...)
- Eine fruc-Datei kann ein oder mehrere Nebengipfel besitzen:
- vielleicht ist die Hadwiger-Funktion nur ein Modell erster Ordnung und ein verfeinertes Modell hat mehr als 4 Parameter
- Die Stichprobe besteht aus 2 oder mehreren Bevölkerungs-Untertypen
mit unterschiedlichen Hadwigerfunktionen
Dann gäbe es prinzipiell folgedene Möglichkeiten- man versucht die Parameter mehrerer Hadwigerfunktionen zu
bestimmen und rechnet die Prognose mit einer Überlagerung
dieser Hadwigerfunktionen (1.65=1.35+0.30 ist die Gesamtfertilität,
0.30/1.65 ist der Anteil dee Bevölkerung des kleineren Untertyps
an der Gesamtbevölkerung)
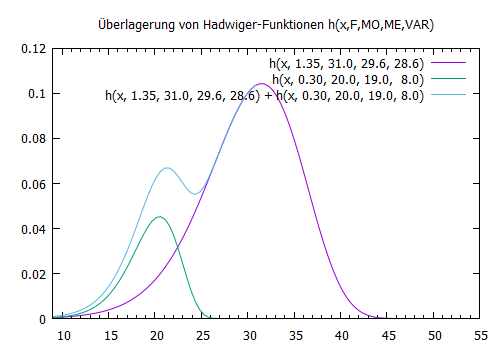
(extra/DOKU/Hadwiger/plot2.txt) - Man trennt diese Bevölkerungsuntertypen bei der Aggregation aus dem Statiskdatensatz (varausgesetzt der Statiskdatensatz enthält die dafür notwendigen Attribute) und behandelt diese in der SIKURS Prognose als unterschiedliche Bevölkerungsgruppen mit jeweils eigener Hadwiger-Funktion
- man versucht die Parameter mehrerer Hadwigerfunktionen zu
bestimmen und rechnet die Prognose mit einer Überlagerung
dieser Hadwigerfunktionen (1.65=1.35+0.30 ist die Gesamtfertilität,
0.30/1.65 ist der Anteil dee Bevölkerung des kleineren Untertyps
an der Gesamtbevölkerung)
- die Formel funktioniert bei MODE == MEAN
(und weiteren Parameterkombiationen)
nicht, da bei der Berechnung von c eine Null im Nenner entsteht
(in diesem Fall wird statt der Hadwiger-Funktion die Gauss-Funktion
mit 3 Parametern
Rate=F*gauss(MEAN,sqrt(VAR),x)verwendet)
Weibull-Verteilung
Analog zur Hadwiger-Funktion für Geburtenraten wurde für die Modellierung
von Sterberaten je ein Demonstrator für die Weibull-Funktion bereitgestellt.
(Hauptmaske/Extras/Eigene Scripts/Start/weibull.pl)
Dabei gliedert man das Leben in 3 Phasen
- frühe Lebensjahre mit fallenden Werten Sterberaten
- mittlere Lebensjahre mit konstanten zufallsbedingten (Unfall, Krankheit, ...) Todesfällen
- späte Lebenjahre mit steigenden Sterberaten
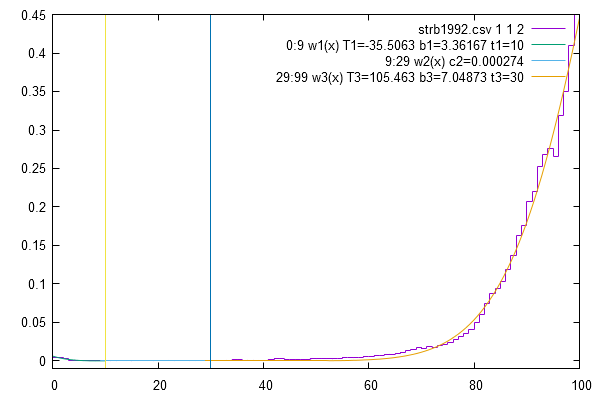
Anschließened kann man Parameter für die Zukunft ableiten und
- Mit Weibull-Synthese strb-Dateien erzeugen
- strb-Dateien vorgeben (siehe sikurs/beispiel/beisp_1/Hadwiger_Weibull.ini), z.B.
strb2019.csv: #tys;bg;gg;ag ;Sterberate 1; 1; 1; 0.. 4;weibull($4 (-235) 1,35 5) # frühe 1; 1; 1; 5..39;0,001 # mittlere 1; 1; 1;40..99;weibull($4 104 5 30) # späte Lebensjahre ...
Für die mittleren Lebensjahre kann man auch - eine Konstante mit zusätzlichem "Führerschein-peak"
1; 1; 1; 5..39;0.001 + 0,005*gauss($4 19 0,7)
- eine (oder mehrere) Gerade vorgeben
1; 1; 1; 5..39;line2p(5 0,001 39 0,002) # mittlere
Modellierung der Sterberaten nach Gompertz
SIKURS-Hauptmaske/Extras/Eigene Scripts/Start/gompertz.pl
und Ausgabe G (Gomperts Koefizient), S30 (Sterberate AG 30),
MRDT(mean rate doubling time) nach Gompertz im
Prognoseprotokoll bei
Prognose/Berechnen/Notiz
!option($MRDT 1)
Das Gomperts-Modell mit MRDT (mortality rate doubling time) für Altesgruppen ab 30 ist anschaulicher als die Weibull-Kurve dieser Altersgruppen.
Gomperz und Weibull Beide eignen sich für Modellrechnungen mit exptrapolierten Parametern aus der Vergangeheit und evtl. Annahmen für die Entwicklung der Sterberaten in den Lebensphasen
- früh: bessere Geburtsbegleitung, ...
- mittel: autonome Autos reduziert Anzahl Verkehrstote, ...
- spät: medizinischer Durchbruch bei Krebs, Alzheimer, etc. verlängert Lebenserwartung (oder Fettleibigkeit und Bewegungsmangel reduziert diese)
- Zugriff auf Gompertz-Funktion ähnlich wie Hadwiger-Funktion über
SIKURS-Hauptmaske/Berechnen/SIKURS-Sterberaten mit Gompertz-Funktion - Erweiterung Indikatoren/Prognose um Gomperz-Parameter S30, G, MRDT, und evtl. Gomperz-Graphik
- Berechnung MRDT im Prognoseprotokoll zur Prüfung, ob MRDT für
demographische Gruppen ausserhalb [8 .. 9] Jahre liegt.
Hauptmaske/Prognose/Berechnen/Notiz
!option($MRDT 1)
[ 1 ] Anzahl Bevölkerungsgruppen in GEM und DSGR (bei DSGR ohne FWBB)... in hhprog.htm steht:
Bei Option HHProg/Prognose
[v] Umrechnung HW zu Wohnberechtigte (FWBB)müssen gem, dsga, dsgr nach Bevölkerungsgruppe (BG) differenziert sein.
Wenn sie in der HHPROG-Startmaske obiges Häkchen setzen, dann wird das Eingabefeld
[ 1 ] Anzahl Bevölkerungsgruppem in GEM und DSGR (bei DSGR ohne FWBB)ignoriert und immer von 2 BG ausgegangen.
Insgesamt macht das Programm bei der Prognose folgende Fallunterscheidungen
wenn Option FWBB
GEM mit BG einlesen
Warnung wenn Summe von BG2 = 0
GEM * FWBB
wenn Option DSGA
DSGA mit BG einlesen und von GEM abziehen
wenn Option DSGR
DSGR mit BG einlesen und Quote von GEM abziehen
GEM über BG auf B1 hochaggregieren
sonst (ohne FWBB)
wenn Option DSGA
GEM über BG aggregiernd als B1 einlesen
DSGA über BG aggregierend einlesen und von B1 abziehen
wenn Option DSGR
GEM mit Differenziereung (Option NBG aus Maske) einlesen
Prüfen, ob option->NBG plausibel (hier ist ein Fehler im Programm, den ich behoben habe)
DSGR mit Differenzierung Option NBG einlesen und Quote von GEM abziehen
Lindemann: Wenn Sie zwei Dateien ausgeben, dann könnten Sie auch eine Datei wie bisher (GKZ;BG;GG;AG) ausgeben und eine weitere, in der BG nicht differenziert wird. Das Programm sollte an gemxx erkennen, welche fwbb es bei der Haushalteprognose verarbeiten muss.
wib: Ich würde aber aus 2 Gründen meine Lösung vorziehen:
- Ich muss vor dem Lesen der gem-Datei wissen, ob sie 1 oder 2 BG hat, sonst müsste ich die Datei zweimal lesen (erst probelesen mit zählen der BG, dann richtig lesen)
- Ich gebe die gleiche Information nur ungern zweimal aus (einmal nach BG differenziert, dann über BG aggregiert) weil redundante Information in der Weiterverarbeitung leicht zu Fehlern führen kann. Im April treffe ich die Damen und Herren aus cc mit der Gelegenheit darüber zu sprechen.
Lenkungsgruppe:
Die Oberflächen des Quoten- und Prognoselaufes sollen optimiert werden. Beim Prognoselauf kann gewählt werden, ob "demografische Sondergruppen" berücksichtigt werden sollen. Dieser Begriff und der Dateiname (DSGA/DSGR) kommt aus SIKURS und beinhaltet die Anstaltsbevölkerung, bzw. die Bevölkerung in Heimen. In HHPROG ist dieser Begriff nicht verwendbar, denn hier sind mit diesen "Sondergruppen" die "Personen ohne eigene Haushaltsführung" gemeint. Die Bezeichnung DSGA/DSGR soll ersetzt werden durch HDSGA/HDSGR. Die Personengruppe dieser Datei kann schon im Quotenlauf abgeleitet werden (wib: wie?), die Option kann dann unter "Laufzeitparameter-Prognose" entfallen (wib: stattdessen Laufzeitparameter-Quoten [v] HDSGA ableiten ?).
Im Menü "Laufzeitparameter - Quote" gibt es aktuell die Option "Filter W01 ungleich1"; diese Option muss eigentlich immer gelten und sollte deshalb als Voreinstellung übernommen werden (fertig).
Bei Haushalteprognosen gab es in der Vergangenheit fehlerhafte Ergebnisse bei Berechnungen mit dem "Faktor Wohnberechtigte" (FWBB), der mit dem Quotenlauf ermittelt wird. Der Datensatz aus HHGen ist nach 2 Bevölkerungsgruppen aufgebaut. HHProg geht davon aus, dass immer mit 2 Bevölkerungsgruppen gerechnet wird. Sollte im Prognoselauf ein Bevölkerungsbestand mit einer Bevölkerungsgruppe eingelesen werden, soll das Programm die Unstimmigkeit ignorieren und die ermittelten Quoten anpassen.
Herr Hahn hat für Köln eine Ex-Post Prognose durchgeführt und die Ergebnisse aus der Haushalteprognose mit den Ergebnissen aus HHGen verglichen und dabei er-hebliche Differenzen festgestellt. Her Lindemann und Frau Lux-Henseler haben Probeläufe mit Nürnberger, bzw. Stuttgarter Zahlen gerechnet, hier gab es auch Differenzen, aber in einem verträglichem Ausmaß. Herr Hahn wird mit der neuesten Version noch Testläufe durchführen; sollten wieder große Differenzen auftreten, müssen weitere Prüfungen stattfinden und die Ergebnisse an die pth weitergegeben werden.
- Quotenberechnung
dstbest Sätze mit A01 ? 102 wurden bei den Klassifikationen SPEAZ etc. nicht in die oberste Altersgruppe einsortiert, weil die Grenze füe "Alte" 65-99 statt 65-999 (A01 haqt 3 Stellen, also theoretisch 0-999) war. - Prognose
Verarbeitung von gem-Dateien mit mehr als 99 Altersgruppen.
Die Altersgruppe 102 wird auf 99 aufaddiert.
Eine Vorgabe der gewünschten Anzahl Altersgruppen (z.B. 105) wäre machbar, es müßte aber geklärt werden, wie man folgenden Fall behandelt:
gem hat Altersgruppen 0 .. 99, und man gibt 105 Altersgruppen vor:
Bedeutet AG 99
- 99 Jahre und älter ?
- die 99-jährigen; es gibt aber keine älteren Personen ?Schlüsselfeld Datensatz bei Warnungen im Protokoll:
Wenn Sie bei der Anlistung im Protokoll die ersten 23 Stellen am Stück, einschließlich eventueller Leerzeichen ausgeben würden, könnte man diesen String direkt in das Suchfenster von EwoPEaK kopieren und suchen. Ich musste hier erst zwischen 160 und 0012 erst ein weiteres blank ergänzen, damit die Suche funktioniert hat.0811100020980 160 0012
(html frißt Mehrfachblanks, kann sie aber mit schützen)
verbesserte Behandlung Satzlänge 271 verbesserte Haushalte/Anzeige/Start (insbesondere Histogramm):
[1-* ] Auswahl Satznummern [ ] Ausgabe in Tabelle [ ] Ausgabe csv [v] Histogramm
Umstellung von XHTML 1.0 auf HTML5 bei SIKURS, HHPROG und Tools
Sikurs ist in 2 Programmiersprachen programmiert:
- C++ (Bevölkerungsprognose, Haushalteprognose, Makrodateien aus Statistikdatensatz, Ausgabe shape-files, ADETON-Methode)
- Perl 5 (GUI, diverse Tools)
Das Perl Dev Kit (PDK) wurde abgekündigt.
Es gibt grob folgende Alternativen die Probleme mit Perl 5 zu lösen:- Kein neues SIKURS-Release erstellen und Lösung auf Nachfolger Systemexperten verschieben
- Perl-Anteil nach z.B. C++, C#, F#, Java, Python, Mojo, Julia, R ... portieren
- Perl + C++ nach z.B. Java, C# oder F# portieren
Probleme mit Perl 5
Die Benutzeroberfläche und einige Tools sind in Perl 5 geschrieben.Die Perl-Quellen werden mit "ActiveState PerlApp" in die Datei "sikurs32.exe" bzw. "sikurs64.exe" umgewandelt.
Die Lizenz für ActiveState Perl Dev Kit (PDK) Is Now End Of Life.
Es gibt folgende Alternativen:
- ActivePerl 5.22 weiter verwenden und kein upgrade auf 5.24, ...
Lizenz PDK endet - ActiveState Platform erwerben
Verfahren für Anwender vermutlich nicht zumutbar - Perl2Exe
zum Packen verwenden (scheint nicht zu funktionieren)
Perl2Exe mit 30 Tage evaluation time - wechseln zu
Strawberry-Perl 5.30 64-Bit
Alternatives perl, da PerlApp ab perl.5.24 nicht mehr unterstützt wird.
Probleme:
Tkx läuft nur unter ActiveState perl
cpanm Tk(mit Tk::Balloon statt tooltip) geht, aber Umstellung von Tkx auf Tk aufwändig
(siehe.../sikurs/extra/source/scripts/tkmain.pl)
Umstellung in Stufen- Berechnen/Makrodateien
Einwohner alles
Haushalte/Quoten+Prognose - Berechnen/SIKURS Eingabedaten aus Makrodateien
- Weiter Tools nach Priorität
- für einige Tools (Cluster, Glätten, Dynamisieren, Visualisieren) auf R verweisen
cpanm Bundle::libwin32 ( oder Win32::(Mutex, )Shortcut, Sound ) Statisitcs::Descriptive Number::Format Algorithm::Cluster ...Umwandeln in exe:cpanm PAR::Packer pp -M MSWin32 --gui -C -f Bleach -o ../../sikurs64.exe sikurs.pl
- Berechnen/Makrodateien
- Ausliefern der SIKURS-Quellen
(evtl. mit Perl Obfuscator)
hoher Aufwand Systemadministration beim Nutzer, da Perl und einige Pakete zu installieren sind
Die Rolle von Perl 5 in SIKURS
- Benutzeroberfläche
Die Benutzeroberfläche basiert auf dem Perl 5 Paket Tkx, einer Perl-Schnittstelle zu Tcl/Tk.
Es gibt eine Schnittstelle C++/Tk, die jedoch sehr experimentell und Linux-lastig ist.
Die Benutzeroberfläche von SIKURS ist sehr konventionell (Fenster, Menüs, Button, Eingabefelder, ...) und sollte man mit vielen GUI-Werkzeugen nachbilden könnten, nur Manuelles Glätten benötigt interaktive 2D-Graphik. - Die Clusteranalyse basiert auf dem Perl Modul Algorithm-Cluster von dem es Python und C-Varianten gibt.
- Einwohner/Prognose/Berechnen/Befehle und Extras/Eigene Scripts machen den Perl-Interpreter für den Anwender verfügbar, Lua könnte eine mögliche Alternative sein.
Alternativen für Perl 5
Liste 1 2 von GUI Bibliotheken- Perl 7
- python isr die führende
Scriptsprache im Bereich Data science / big data.
GUI, jupyter, pandas werden unterstützt - Julia is aktraktiv weil:
- Tk GUI Bibliothek
- jupyter
- Cluster-Bibliothek
- schnell
- man kann executable erzeugen
- prozesse starten
- Matrizen verarbeiten (ähnlich Perl/PDL, python/numpy)
- Graphiken ausgeben (Ersatz für gnuplot)
- Package Compiler
- R Statistikpaket
- gwidgets-gui
- jupyter
- Eine Gruppe Anwender hat SIKURS-Auswertungen mit RStudio und Plotly entwickelt und stellt dies interessierten Anwendern zur Verfügung
- Raku (Perl 6), Python, Mojo, Ruby - kein großer Vorteil gegenüber Perl 5
- C#
- UWP - noch nicht untersucht
- Windows Forms - überholt
- WPF/XAML - gute Windows-spezifische GUI
- C++
- WinUI 3 (interessant aber noch nicht getestet)
- wxWidgets Cross-Platform GUI Library
- WebAssembly
- wt C++ Anwendung mit integriertem Webserver.
- Qt - altmodisches Nokia Monster?
- Nana - elegant aber stabil ?
- IUP (auch C, Lua, Perl 6)
- .Net/XAML
- MFC uralt
- WTL aktiv gepflegt ?
- UWP - nur für Windows Store ?
- cpptk - genialer Linux-hack ?
- Java/JavaFX/FXML, Scala/ScalaFX, Kotlin
noch nicht untersucht - html, css, javascript:
Eine html5-Maske für z.B. Glätten oder Prognose würde dann das von Perl zu portierende Glätten oder die in C++ programmierte Prognose über einen schlanken Webserver aufrufen, welche wiederum eine html-Ausgabe (wie jetzt schon das Prognoseprotokoll) erzeugen würde.
Dies wäre eine einfache, klare und plattformunabhängige Architektur
oder electron - Progressive Web Apps (PWA)
- Electron oder sciter Plattformübergreifende Desktop-Anwendungen mit JavaScript, HTML und CSS entwickeln
- jupyter JupyterLab/Notebook sind
interaktive Arbeitsumgebungen für Julia, Python, Mojo, R und andere
Programmiersprachen.
Die C++-Anteile (Bevölkerungsprognose, Haushalteprognose, ...) müsste man als Kommandos zur Verfügung stellen, auf viele Perl-Tools könnte man verzichten, das Funtionen wie Statistik, Cluster, Visualisierung in Julia, Python, Mojo und R angeboten werden. - EPB The Executable Book Project
Um mit endlichem Aufwand eine SIKURS-Version erstellen zu können, wurde für eine 64-Bit-Version folgendes portiert:
| Thema | von | nach |
|---|---|---|
| Perl 5 | Activestate 5.22 | Strawberry 5.30 |
| Packer | PerlApp | pp |
| GUI | Tkx | Tk |
| Algorithm-Cluster | 1.54 | 1.59 |
| datadict_xx | xml | csv |
Bei der Bevölkerungsprognose, hhprog und vielen Tools können Verknüpfungen "fruc2013.lnk" statt "fruc2013.csv" eingesetzt werden.
Neue Namenskonvention "fruc2013.csv.lnk", da intuitiver und besser mit der Anzeige der Dateien im file explorer geeignet.
Wenn das Programm einen Link mit alter Namenskonvention findet, gibt es eine Warnung aus und fragt den Benutzer, ob die Datei umbenannt werden soll.
ahk: Die Nummerierung ist durch das Herausnehmen von bearbeiteten Punkten, die vielen Ebenen der Gliederung und die inhaltlichen Anmerkungen/Anregungen aus der Lenkungsgruppe für uns sehr unübersichtlich geworden. Zudem haben wir Bedenken, dass andere Personen (z.B. Mitglieder der Lenkungsgruppe und auch die Kassenprüfer ) mit dem Dokument überfordert sind und möchten Sie deshalb darum bitten, die Gliederung zu überarbeiten oder ggf. zu ergänzen.
Die Anregungen und Vorschläge, die in der Roadmap festgehalten werden, sind sicher sehr hilfreich, vielleicht wäre eine Zweiteilung die Lösung. Wir könnten uns z.B. gut eine Excel-Datei vorstellen, in der die bearbeiteten und offenen Punkte kategorisiert werden, ähnlich den Tabellenblättern wie wir sie früher erstellt hatten (siehe Anhang). Damit ließen sich einzelnen Punkte je nach Bearbeitungsstatus in der Übersichtsliste filtern.
Da Herr Dr. Tüllmann unabhängig von mir in Berlin arbeitet, ist es vorteilhaft, wenn jeder seine eigene Liste pflegt, d.h. je eine Liste Methodenexperte und Systemexperte
Erledigte Punkte werden nach done.htm ausgelagert
Überlegungen zu einer Cloud-Lösung ohne lokale PC-Installation, z.B. für Testzwecke oder kleine Gemeinden.
Voraussetzung ist ein Web-Server, der CGI-Perl-scripts (oder besser PSGI/Plack (brauschober/cgi-bin/psgi)) unterstützt. Die ist z.B. bei www.strato.de ab PowerWeb Starter für ca. 3 Euro pro Monat der Fall.
Der Benutzer stellt seine Eingabdateien in einem Verzeichnis zusammen, packt diese z.B. als "miesbach.zip", lädt diese Zip-Datei hoch, und bekommt eine Zip-Datei "sikurs.zip" mit den Ergebnissen zurück auf seinen PC.
Weiter Server-Lösungen sind zu untersuchen (z.B. Windows Server, Citrix-Server, Azure, AWS)- Visual Studio 2013
- Perl 5.20
- gnuplot 5.0
- Algorithm::Cluster 1.52
mail 21.10.2013 Frank Hahn:
- neuer Indikator SPPmm, Quote Q26, Faktor ZPP1a/ZPP1b für die Berücksichtigung gleichgeschlechtlicher Partner ohn Kind zur besseren Prognose von Personen und Haushalten
- Optionnale Ausgabedatei dstbest.csv zum Nachrechnen der Quotenberechnung mit Excel (bei nicht zu großer Eingabedatei dstbest.txt)
- Berechnen Statistikdatensatz dstbest/dstbew
A01 - streichen, Z01 Verarbeitungsdatum (default), Z02 Ereignisdatum
R01 Gemeindeschlüssel, R02 kleinräumige Gliederung
NEUB (1 .. 9) wird als Neubautyp in die Datei neubaubezug_jjjj.csv aufgenommen. ANSTI/E (1 .. 9) wird als Anstaltstyp ind dsg_jjjj.csv aufgenommen.
Das Programm fragt nicht mehr nach dem Verzeichnis sondern nach der Datei dstbest/dstbew. Dadurch können mehrere Dateien, z.B. dstbest2012.txt, dstbest2013.txt in einem Eingabeverzeichnis sein.
Die Datei dstbest/dstbew wird erst nach der Parametermaske abgefragt. - Vereinfachung Linzenzanforderung:
Wenn ein Anwender SIKURS installiert hat, dann soll er SIKURS starten, dann steht in der Hauptmaske wie er den Lizenzschlüssel bekommt (er braucht keine Prognose zu starten).
Im Menu ?/Info wird zusätzlich eine ungültige Lizenz angezeigt - Die Fehlermeldung "TkReport.pm Line 346" wurde durch eine bessere Meldung ersetzt.
- SIKURS Eingabedaten berechnen
Berechnung von aller Quoten (z.B ZUDQ) geht auch ohne das Vorhandensein einer Bestandsdatei. - Eingabedaten liegen in einem Verzeichnis mit Schreibschutz
Überarbeitung der Fehlermeldungen, wenn Ausgabedatei oder Ausgabeverzeichnis nicht erstellt werden kann. - Anzeige Thematische Karte
- Fehlerkorrekturen, wenn Merkmale aus csv-Datei statt dbf-Datei gelesen werden.
- Bei Tortendiagramm, kann die größe der Torte durch ein Merkmal gesteuert werden (Beispiel: z.B. Größe der Torte nach Einwohnerzahl, Aufteilung Tortenstücke nach Alter (jung, erwerbstätig, alt)
- Gedächtnis für Maskeneingaben
- Möglichkeit Gebieten direkt aus einer Merkmalsspalte Farben zuzuordnen (z.B. Farben für Wahlsieger: schwarz, rot, grün gelb, ...)
- Möglichkeit die dbf-Merkmalsdatei als csv-Datei zu exportieren
G Zielwert für Geburten G0 kein Zielwert G1 global G2 nach Gebietseinheiten differenziert mit Datei: eckgebg.csv: #Jahr;GKZ;Geburten 2010;101;345 ... 2020;834;120 S Zielwert Sterbefälle S0 kein S1 global S2 nach Gebietseinheiten differenziert mit Datei: eckstrbg.csv: #Jahr;GKZ;Sterbefälle 2010;101;320 ... 2020;834;130Wenn bei G2/S2 für ein Gebiet kein Eckwert vorgegeben wird, so bdeutet die nicht Eckwert 0, sondern für dieses Gebiet wird nach der Berechnung der Geburten/Sterbefälle keine Anpassung an einen Eckwert vorgenommen
Bei P1 (Zielwerte eckgem für Gebiete) bedeutet ein fehlender Zielwert auch nicht mehr Zielwert 0, sondern den Ausschluß dieses Gebietes von der Anpassung.
Baustein Vorgabe Zuzug K6 und Vorgabe Wegzug C6 ausdifferenziert nach Gebiet, Außentyp, Bevölkerungsgruppe, Geschlechtsgruppe, Altersgruppe (wie gem * NTYA) und der Möglichkeit analog zu K6/ZUVL Abkürzungen mit Quoten (z.B. für Altersgruppen) zu definieren.
Für ZUVGjjjj kann die Makrodatei aussenzuzug_jjjj, für WEGVjjjj aussenwegzug_jjjj verwendet werden.
Es muss noch festgelegt werden, für welche Bausteinkombinationen C6 und K6 benötigt werden, um dann das Programm evtl. zu erweitern und/oder Kombinationen im Methodenassitenten auszuschließen.
siehe
.../sikurs/beispiel/baustein/C6K6.ini
(Beispiel Herr Schöfer)
SIKURS wurde für 100 Altersgruppen (0, 1, 2,..., 99 und älter) konzipiert.
Diese Einschränkung wurde wegen steigender Lebenserwartung nach und nach aufgeweicht, so dass man z.B. mit (90, 95,) 100, 105, 110 oder 120 Altersgruppen rechnen kann.
Dies scheint isoliert für die einzelnen Werkzeuge zu funktionieren. Nützlich wäre eine Überprüfung, ob dies über die Werkzeugkette hinweg richtig funktioniert. Beipiele:
- SIKURS Eingabedaten berechnen
Vorgensweise- Berechnung Raten/Quoten aus Bestand und Bewegung mit anschließeder
Prüfung und Nachbearbeitung der Raten/Quoten
Sollte für alle Anzahlen SIKURS Altersgruppen korrekt funktionieren bis auf:
Wenn Bestands-/und Bewegungsdatei weniger (z.B. 105) als die gewünschte Anzahl Altersgruppen (z.B. 110) z.B. für strb, wie soll dann die Sterbewahrscheinlichkeit sein:... 1;1;1;105; # ? (*) 1;1;1;106; # ? (*) 1;1;1;107; # ? (*) 1;1;1;108; # ? (*) 1;1;1;109; # ? (*)
(*) hier müsste man einen geschätzten Defaultwert im Bereich 0,2 - 0,5 finden
ähnliches gilt für die diversen Wanderungsraten, welchen Wert zwischen 0 und 1 soll man annehmen wenn in der Stichprobe für die Altersgruppe keine Bewegung und kein Bestand vorhanden sind.
Der Benutzer kann über eine Option den Text "undef" einzusetzten lassen, als Hinweis, dass er hier im Rahmen der Aufbereitung (Prüfen, Glätten) der Raten selbst Annahmen für die Werte machen muss - Beispiel:
Wenn bei einer Wanderugnsrate eine einzelne Altersgruppe "undef" ist, dann sollte man diese mit dem Mittelwert der Nachbargruppen besezten (ohne wie beim gleitenden Mittel den eigenen Wert als 0 anzusetzen).
Extras/Eigene Scripts/Start/undef.pl automatisiert das Ersetzten von undef.91;0,31 92;0,32 93;undef > 0,33 94;0,34 95;0,33
- Berechnung Raten/Quoten bei dünn besetzten Gebieten/Typen
Bei Bestand und Bewegung können können ganze Bevölkerungs-/Geschlechtsgruppen undefiniert sein.
Drastisches Beispiel:
Ein Neubautyp soll genau aus einem Neubaugebiet bestehen.
Das Neubaugebiet sei anfangs leer.
Bei der Berechnung der Raten wird dieser Typ leer bleiben.
Bei der Prognose wird bei den Raten die Voreinstellung 0 genommen.
Wenn sich die Bevölkerung während der Prognose durch Zugug erhöht, führen die falschen Raten zu falschen Ergebnissen.
In diesem Fall empfiehlt sich beiSIKURS Eingabedaten berechnen [1 ] undefinierte Werte
zu wählen, dann sind alle undefinierten Werte in den Raten/Quoten-Ausgabedateien mitundefmarkiert.
Der Benutzer kann dann entscheiden, ob er Ersatzwerte für diese Typen aus anderen Quellen ableiten kann, oder ob er sein Typkonzept ändert und die Anzahl Gebiete pro Typ erhöht. - Prüfung und Nachbearbeitung Bestand und Bewegung und anschließende
Berechnung Raten/Quoten solange bis Ergebnis zufriedenstellend.
Bei der Bearbeitung von Bestand und Bewegung sind 2 Fälle zu unterscheiden- Ausgleich zufälliger Schwankungen über die Altersgruppen durch Glättung
- Anpassung Anzahl Altersgruppen bei Bestand un Bewegung an die
Zielanzahl Altersgruppen der Raten/Quoten
- Bestand/Bewegung hat 100 Altersgruppen, Rate soll 105 Altersgruppen haben
Plausible Aufteilung der Altersgruppe 99 auf 99 .. 104 - Bestand/Bewegung hat 105 Altersgruppen, Rate soll 100 Altersgruppen haben
Aggregation der Altersgruppen 99 .. 104 auf 99
- Bestand/Bewegung hat 100 Altersgruppen, Rate soll 105 Altersgruppen haben
- Berechnung Raten/Quoten aus Bestand und Bewegung mit anschließeder
Prüfung und Nachbearbeitung der Raten/Quoten
- SIKURS Geburtenraten aus amtlichen Geburtenraten
Die Unter-/Obergrenze der Fruchtbarkeit muss unverändert in die Prognose übernommen werden - SIKURS Sterberaten aus amtlichen Sterbeziffern
amtliche Sterbeziffern (a[0] bis a[100])#Geschlecht;Alter;Sterbewahrscheinlichkeit 1;000;0,25273 1;001;0,06492 1;002;0,03319 ... 1;091;0,33475 1;092;0,35074 1;093;0,36689 1;094;0,38404 1;095;0,40217 1;096;0,42158 1;097;0,44259 1;098;0,46560 1;099;0,49102 1;100;0,51930
Für 100 SIKURS Altersgruppen ergibt sich daraus die korrekte? strb#Typ Sterberaten;Bevölkerungsgruppe;Geschlechtsgruppe;Altersgruppe;Rate Berechnungsformel besser 1..$NTYS;1..$NBG;1;00;0,126365 (=a[0]/2) 1..$NTYS;1..$NBG;1;01;0,158825 (=(a[0]+a[1])/2) 1..$NTYS;1..$NBG;1;02;0,049055 (=(a[1]+a[2])/2) ... 1..$NTYS;1..$NBG;1;97;0,432085 (=(a[96]+a[97])/2) 1..$NTYS;1..$NBG;1;98;0,454095 (=(a[97]+a[98])/2) 1..$NTYS;1..$NBG;1;99;0,73796 (=(a[98]+a[99]+a[100])/2) ? 0,49197 = (a[98]+a[99]+a[100])/3Für 105 SIKURS Altersgruppen ergibt sich daraus die falsche strb#Typ Sterberaten;Bevölkerungsgruppe;Geschlechtsgruppe;Altersgruppe;Rate 1..$NTYS;1..$NBG;1;000;0,126365 1..$NTYS;1..$NBG;1;001;0,158825 1..$NTYS;1..$NBG;1;002;0,049055 ... 1..$NTYS;1..$NBG;1;097;0,432085 1..$NTYS;1..$NBG;1;098;0,454095 1..$NTYS;1..$NBG;1;099;0,47831 # ? 1..$NTYS;1..$NBG;1;100;0,50516 # ? 1..$NTYS;1..$NBG;1;101;0,25965 # ? 0,51930 1..$NTYS;1..$NBG;1;102;0 # ? (**) 0,51930 1..$NTYS;1..$NBG;1;103;0 # ? (**) 0,51930 1..$NTYS;1..$NBG;1;104;0 # ? (**) 0,51930
(**) letzte vorhandene Altersgruppe aus Eingabedatei wird fortgeschrieben
Für 95 SIKURS Altersgruppen ergibt sich daraus die falsche strb#Typ Sterberaten;Bevölkerungsgruppe;Geschlechtsgruppe;Altersgruppe;Rate 1..$NTYS;1..$NBG;1;00;0,126365 1..$NTYS;1..$NBG;1;01;0,158825 1..$NTYS;1..$NBG;1;02;0,049055 ... 1..$NTYS;1..$NBG;1;92;0,342745 1..$NTYS;1..$NBG;1;93;0,358815 1..$NTYS;1..$NBG;1;94;1,746595 # ??? Rate > 1 !!! 0,375465
- Haushalteprognose
Beim Einlesen der gem-Ergebnisdatei aus der SIKURS-Prognose und der Demografischen Sondergruppen (hdsga) werden die Altersgruppen 100, 101, ... auf die Altersgruppe "99 und älter" aufaggregiert und alle folgenden Berechnungen mit 100 Altersgruppen durchgeführt.
Zu prüfen ist, ob eine Übernahme der Anzahl Altersgruppen aus der gem-Datei in die Differenzierung der HHProg-Berechnungen Vorteile bringen könnte
Bei der hhprog-Quotenberechnung wird Z02 protokolliert und in q.csv geschrieben. Bei der Haushalteprognose wird Z02 aus q.csv gelesen und protokolliert. Für die Berechnungen spielt Z02 keine Rolle.
In der Startmaske der Prognose wird
20160116: Z02 aus q.csvangezeigt.
Startjahr und Endjahr werden mit den Werten der ersten und letzten gem-Datei im Eingabdateiverzeichnis initialisiert.
Der Benutzer kann prüfen, ob Z02 zum Prognosezeitraum passt und den Prognosezeitraum für Proberechnungen einschränken
Bei der Prognose wird dann für jede gem-Datei im ausgewälten Jahrebereich ein Prognosejahr gerechnet.
Bei der Ableitung von Makrodateien aus dstbest und dstbew werden Z02/Z01 für die Ermittlung des Referenzjahres verwendet.
Wenn aber z.B. 20140117 vorkommt, so ist höchstwahrscheinlich 2013 das Referenzjahr. Um dem Anwender eine Korrekturmöglichleit zu geben und mehrere Statiskdatensätze im Eingabeverzeichnis zu erlauben, wird das Konzept für die Gewinnung der Makrodaten erweitert:
- Der neue Menüpunkt
- Eingabedaten/Berechnen/Makrodateien as Statistikdatensatz Bestand+Bewegung
- Eingabedaten/Berechnen/Statistikdatendatz dstbest
- Eingabedaten/Berechnen/Statistikdatendatz dstbew
- Eingabedaten/Berechnen/Makrodateien as Statistikdatensatz Bestand+Bewegung
- das Eingabeverzeichnis darf beliebig viele Statistdatensätze Bestand und Bewegung als Datei oder Link enthalten
- Nach Auswahl des Eingabeverzeichnisses werden alle dstbest/dstbew mit ihren Z02/Z01 für eine Plausibilitätsprüfung angelistet
- Die Namen der Bestands/Bewegungs-dateien beginnen mit dstbest/dstbew, gefolgt von beliebigen Zeichen, z.B. dstbest_erlangen_neu.txt.lnk.
- enhalten diese beliebigen Zeichen eine 4-stellge Zahl
(z.B. dstbew_2015.txt, dstbest_Hof2015_alt.txt.lnk),
so wird diese Jahreszahl statt der Jahreszahl
aus Z02/Z01 als Referenzjahr verwendet.
Dabei wird geprüft, ob sie gleich Z02/Z02 oder ein Jahr weniger ist, falls nicht wird nur eine Warnung ausgegeben.
Eine zusätzliche Nebenwirkung der Jahreszahl im Dateinamen ist, dass Records mit falschem Jahr aus Z02/Z03 verarbeitet statt ignoriert werden. Am Ende des Laufes wird eine Statistik angezeigt2013 342536 records 2014 753 records
- Die potenziell sehr vielen Makrodateien werden in ein
Unterverzeichnis makro geschrieben.
Bei der Ableitung der Makrodateien aus dstbew wird der Schlüssel W40 (3-Stellen) in reftya um W41 (8 Stellen) erweitert.
Offene Fragen bei der Ableitung Makrodateien aus dem Statistikdatensatz
- dsg.csv aus dstbest:
erste Spalte ist "Anzahl signifikante Stellen aus R02" (Lindemann)
war: wenn aus ANSTI abzuleiten ANSTI, sonst ANSTE (d.h. 0 oder 2) - neubaubezug.csv aus dstbew:
Die erste Spalte ist "NEUB: Neubautyp 1..9
richtig wäre "Anzahl signifikante Stellen aus R02" ? - Lindemann: bei den Bewegungen kann das schnell unübersichtlich werden, da es im Berichtsjahr oft 10 oder mehr Z02JJJJ geben kann. Bei den Bewegungen ist für die Auswahl des Berichtszeitraums primär Z01 wichtig. Wenn es mehr als ein Z01JJJJ gibt, kann per Automatik Z01 mit den meisten Sätzen zum maßgeblichen Z01 werden - oder der Eintrag im Dateinamen. Ich würde es nicht anlisten sondern nur eine Warnung ausgeben, wenn Z01 nicht eindeutig ist.
- Lindemann: Beim Bestand gibt es immer nur ein Z02. Wenn Z02 im Januar des Folgejahres liegt, sollte der maßgebliche 'Stichtag' des Dateiabzugs wahrscheinlich der 31.12.des Vorjahres sein. Dieses Datum sollte dann verbunden mit einer Warnung SIKURS-intern in die Makrodateien eingehen.
Verfahrensschritte für eine SIKURS-Prognose (ohne Prüfschritte)
- erstelle Verzeichnis
prog2050 - erstelle Unterverzeichnis
dstmit Links auf gewünschte Statisikdatensätze Bestand und Bewegung - Eingabedaten/Berechnen/Makrodateien aus Statistikdatensatz...
mit Unterverzeichnismakro - Eingabedaten/Berechnen/SIKURS Eingabdateien aus Makrodateien
mit Ausgabe Eingabedateien ins Unterverzeichnisraten - Einwohner/Versionsdatei/Neu
prog2050/dst/makro/raten.v.ini
Auswahl einer Bausteinkombination - Einwohner/Prognose/Berechnen
mit Ergebnis inprog2050/dst/makro/raten/v - Verknüpfung
dstbest.csv.lnkerstellen - Haushalte/Quoten/Berechnen
zqerstellen- Haushalte/Prognose/Berechnen
prog2050
+---dst
| dstbest_2010.txt.lnk -> X:\...\dstbest...
| ...
| dstbew_2014.txt.lnk -> X:\...\dstbew...
+---makro
| bestand_2010.csv
| ...
| sterb_2014.csv
+---raten
| gem2014.csv
| ...
| strb2015.csv
| v_optimist.ini
| v_pessimist.ini
+---v_optimist
| | gem2015.csv
| | ...
| | gem2024.csv
| | dstbest.txt.lnk -> X:\...\dstbest...
| | zq2015.csv
| +---Quoten
| | q.csv
| | zqa.csv
| +---Prognose
| person.csv
| haushalt.csv
| hdo2.csv
| kinder.csv
+---v_pessimist
gem2015.csv
...
gem2024.csv
Das Benutzerhandbuch (bhb.pdf) sollte nach einem Review an geeigneten Stellen
entsprechend ergänzt werden.
Für eine bessere Übersichtlichkeit wurde die Verschachtelungstiefe reduziert:
prog2050 +---dst | | dstbest_2010.txt.lnk -> X:\...\dstbest... | | ... | | dstbew_2014.txt.lnk -> X:\...\dstbew... | | reftya.csv <....: +---makro : | | bestand_2010.csv : | | ... : | | sterb_2014.csv : | | reftya_roh.csv ....: | | reftyp_roh.csv ..... +---bprog : | | reftyp.csv <....: | | gem2014.csv | | ... | | strb2015.csv | | optimist.ini | | pessimist.ini | +---optimist | | | gem2015.csv | | | ... | | | gem2024.csv | | | dstbest.txt.lnk -> X:\...\dstbest... | | | zq2015.csv | | +---HHQuoten | | | | q.csv | | | | zqa.csv | | +---HHPrognose | | | | person.csv | | | | haushalt.csv | | | | hdo2.csv | | | | kinder.csv | +---pessimist | | | gem2015.csv | | | ... | | | gem2024.csvDie Idee ist, dass das Prognoseverzeichnis prog2050 Unterverzeichnisse für das SIKURS-Programm und den Anwender einhält, z.B.
prog2050 +---dst +---makro +---bprog +---Auftrag +---Korrespondenz +---Veröffentlichung
- W40/W41
Neues Feld in der Eingabemaske Eingabedaten/Berechnen/Makrodateien aus dstbew
für den Schlüssel der Datei reftya.csv
[ 5] Anzahl signifikante Stelle W40/W41
W40 Gebietsschlüssel für Herkunftsquell-/Wegzugsziel-Gebiet (3 Stellen)
W41 Amtlicher Gemeindeschlüssel (AGS) (8 Stellen)
Bei Eingabe von 0 bis 11 wird diese Anzahl Stellen ab W40 ausgewählt - R02/R02U2 bei
- Makrodateien aus dstbest/dstbew
- Quotenberechnung HHProg
Das gleiche gilt für RQZ/RQZU2 für die Berechnung der Binnenwanderungsmatrix.
Erweiterung der Eingabemöglichkeiten für das Feld[ ] Anzahl signifikante Stellen R02 folgendes ist kompliziert zu parsen und macht glauben, man könnte alle Felder ansprechen: 6 wie jetzt 8 R02+R02U2 R02(2/3) R02U2 R02(5/1) folgendes geht nicht, da R02U2 bei dstbest auf 270/01 und dstbew 248/01: 24/8 entspricht R02 24/8 270/1 entspricht R02+R02U2 26/3 270/1 24/2 beliebige Sammlung von Teilfeldern des Datensatzes folgende Lösung wurde umgesetzt: 6 6 Stellen R02, entspricht #123456 8 7 Stellen R02 + R02U2, entspricht #12345678 #1284 R02(1) R02(2) R02U2(1) R02(4)
- Der Anwender stellt Bestands- und Bewegungsdateien des Statistikdatensatzes über verschiedene Jahre in ein Verzeichnis
...\meine_Prognose\dst
(Ist Name des Unterverzeichnissesdst, dann sind die Ausgabeverzeichnissemakroundbprogparallel zudst, ansonsten Unterverzeichnisse vondst) - durch
- Anklicken Hauptmaske/Einwohner/Prognose/Standardprognose
- Aktivieren des oben genannten Verzeichnisses
- [ 1 ] Glätten Prognose-Eingabedaten
- [ 20] Anzahl Prognosejahre
- [ 2 ] Reporting
- [ 2 ] Berechne Indikatoren
- [v] Haushalteprognose anschließen
- (evtl. weitere Parameter wie NAG, NAGFU, NAGFO)
- Erzeugen der Makrodateien aus den vorhandenen Jahren für die Gesamtstadt in ein Verzeichnis
...\meine_Prognose\makro - Erzeugen der Raten, Quoten und reftyp in ein Verzeichnis
...\meine_Prognose\bprogfür eine Prognose mit Außenwanderung für: 1 Gebiet, 1 Bevölkerungsgruppe, 100 Altersjahre, 1 Aussentyp , globaler Zuzug K1. Der Aussenzuzug ermittelt sich aus den vergangenen Jahren: Annahme, dass entsprechend dem Durchschnitt der existierenden Jahre aus dstbew im Prognosezeitraum zugezogen wird (z.B. zuvol: 2015..2099;1;1;1; Anzahl= Durchschnitt der Jahre) - Gleitendes Mittel mit gewählter Fensterbreite für fruc, strb, wegz, zudq
- Anstoß eines Prognoselaufs über die Anzahl gewünschter Jahre
- Reporting
- Indikatoren
- Haushalteprognose (Quotenberechnung + Prognose)
Durch Start obiger Einzelschritte kann der Anwender
- überprüfen, ob die voreingestellten Parameter der Einzelschritte generell bzw. für die aktuelle Prognose sinnvoll sind
- durch ändern der voreingestellten Parameter die aktuelle Prognose den eigenen Anforderungen anpassen
Die wählbaren Grenzen NAGFU (z.B. 15) und NAGFO (z.B. 44) wirken an folgenden Stellen im Prognoseprozess:
- Berechnung fruc-Datei aus geburt und bestand
Eingabe NAGFU/NAGFO in Startmaske
SIKURS-Eingabedaten aus Makrodateien
Ist das Geburtsalter der Mutter unter NAGFU, so wird die Geburt der Altersklasse NAGFU zugeschlagen.
Bei der Geburtenrate entstehen bei NAGFU erhöhte Werte, da der Bestand bei NAGFU nicht verändert wird.
(analoges gilt für NAGFO)
Diese Verfälschung ist unnötig!
Lösung: Bei der Berechnung der fruc-Datei Vorgabe von NAGFU und NAGFO, so dass keine Werte ausßerhalb liegen.
Wenn der Benutzer eine Fruchtbarkeitsrate > 0 in der Altersgruppe 53 für einen Datenfehler hält, kann er ihn manuell korrigieren. - Berechnung fruc-Datei aus Hadwiger-Parametern
Statt der Vorgabe von NAGFU und NAGFO kann man einen Schwellwert mit Voreinstellung (z.B. 0.000001) setzen, ab dem man bei der Berechnung des Werten in der Glockenkurve den Wert Null annimmt. - Glättung
Bei der Glättung bleiben die Parameter Unter-/Obergrenze Alter, über die hinaus die Glättung die Daten nicht "verschmieren" soll. - Prognose
Statt der Vorgabe NAGFU/NAGFO mit Warnung, wenn Grenze beim Einlesen von fruc verletzt wird, wird auf die Vorgabe von NAGFU/NAGFO im Methodenassistenten verzichtet und stattdessen im Prognoseprotokoll nach dem Einlesen der fruc-Datei der tatsächliche Altersbereich protokolliert. - Visualisierung Indikatoren
für den Indikator AGR:
Allgemeine Geburtenrate (AGR) = 1000 * Anzahl Lebendgeborene im Jahr (ALG) / Anzahl Frauen im gebärfähigen Alter (AFGA)
braucht man Unter-/Obergrenze Fruchtbatkeit.
Diese wird in der Startmaske Indikatoren abgefragt, statt wie früher NAGFU/NAGFO aus dem Methodenassistenen, bzw. der ini-Datei zu entnehmen, um AFGA zu berechnen.
- Berechnen/Geburtenrate nach Vorgabe zusammegefaßte Geburtenrate
NAGFU/NAGFO aus der Startmaske mit Voreinstellung aus der ini-Datei wurde für die Berechnung verwendet.
Da die Werte für die Berechnung nicht notwendig sind, wurde die Vorgabe NAGFU/NAGFO entfernt.
Die Vorgabe des Intervalls (z.B. 15 .. 44) bei der Berechnung der Geburtenraten aus Makrodateien ist wieder möglich:
- die Geburten der Altersgruppe 14 werden den Geburten der Altersgruppe 15 zugeschlagen.
- die Altersgruppe 15 hat dadurch ein erhöhte Geburtenrate
- die Anzahl der Geburten bei der Prognose unter Verwendung dieser veränderten Geburtenraten ändert sich nicht
- Bei der Berechnug wird protokolliert wieviel Geburten anderen Altersklassen zugeschlagen werden
- der Anwender kann eine geeigneteres Intervall wählen
Die Endbestände und/oder Bewegungen über alle Jahre und Aggregate (Untersuchungsraum, Gebiet, Typ Geburten, ..., Räumliches Aggregat) sollen in einer Datei export.csv oder in nach Aggregat aufgeteilten Dateien export_nnn.csv erstellt werden.
Entwicklungsschritte
- Erweitern Maske Prognose/Berechnen (erledigt)
Ausgabe Differenzierung Ausgabedateien [02 ] Gebiet (00 keine Ausgabe, ..., 13 räumliches Aggregat 2) [v] Anzahl Bevölkerungsgruppen (NBG) [v] Anzahl Geschlechtsgruppen (NGG) [v] Anzahl Altersgruppen (NAG) <- neuer Menüpunkt
- Ändern Ausgabe
- agg.csv kann entfallen, weil Bestand als letzte Spalte
in bewagg.csv (offen)
Die folgenden Dateien können entfallen (offen)- bew.csv sntspricht bewagg.csv in voller Differenzierung
- bewgem.csv entspricht bewagg.csv auf Gebietsebene ohne demografische Differenzierung
- bewgemagg.csv entspricht bewagg.csv aggregiert auf eine Typ oder Aggregat und ohne demografische Differenzierung
- bew.csv bewagg.csv bewgem.csv bewgemagg.csv enthalten nur die in der Bausteinkombination relevanten Bewegungen (erledigt)
- agg.csv kann entfallen, weil Bestand als letzte Spalte
in bewagg.csv (offen)
Nach diesen Änderungen erfüllt bewagg.csv fast alle Anforderungen an export.
Folgende kleine Tools erfüllen die restlichen Anforderungen
- Aufteilen:
liest eine auszuwählende Datei z.B. bewagg.csv und zerteilt sie nach wählbaren Spalten, z.B. Spalte 2 (Gebiet/Typ/Aggreagt) ein Unterverzeichnis, z.B.bewagg 103.csv 104.csv ... 217.csvMit
Einwohner/Prognose/Berechnen/Notiz
!GEMALL 2
werden die Prognoseergebnisse werden in gem.csv statt gem2015.csv, ... ausgegeben.
Mit Wahl von Spalte 1 läßt sich gem.csv in gem/2015.csv ... aufteilen.
- Ausschneiden:
Nach Auswahl der Spalten 1..5, 7 von bewagg.csv werden die Sterbefälle in eine Ausgabedatei geschrieben.
(alternativ mit Excel Spalten in eine neue Datei kopieren.) - Anfügen Spalten
An eine Datei bew/bewgem/bewagg/bewgemagg kann man die Wertespalte einer geeignet aggregierten zr_gem anhängen.
Bearbeiten
Datei (mit dem Standardwerkzeug seiner Dateiendung)
Aufteilen Datei (z.B. bewagg in Datei pro Gebiet)
Ausschneiden (z.B. Spalten 1..5, 7 - Sterbefälle)
Anfügen Spalten (z.B. zr_gem an bew)
Mit
Einwohner/Prognose/Berechnen/Befehle
my $eck = filesum('eckreg', 2010);
my $gem = filesum('gem2010', 2010);
is($eck, $gem, 1, "eckreg $eck = $gem2010 $gem");
kann man prüfen, ob in der Prognose 2010 der Bevölkerungseckwert erreicht wird.
Mit diesem Mittel sind viele Plausibilitätsprüfungen machbar,
aber dem Anwender so nicht zuzumuten.Um dies zu verbessern, kann man die Prüfungen klassifizieren
- ist SIKURS richtig programmiert ?
Neuer MenüpunktErgebnis/Bearbeiten/Blackbox Test [ 2,5] Toleranz Abweichung ($tol) [ 2] Geschwätzigkeit ($verbose)
Dies startet ein Prüfprogramm mit folgender prinzipieller Logik:Wenn "Ausgabe differenzierte Bewegungen" ([DEFAULTS]ABEWGEM=1) dann chkbew 'bew', jahre(), $tol, $verbose; Wenn Baustein M1 dann Über alle Prognosejahre $jahr: my $eck = filesum('eckreg', $jahr); my $gem = filesum('gem'.$jahr, $jahr); is($eck, $gem, $tol, "eckreg $eck = $gem$jahr $gem");... usw. für diverse Bausteine und EckwerteWenn ein Anwender eine Prognose als Regressionstest nutzt, d.h. damit jede neu SIKURS-Version überprüft, dann kann er in
Einwohner/Prognose/Berechnen/Befehleblackbox_test 1, 0;
eintragen. - sind meine Auswahl an Prognosebausteinen und meine Eingabedaten richtig ?
Hier könnten Prognose-Theoretiker/-Praktiker Tests vorschlagen wie z.B. "Geburtenüberschuß darf es in max. 3 Gebieten und 2 Folgejahren geben", d.h. der Anwender müsste aus eine Menge von Prüfungen auswählen und Parameter für diese Prüfungen vorgeben können.
In der Startmaske Quotenberechnung
Referenzdatei [referenz ] Name [2 ] Spaltennummer Typ [0 ] Abbildung R02/R02U2wurde das Eingabefeld Name entfernt, die Datei muss immer
reftyp.csv heißen.Bei "0 Stellen R02", d.h. mit. nur einem Typ wird keine
reftyp.csv
benötigt.Ziel ist es, für hhprog die gleiche
reftyp.csv mit Spalte
11 für Typen Haushalteprognose zu verwenden wie bei der SIKURS-Prognose.Die Erstellung einer
reftyp_roh.csv wurde in die
Berechnung Makrodaten aus Statiskdatensatz Bestand vorverlegt, weil
die den "work flow" vereinfacht.
Wenn es Demografische Sondergruppen gibt, sollen
strb = sterb / (Brutto- oder Nettobestand)
dsgr = dsg / Brottobestand
gerechnet werden.
Dazu müssten 2 Tools angepasst werden:
- Eingabedaten/Berechnen/Makrodateien aus dst
Wenn in der Startmaske
Ableitung Demografische Sondergruppen dsg
angefordert wird, dann gab das Programm zusätzlich die Datei
nettobestand ( = bestand - dsg )
aus.
Diese wird nicht mehr benötigt, kann aber bei Bedarf mit
Ergebnis/Bearbeiten/Spalten subtrahieren nettobestand = bestand - dsg
selbst berechnet werden. - Eingabedaten/Berechnen/SIKURS Eingabedaten aus Makrodateien
Wenn im Eingabeverzeichnis eine Datei dsg liegt, fragt das Programm, ob die Raten mit Brutto- oder Nettobestand gerechnet werden sollen.
Die Quote dsgr und die gem-Datei wird immer mit dem (Brotto-) bestand berechnet und die Raten je nach Wahl:
[ ] Raten bis auf DSGR aus Nettobestand(nur bei experimentell)
(Vorschlag: Umbenennen dsgr in dsgq, weil es eine Quote und keine Rate ist)
Einwohner/Prognose/Berechnen/Notiz !AUSGABE_GSTROM n !AUSGABE_GWEGZUG n !AUSGABE_GZUZUG n n: differenzierung der Ausgabe nach reftypBisher wurde die Binnenwanderung auf Binnentypenebene als Datei strom.csv (*) ausgegeben.
00 keine Ausgabe
01 Untersuchungsgebiet 02 Gebiet 03 Typ Geburten 04 Typ Sterbefälle 05 Typ Binnenwanderung 06 Zieltyp Außenzuwanderung 07 Quellentyp Außenwegwanderung ...
Die Relevanz der absoluten Bewegungen zwischen den Binnenwanderungstypen hängt von der Typisierung der Binnenwanderungstypen ab
- entsprechen die Binnenwanderungstypen räumlichen Aggregaten, dann sind die Bewegungen zwischen diesen räumichen Aggregaten interessant
- entsprechen die Binnenwanderungstypen Clustern von Gebieten mit ähnlichem Binnenwanderungsverhalten (was dem Sinn der SIKURS-Typen entspricht), dann sind die Summen der Bewegungen zwischen den Clustern weinig informativ
Bei sehr kleinräumigen Prognosen mit sehr vielen Gebieten kann dies
- viel Rechenzeit
- große Datei
gstrom.csv - insbesondere bei
gstrom.csvzu kleine Ströme zwischen manchen Gebieten für statisitsch relevante Aussagen - unbefriedigende Visialisierung
Beispiel einer Wanderungsbilanzmatrix zwischen 356 Gebieten
(als Format wurde pdf gewählt, weil man die Anzeige Zoomen kann)
Bei Ausgabe gstrom/gwegzug/gzuzug mit Gebietskennzeichen kann man mit Blackbox-Test die Konsistenz mit bew prüfen.
Bei gstrom und Baustein P Abweichungen zu bew (Binnenwegzug, Binnenzuzug, Innenauszug, Inneneinzug)
Weiterentwicklung siehe roadmap 059, 086
Wenn die zu glättende Pyramide unbesetzte Altersbalken hat, muss man folgendes beachten, um den nicht vorhandenen Balken größer ziehen zu können
- [v] fehlende Altersgruppe mit 0 besetzten (setUndef)
- und entweder
- beim Glätten einer Pyramide mit Taste "-" die Linienpyramide vorübergehend ausblenden, damit man den winzigen Balken mit der Maus anfassen kann. Anschließend kann man mit der Taste "+" die Linienpyramide (die als Erinnerung für die Form der Ausgangspyramide dient) wieder einblenden.
- [ 1] Zusatzzwischenraum für Linienpyramide (gapextra)
Durch diesen zusätzlichen Zwischenraum (im Bereich -2 .. 2) wird die Linienpyramide um diese Anzahl Pixel verschoben, so dass man einen darunterliegenden Balken der Länge 0 anfassen kann
hst: Der Vorschlag für eine methodische Erweiterung von SIKURS bezieht sich auf die Festlegung der demografischen Struktur der Rückbauendauszieher. Im Augenblick gibt es die Datei RUECKBAUB (analog NEUBAUB) für die Anzahl Bewohner und die Datei REAQ (analog NEBQ), in der die demografischen Quoten abgelegt sind. Das sollte auch so bleiben.
Eine Erweiterung der Möglichkeiten, die demografische Struktur zu bestimmen, ist eine Anlehnung an das Vorgehen wie bei den demografischen Sondergruppen mit der Datei DSGR, d.h. die demografische Struktur der Rückbauendauszieher orientiert sich an der der Bevölkerungsstruktur des Gebietes, in dem der Rückbau ausgeführt wird. Die entsprechende Datei sollte dann REAR heißen. Im Anschluss an die Ermittlung der demografischen Struktur müsste dann die Anzahl angepasst werden an den Wert der Datei REAR. (Im Prinzip handelt es sich um das Vorgehen wie bei dem Außenwegzug mit Zielvorgabe)
wib: Baustein E2:
reaq2016.csv entfällt
rear.csv: #jhr;gkz;Rate 2020;101;0,3Definiert die Rate der Rückbauendauszieher
rueckbauweg definiert wie be E1 die Aufteilung in die Außentypen
wib: Unterschiedliche Differenzierung der Eingabedateien
- W1: BGWRjjjj.csv
- Typ Wechsel der Bevölkerungsgruppe
- Geschlechtsgruppe
- Altersgruppe
bew.csv (, bewgem.csv, ...)unter "Wechsel von" und "Wechsel nach"
Der Wechsel der Bevölkerungsgruppe erfolgt nach der Berechnung der Geburten und Sterbefälle (Wechselrate + Sterberate + Wegzugsraten) soll < 1 sein.
- Y1: BGWQG.csv
- Typ Geburtenrate (ungeeigneter Typ, besser streichen oder neuer Typ "BG-Wechsel Geburt")
- keine Differenzierung nach Geschlechtsgruppe (sinnvoll?)
- feste Altersgruppe 0
Die Abbildung der Geburten auf die BG erfolgt bei der Geburt und vor den Sterbefällen.
Die Geburten im Protokoll und in der Dateibew.csvsind die Geburten nach dem "Bevökerungsgruppenwechsel Geburten".
Den Wechsel ausbgwg.csvkann man mit Geburten aus bewagg, oder bewgemagg verrechnen, wenn letztere auf Typen Geburten aggregiert sind.
- soll man die Bausteinkombination W1 Y1 ausschließen, d.h. zuerst ein Wechsel der 0-jährigen nach Baustein Y1, anschließend noch ein Wechsel der 0-jährigen (und älteren) nach Basutein W1
- Baustein Y streichen und im Handbuch schreiben:
Häufige Anwendung:
Wenn inBGWRjjjj.csvdie Altersgruppe 0 belegt ist, entspricht dies einem Wechsel der Bevölkerungsgruppe bei der Geburt, ist nur die Altersgruppe 0, belegt, entspricht dies dem (gestrichenen) baustein Y
- Herr Hanika prüft in Absprache mit hst, ob er Y1 unabhängig von W1 benötigt
m,h: Zu Der Wechsel Bevölkerungsgruppen für die Gruppe mit dem Altersindex 0 erfolgt vor der Festlegung der Ausgangsbevölkerung.
Wir schlagen vor, den Wechsel der Bevölkerungsgruppe für alle demografischen
Gruppen (BG,GG,AG) vor der Bestimmung der Ausgangsbevölkerung für die
anschließenden Berechnungen auszuführen.
Anhang:
048bewW1.csv
048bewY1.csv
048indexW1.html
048indexY1.html
wib: durch die Verlegung der Berechnung von W von "nach Sterbefälle"
nach "nach Geburten, vor Festlegung
Ausgangsbevölkerung = ((Anfangsbevölkerung - Sondergruppen) gealtert + Geburten) nach Wechsel Bevölkerungsgruppen
erreicht man:
Die Datei bgwr0000.csv kann z.B. bei einer Altersgruppe 0
den Wert 1 haben, ohne dass bei mindernden Raten (Sterberaten, Wegzugsraten)
negative Bevölkerung entsteht.
Notwendige Änderungen:
- Im Programm:
- Vorverlegung
wechselBGnachgeburtenund vorsterbefälle - durchführen Wechsel der BG in Routine
wechselBG - keine Berücksichtigung
DG4WBGv, DG4WBGnbei der Außenwanderung (IRW) - keine Addition von
DG4WBGv, DG4WBGnzur Ausgangsbevölkerung zur Berechnung der Endbevölkerung
- Vorverlegung
- Die Prüfung auf Konsistenz der Datei
bew.csvinblackbox_testerfolgt dann durch:
(gem2019 - dsga2019) gealtert + (alle Bewegungen aus bew.csv mit Vorzeichen (incl. Geburten und WechselBG-von/nach) == 0 ?
- Anpassung Benutzerhandbuch
Lenkungsausschuss 2018: keine Änderung an den Bausteinen W1 Y1, da diese von den Anwenderen für verschiedene Zwecke eingesetzt werden.
Review Handbuch Bevölkerungsprognose (bhb.pdf) durch Systemexperten und bereuende Stelle, Einarbeitung Review-Ergebnisse.
hst: Im SIKURS-Prognosebaukasten werden die Ausprägungen verschiedener Bewegungen unter Verwendung der zum Start der Prognoseberechnungen festgelegten Ausgangsbevölkerung und bewegungsspezifischen Raten ermittelt. Dabei werden die verschiedenen Bewegungen als von einander unabhängige Prozesse betrachtet, obgleich dem nicht so ist, denn die Bewegungen laufen teilweise parallel. Z. B. kann ein bereits Gestorbener nicht mehr an der Wanderung teilnehmen. (Alternative 043 Differntialgleichung). So werden die Außenwanderungsraten, die Sterberaten oder die Binnenwegzugsraten auf dieselbe Ausgangsbevölkerung bezogen. Aber diese Vereinfachung ist akzeptabel, weil sie auf verschiedene Bewegungen angewandt wird.
Das Schema sollte jedoch nicht auf zwei Prozesse innerhalb einer Bewegungsart übertragen werden. Zur Ermittlung der Neubaubezugquellen und der Rückbauendauszugsziele soweit sie im Untersuchungsgebiet liegen wird als erstes die damit verbundene Binnenwanderung mit der Ausgangsbevölkerung und den Binnenwanderungsraten bestimmt. Anschließend wird die "normale Binnenwanderung" wiederum mit denselben Daten ermittelt. Der Rückbauendauszug und der Neubauerstzuzug werden als zusätzliche Bewegung zu der Binnenwanderung addiert und die gesamte Binnenwanderung wird hier als Summe beider Binnenwanderungsarten bestimmt. Im Gegensatz zur Adition von Außen- und der Binnenwanderung ist dies Vorgehen jedoch innerhalb eines Wanderungstyps methodisch nicht zulässig. Neubau und Rückbau als zusätzliche Binnenwanderung passen nicht in dieses Schema, weil hier einmal die induzierte Binnenwanderung und anschließend die "normale" Binnenwanderung bestimmt werden.
Weil in diesem Fall davon ausgegangen wird, dass einzelne Personen sowohl an der Neubau, an der Rückbau und an der üblichen Binnenwanderung beteiligt sind, ist dieser Ansatz nicht konsistent. Als Ergebnis wird damit die Binnenwanderung überzeichnet und es kann schnell geschehen, dass die Zahl der Binnenwanderungen die Anzahl Bewohner im Ausgangsbestand übersteigt.
Daher schlage ich vor, zunächst die Binnenwandernden für Neubau und Rückbau zu ermitteln, weil dies die "sicheren" Angaben sind. Zur Berechnung der "normalen" Binnenwanderung sollen die üblichen Raten verwendet werden, jedoch soll die Ausgangsbevölkerung für die Berechungen der normalen Binnenwanderung um die Wanderungen für Neubau und für Rückbau zu reduziert werden. Damit wird das Volumen der normalen Binnenwanderung verringert, in der Summe wird das Volumen der Binnenwanderung bei Neubau und Rückbau erhöht, jedoch eingeschränkt und kontrolliert durch den Umfang der bereits im Zusammenhang mit Neubau und Rückbau ermittelten Binnenwanderung
Dazu ein vereinfachtes Beispiel:
Bewegung ohne Neubau/Rückbau = 1000*0,6 = 600 b Beispiel für derzeitige Berechnung bei Rückbau und Neubau: Binnenwanderungsrate=0,6; Neubaurate=01; Rückbaurate=0,4) Bewegung = Ausgangsbevölkerung* (Rate Neubau = 0,1 + Rate Rückbau = 0,4 + Rate Binnenwanderung = 0,6) Binnenwanderung insgesamt = 1000 * (0,1+0,4+0,6) = 1100 oder etwas anders dargestellt: Binnenwanderungsrate=0,6; Binnen-Neubauauszug =100 Personen; Binnen-Rückbauendauszug = 400 Personen) Binnenwanderung insgesamt = 1000 * 0,6 + 100 + 400 = 1100 c Beispiel für vorgeschlagene Berechnung bei Rückbau und Neubau: Bewegung 1 = Ausgangsbevölkerung*(Neubaurate + Rückbaurate) (Neubau und Rückbau) = 1000*(0,1 + 0,4) = 500 Bewegung 2 = (Ausgangsbevölkerung - Bewegung1)*Rate-Binnenwanderung = (1000 - 500) *0,6 = 300 Binnenwanderung insgesamt = Bewegung1 + Bewegung2 = 500+300 = 800 < 1000 oder etwas anders dargestellt: Binnenwanderungsrate=0,6; Binnen-Neubauauszug =100 Personen; Binnen-Rückbauendauszug = 400 Personen) Binnenwanderung insgesamt = (1000 -400-100) * 0,6 +400 + 100 = 800 < 1000Bei der Außenwegwanderung ist diese Modifikation nicht erforderlich, da die Außenwanderung als Arbeitsplatz/Ruhestandswanderung verstanden wird und die vom Rückbau induzierte Wanderung zu der Arbeitsplatzwanderung addiert werden kann. Es sind also zwei unterschiedliche Motive die die Außenwanderung steuern.
wib: (siehe 075 Absicherung Außenwanderung)
hst: Bei dem Einsatz von RUECKBAU muss verhindert werden, dass die durch den Rueckbau freigewordene Wohnkapazität bei der Aufteilung des Zuzuges auf die Gebietseinheiten eines Types mitberücksichtigt wird. Daher muss bei der Ermittlung der freien Wohnkapazität je Gebietseinheit das Volumen des Rückbauendauszuges von der Ausgangsbevölkerung abgezogen werden. Damit wird verhindert, dass ein Gebiet, das vollständig durch den Rückbauendauszug entleert wird, wieder durch Binnen- und Außenzuzug bevölkert wird. Eine Hilfskonstruktion wäre, die Attraktivität für die Gebietseinheit auf Null zu setzen.
wib: Berechnung Freie Wohnkapazität FWKG geändert (ohne DG4OBR, DG4OAR)
053.pdf 053.txt
Erledigt sind
- 10 Excel-Beispiele:
A B C D E G I K M N P R S T V W Y # 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 2 1 2 0 0 0 0 0 1 0 0 0 2 0 0 2 0 0 0 1 3 0 0 0 0 0 1 0 0 0 3 0 0 3 0 0 0 1 4 0 0 0 0 0 1 0 0 0 4 0 0 4 0 0 0 1 4 0 0 0 0 0 1 0 0 0 5 0 1 0 0 1 0 1 2 2 0 0 2 0 1 0 0 0 6 0 1 0 1 0 1 1 1 1 0 0 1 1 1 0 0 0 7 1 0 0 0 0 0 1 4 2 0 0 0 0 1 0 1 0 8 1 0 0 0 0 0 1 5 1 0 0 0 0 1 1 0 0 9 1 0 0 0 2 0 1 6 2 0 0 2 2 1 0 0 0 10 ------------------------------------ 1 1 6 1 2 2 1 6 2 4 2 2 2 1 1 1 1 max * * 6 * * * * * * ? ? * * * * * * fehlende Bausteine (* keine, ? alle)
- Methodische Aufarbeitung des aktuellen Programms mit
- unabhängige Typen G, S, (B < ZZA), QWA, NEE, REA, WBG, AGF
- Neubau, Rückbau
- Methodische Überarbeitung der Algorithmen
- Eindeutige Zuordnung Excel-Dateiname (M1A1) zu ini-Datei (M1A1.ini)
- Von Hand gepflegte Identität SIKURS-Einagedateien reftyp, gem2017, eckgem_a, eckgem_b, ... zu den gleichnamigen Matrizen in der Excel-Datei input.
- Präsentation Ergebnis bei betreuender Stelle
- Überprüfung der Prognosen und der Beschreibung im Benutzerhandbuch der aktuellen SIKURS Version
- Vorgabe für die Korrektur bei evtl. gefunden Fehlern
- Zukünftiger Vorgabe neuer oder zu ändernder Bausteine
- "non regression test" zukünftiger SIKURS releases
- Verteilung eines konsistenten Satzes Excel-Dateien, ini-Dateien
und SIKURS-Eingabedateien nach Änderungen
- wer wiederholt wann Vergleich Excel zu Programm-Ergebnisse ?
- wer pflegt Excel-Beispiele ?
- wie bringt man Änderungswünsche ein ?
- wie werden Versionen gekennzeichnet ?
SIKURS-Excel_10.4.rarwie SIKURS-Hauptversion z.B. ?SIKURS-Excel_10.4.0.918.rarwie SIKURS-Referenzversion 918, die für das erste Release verwendet wurde ?- eigenes Versionskonzept ?
- Namenskonvention der ini-Dateien
(z.B.
A1M1.iniim Verzeichnisbaustein- Reihenfolge Bausteine Alphabetisch
- Weglassen x0 (x=A, B, ..., Y)
- T0 (statt A0bisY0) falls alle Bausteine x0
- Ergänzug mit "_" möglich: "B1I1K1_Ausgabe_Binnenmatrix"
check_name.batprüft die Namenskonventionen - Der Vergleich der Zwischenergebnisse mit dem Prognoseprotokoll muss einfach sein
- Die Variablennamen (z.B. DG4OB für Binnenauszug) müssen
im Excel-Blatt sichtbar sein und sollten incl. Langtexte
in Excel und Protokoll identisch sein
(siehe roadmap 102)
- Die Variablennamen (z.B. DG4OB für Binnenauszug) müssen
im Excel-Blatt sichtbar sein und sollten incl. Langtexte
in Excel und Protokoll identisch sein
- Zusätzlich zur Formel (z.B.
=-(M6+M9+M12)*(P6+P7+P8)/SUMME(P6:P14)) für ein Spalte (z.B. Inneneinzug) wäre ein zusätzlicher Kommentar (z.B. Verteilung Innenauszug nach Anteil freier Wohnplätze) für das Verständnis und für den Abgleich mit dem Benutzerhandbuch nützlich - Automatischer Vergleich SIKURS-Prognose mit Excel-Beispielen
Ein manueller Vergleich der 10 (+10 roadmap 093) Excel-Beispiele mit den zughörigen SIKURS-Prognoseläufen- Stimmen die Eingabedaten überein ?
- Stimmen alle Zwischenergebnisse im Protokoll (bei Protokollumfang 4) mit den Zwischenergebnissen in Excel überein, d.h. ist der Berechnungsgang identisch ?
- Stimmen SIKURS Ausgabedatei bew und gem mit den zugehörigen Werten in Excel überein ?
Für eine Wiederholungsprüfung (nach einer Programmänderung) könnte man durch folgende Automation den Prüfaufwand auf wenige Minuten reduzieren.- Der Methodenexperte kopiert nach einem erfolgreichen manuellen Vergleich der Excel-Ergebnisse mit den SIKURS-Prognoseergebnissen die Verzeichnisse der SIKURS-Prognoseergebnisse in eine Verzeichnis "geprüft" und verteilt diese neuen Excel-Beispiele.
blackbox_testwird erweitert um eine Prüfung, ob die Ausgabedateien (gem, bew, bewgem, ...) bis auf ein einstellbares Delta mit der Kopie der geprüften Ausgabedateien übereinstimmen.- Führt eine Programmänderung zu einer Verletzung obiger Prüfung, muss ein neuer konsistenter Satz Excel-Beispiel und manuell geprüfte SIKURS-Prognoseergebnisse erstellt werden
- bausteinkombinationsspezifischer Datenflußgraph
Der Graph kann als Ergänzung zum Verständnis eines Excel-Beispiels herangezogen werden. Da dieser umfangreich ist, ist es nützlich, den Graph auf eine vorzugebende Bausteinkombination zu reduzieren. Dafür sind folgende Arbeiten notwendig:- Einige Kanten (z.B.
(dsg2000) --R2--> [DSGA]) enthalten bereits den notwendigen Baustein (R2), Diese Information muss für weitere Kanten in den C++-Quellcode eingepflegt werden. - Ein Perl script extrahiert auf Anforderung die Informationen für den Graph in eine Datei sikurs.dot
- Ein Filter reduziert sikurs.dot auf eine
vorzugebende Bausteinkombination, durch
- entfernen
- ausgrauen
- das Programm dot erzeugt aus sikurs.dot den Graph in den Formaten svg und pdf
- Damit kann man für jedes oder für Gruppen von Excel-Rechenbeispielen einen zugehörigen Graph erzeugen. (siehe Beispiele und 084)
- Einige Kanten (z.B.
- A1M1T1, A1M2T1: bei Zielwert, der durch Anpassung Wegzug nicht erreicht werden kann, Vorgabe Höchstwert Eckwert in Warnmeldung
- B1E1I1K2M2R2T1
- verhindern negativen Zuzug bei zu geringem Zielwert
in
eckregund Vorgabe Mindesthöhe Eckwert in Warnmeldung - Einbeziehung Rückbaueendauszug nach Außen in Berechnung Anpassung Zuzug
- verhindern negativen Zuzug bei zu geringem Zielwert
in
- A1E2I1K6M2R2S2T1 mit kritischer Kombination A1K6M2 korrigiert
- B1K1M1/2
zuvolglobal (K1) braucht nicht eingelesen zu werden, weil die Anpassung Außenzuzug (B1) an Zielwerte für die Gebiete (M1/M2) mit einer beliebigen Vorgabe funktioniert. - A1I1M1P1 wenn in eckgem (P1) Zielwerte für alle Gebiete definierts sind, braucht eckreg (M1) nicht eingelesen zu werden, weil sich der Zielwert Bevölkerungsbestand (M1) als Summe der Zielwerte für die Gebiete (P1) ergibt.
- A1D1E1G1I1K1M1S1T2 Berücksichtigung Neubauerstbezug von Außen und Rückbauendasuzug nach Außen bei Anpassung Außenwegzug (A1) an Zielwert Bevölkerungsbestand (M1)
- A1D1E1I1K1M2T2 Berücksichtigung Neubauerstbezug von Außen und Rückbauendasuzug nach Außen bei Anpassung Außenwegzug (A1) an Zielwert Bevölkerungsbestand (M2)
- A1D1E1I1K1N1T2 zuvol wurde nicht eingelesen, dies ist bei B1K1N1 richtig, aber nicht bei A1K1N1
- D1I1K1T2 die Neubauerstbezugsquoten wurden bei der Aufteilung des Neubauerstbezugs nicht korrekt auf die Altersgruppen umgelegt, analog wurde die Aufteilung des Rückbauendauszuges auf die Altersgruppen korrigiert
- Die Aufteilung des Außenzuzug pro Altersgruppe proportional zur Größe AG-Gebiet/AG-TYZZA verstärkt übergroße Altersgruppen.
Jetzt erfolgt die Aufteilung des Zuzugs proportional zur Gesamtbevölkerung Gebiet/Gesamtbevölkerung TYZZA.
Protokollumfang 3 zeigt Details der Berechnung.
Protokoll (DG4ZA) und Datei bew.csv enthalten den Außenzuzug gegliedert nach Gebiet, BG, GG, AG
Die alte Variante von SIKURS 10.1 erreicht man durch
Einwohner/Prognose/Berechnen/Notiz
!ZAG 0(Ausgabedatei gzuzug.csv: Außenzuzug gegliedert nach Außentyp, Gebiet, BG, GG, AG)
!AUSGABE_GZUZUG 2
Im Rahmen 072 wurde die Aufteilung des Außenzuzugs auf die Gebiete proportional zur freien Wohnkapazität entwickelt. - Feintuning Binnenwanderung bei Neubau/Rückbau und P1
mit Umstrukturierung Berechnungsreihenfolge, um die Umlegung
von Rückbauendauszug in Binnenzieltypen auf die Gebietseinheiten
proportional zur Freien Wohnkapazität (statt Bevölkerung Gebiet /
Bevölkerung Binnentyp (
!IBR_FWKG 0)) zu bewerkstelligen
Zusätzlich Einführung modifizierter Ausgangsbevölkerung (OBE, OBR) bei Neubau/Rückbau und Änderung Berechnung Binnen- und Innenwanderung - tool Extras/Eigene Scripts/Start/IPF (Iterative Proportional Fitting) zur Anpassung von Matrizen der Excel-Dokumentaion an Zielwerte (Ober-, Unter-Grenzen)
- Bei P1/P2 Berechnung der freien Wohnkapazität ohne Differenz zum Zielwert (DZW)
- Überarbeitung Benutzerhandbuch und Methodische Hinweise (m-?)
auffällige Stellen sind durch Fußnoten mit Hinweis (wib) gekennzeichnet - Baustein B1D1I1K1M1P4R1W1Y1 (Mäding) Verbesserung Prüfung und Protokollierung Zielwerte aus ecktyp und eckreg.
- Überprüfung Excel-Beispiel BG3GG2/A1I1K4M2T1W1 (14)
!option($M2NEU n)- (default) wählt eine neue, zum Excel-Beispiel kompatible Berechnungsmethode für die Anpassung Außenwegzug (A1) auf Gebietsebene DG4WA an demografisch gegliederten Eckwert eckreg BR21 (M2).
- wählt alte Methode Anpassung DR3WA auf Typenebene und dient zum Austesten der neuen Methode
Unter Variantenprognose sollen mehrere Prognosen (z.B. tief, mittel, hoch) verstanden werden, bei denen einige Dateien gleich (z.B. reftyp, gem2015, ...), andere Dateien pro Variante unterschiedlich (z.B. fruc2016, fruc2017, ...) sind.
Die vernünftigste Verzeichnisstruktur ist ein Unterverzeichnis pro Variante:
meine_prognose
| reftyp.csv <---------+
| gem2015.csv <--------|--+
| | |
+-- tief | |
| v.ini | |
| reftyp.csv.lnk --+ |
| gem2015.csv.lnk ----+
| fruc2016.csv | |
| fruc2017.csv | |
| strb2016.csv | |
| strb2017.csv | |
| | |
\--hoch | |
v.ini | |
reftyp.csv.lnk --+ |
gem2015.csv.lnk ----+
fruc2016.csv
fruc2017.csv
strb2016.csv
strb2017.csv
Dabei verweist reftyp.csv.lnk auf reftyp.csv
im übergeordneten Verzeichnis (gem2015.csv.lnk analog).Die Verknüpfungen können entweder mit dem File-Explorer von Hand gesetzt werden, oder in der Startmaske der Prognose im Reiter Befehle
shortcut '../reftyp', 'reftyp'; shortcut '../gem2015', 'gem2015';Mit Einwohner/Prognose/Sammelprognose lassen sich alle Varianten in einem Lauf rechnen.
Mit folgender Erweiterung kann man aus das mühsame setzen der Links verzichten:
Enthält das übergeordnete Verzeichnis eine (leere versteckte) Datei
_variant,
so sucht das Programm fehlende Dateien im übergeordneten Verzeichnis.Ein neuer Menüeintrag
[v] Variantenprognosein der Startmaske/Parameter der Prognose automatisiert die Erstellung/Löschung der Datei
_variant
meine_prognose
| _variant
| reftyp.csv
| gem2015.csv
|
+-- tief
| v.ini
| fruc2016.csv
| fruc2017.csv
| strb2016.csv
| strb2017.csv
|
\-- hoch
v.ini
fruc2016.csv
fruc2017.csv
strb2016.csv
strb2017.csv
Die Variantenlogik wird genutzt in
- Der Prognose incl. eingebauter Zeitreihe
- Ergebnis/Bearbeiten/Blackbox Test
- Ergebnis/Zeitreihe
- Indikatoren
- Reporting
variant bei den mitgelieferten
Beispielen beispiel.zip (Siehe ?/Beispiel-Eingabedaten)
UTF-8 BOM (FF BB BF) am Dateianfang von csv-Dateien wird erkannt.
Es muss noch getestet werden, ob dies für alle Programme funktioniert, und was passiert, wenn die Dateien in den Kommentarzeilen
#©⊗ℜmerkwürdige Unicode Zeichen enthalten sind
zuaq hat die Spalten TYA, TYZZA, BG, GG, AG, Quote.
Dabei muss die Summe TYA, BG, GG, AG über TYZZA 1 ergeben.
Mit Hilfe einer Pivot-Tabelle mit Zeilenfelder TYA, BG, GG, AG und Datenfeld Quote läßt sich leicht überprüfen, ob die Summe immer 1 ist.
Ohne Pivot-Tabelle ist dies in dieser Anordnung der Spalten nur mühsam überprüfbar.
Bei einer Anordnung TYA, BG, GG, AG, TYZZA, Quote wäre dies viel einfacher:
#TYA;BG;GG;AG,TYZZA;Quote 1; 1; 1; 0; 1; 0,3 1; 1; 1; 0; 2; 0,5 1; 1; 1; 0; 3; 0,2 # Summe = 1 ...Zwischenlösung:
Wenn man das Programm mit Protokollumfang 3 startet, dann wird nach dem Einlesen von zuaq (in alter Reihenfolge) zunächst QR4ZA protokolliert und anschlißend QR4ZA_ in neuer Reihenfolge aufgebaut und protokoliert.
Bei der Berechnung zuaq aus Makrodateien ist die Sortierung in der Ausgabe TYA, BG, GG, AG, TYZZA
#TYA;TYZZA;BG;GG;AG;Quote 1; 1; 1; 1; 0;0,2 1; 2; 1; 1; 0;0,3 1; 3; 1; 1; 0;0,5 # Σ = 1 ... 5; 1; 2; 2;99;0,4 5; 2; 2; 2;99;0,1 5; 3; 2; 2;99;0,5 # Σ = 1um die Summe = 1 über die Typen Zuzug von Außen einfacher berechnen zu können
Beim Glätten bleibt Summe TYZZA = 1 in folgenden Varianten erhalten:
Glätten über das Alter Ersatz fehlende Werte (*) ohne (*) Wert [0 ] Glättungsmethode (*) Gleitendes MittelBeispielrechnung Gleitendes Mittel mit 4 Altersgruppen (AG) und 2 Typen Zuzug von Außen (TYZZA)
| Rohdaten | geglättet | |||||
|---|---|---|---|---|---|---|
| TYZZA | TYZZA | |||||
| AG | 1 | 2 | Σ | 1 | 2 | Σ |
| 0 | 1/10 | 09/10 | 1 | 6/30 | 24/30 | 1 |
| 1 | 4/10 | 06/10 | 1 | 5/30 | 25/30 | 1 |
| 2 | 0/10 | 10/10 | 1 | 7/30 | 23/30 | 1 |
| 3 | 3/10 | 07/10 | 1 | 6/30 | 24/30 | 1 |
Bei den sonstigen Glättungsvarianten kann sich die Summe TYZZA = 1 ändern, insbesondere bei
- Glätten über das Alter
Ersatz fehlende Werte (*) Interpolation (Option entfernen, da nur sehr selten sinnvoll ?) Glättungsmethode (*) Savitzky-Golay - Manuelles Glätten
- Glätten über Alter und Jahr
Warnung 1193: Summenwert (3,1..3,2,2,99)=1,14271752623892 außerhalb 1+/-SUMTOL(=0,001), Werte werden auf Summe=1 kalibriert
führen.
Lösungsansätze:
- Visualisierung/Pyramiden/Kontrollanzeige zuaq
falls Abweichung von 1:
Anwender kalibriert zuaq mit Extras/Eigene Scripts/Start/zuaq_norm - Bei der Prognose werden nur 3 Warnungen und eine Sammmelmeldung
Warnung: 1193 mal Allokationsquote kalibriert
ausgegeben.
Dies wurde bereits umgesetzt
Beim Glätten wird gefragt, ob Ausgabedatei zuaq-Sortierung haben soll
Wenn die Ausgangs-Makrodatei aussenzuzug für zuaq
(binnenwegzug für strm mit vielen Binnentypen (tyb),
aussenwegzug für wegz mit vielen Außentypen (tya)
und Quelltypen Außenwegwanderung (tyqwa))
zu wenig Fälle enthält,
dann ist die Struktur von zuaq so zufällig, dass auch kein Glätten hilft.
In diesem Fall wäre es vernünftiger die Anzahl Außentypen (tya),
die Anzahl Typen Außenzuzug (tyzza) (, evtl. die Anzahl Bevölkerungsgruppen und
die Anzahl Geschlechtsgruppen) und Differenzierung der Altersgruppen (ag)
zu reduzieren:
zuaq2010.csv: #tya;tyzza;bg;gg; ag;Quote 1; 1; 1; 1;00..17;0,518 1; 2; 1; 1;00..17;0,482 1; 1; 1; 1;18..64;0,614 1; 2; 1; 1;18..64;0,386 1; 1; 1; 1;65..99;0,736 1; 2; 1; 1;65..99;0,464 ...Der Demonstrator: Haupmaske/Extras/Eigene Scripts/Start/zuaq_aus_aussenzuzug
wurde umgearbeitet in die Lösung:
Hauptmaske/Eingabdaten/Berechnen/SIKURS Eingabedateien aus Makrodateien
[ ] Bevölkerungsgruppen zusammenfassen [ ] Geschlechtsgruppen zusammenfassen (denkbare Erweiterung) [v] Altersgruppen zu Altersklassen zusammenfassenund Eingabedatei
altersklassen.csv: bgwr;6;18;40;65 strm;12;40;65 zuaq;18;65
Die Indikatoren ZGZ (Zusammengefasste Geburtenziffer), BRR, NRR, DGAM, SDAM, AMGR werden nicht auf eine gewählte Aggregationsstufe (z.B. Untersuchungsgebiet ohne BG und GG) aggregiert, weil dies durch einfache Aggregation der Raten nicht korrekt wäre.
Herr Götz merkt richtig an:
warum sollte es denn nicht zulässig sein die ZGZ für das Gesamte Untersuchungsgebiet zu berechnen. Das wird doch ständig gemacht (z.B. von der amtlichen Statistik oder anderen Forschungseinrichtungen wie dem BBSR)?
Dazu muss man doch einfach nur die Frauen im gebärfähigen Alter des Jahres x-1 nehmen, diese dann ein Jahr altern lassen (also Geburtsindex verschieben) und dann den gealterten Frauenbestand ins Verhältnis zur Zahl der Geburten nach Alter der Müttern des Jahres x setzten. Die Summe aus diesen Raten ist doch dann die ZGZ. Welche Gebietseinteilung/räumliche Aufteilung man dazu verwendet, spielt doch keine Rolle, oder?
wib: für wählbar diffferenzierte ZGZ, BRR, Hadwiger-Parameter umgesetzt (Ausgabe in Datei ZGZagg.csv, BRRagg.csv, hadwiger(MO/ME/VAR).csv),
- aggregierte Indikatoren werden nur berechnet, wenn
gebam.csvvorhanden ist. - bei NGG=1 keine Ausgabe
Eine wählbar differenzierte Lebenserwartung wird berechnet, wenn Datei bew (Spalte Geburten, Sterbefälle) existiert.
Sollte die Laufzeit der neuen Indikatoren bei vielen Gebieten und Prognosejahren zu lange sein, kann eine Optimierung beim Lesen von gebam bzw bew geprüft werden.
Zur Vollständigkeit wird zusätzlich die Bevölkerung in gewünschter Aggregation ausgegeben.
Eine gute Alternative zum gleitenden Mittel könnte bei der Glättung der Sterberaten abschnittsweise Regressionsfunktionen sein. Dadurch ließen sich manuelle Eingriffe dann vollends vermeiden.
(s) Testen kann man die Glättung durch eine Weibull-Funktion, Parabel, Gerade, Konstante mit dem Tool
Eingabedaten/Dynamisieren/Intra-/Extra-polation durch Regression strb1992.csv Eingabedatei [-2 ] Zeitachse vorletzte Spalte Altergruppen [-1 ] y-Achse letzte Spalte Sterberate [1:1 2:1 3:1] Filter: Typ 1, BG 1, GG 1 strb1992_roh.csv Ausgabedatei Extrapolation [0:10 ] Jahresbereich Plotausgabe und Ausgabedatei [0:* ] Skalierung y-Achse [v] Weibull
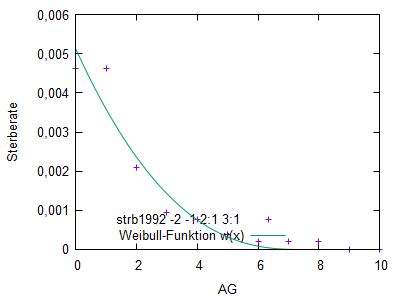
[10:29 ] zu analysierender Jahresbereich Eingabedatei [10:29 ] Jahresbereich Plotausgabe und Ausgabedatei [v] Konstante
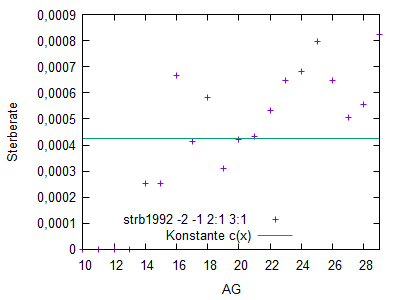
[30:99 ] Jahresbereich Plotausgabe und Ausgabedatei [v] Weibull
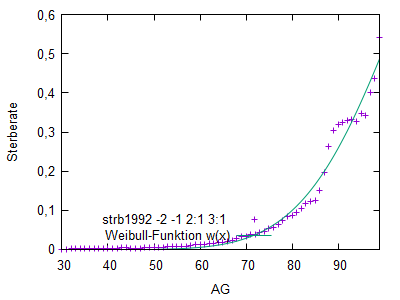
zusammengefaßt
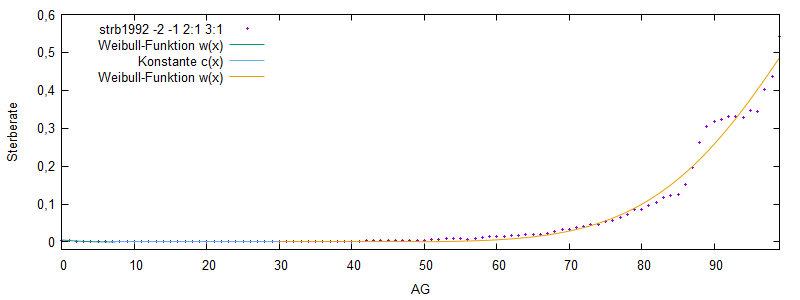
das sich neben der Extra/Inter-polation der Zeit auch für die Glättung über Altersgruppen eignet:
Die Extrapolation wird erweitert
- Beschreibung der Eignung für Interpolation
- Erweiterung für nicht ganzzahlige t-Achse
- Ergänzug der Weibullfunktion, die sich für die Altersbereiche 0 .. 10 und 30 .. 99 bei den Sterberaten anbietet (siehe auch Weibull)
- Optionale Angabe der Schrittweite für die Ausgabedatei (z.B. 0.1, 5)
- Optionaler Plot der Ausgabedatei
- Durch Angabe Wertespalte Möglichkeit Zeitreihen aus bew, bewgem, bewagg, bewgemagg zu bilden
- Ausgabe Label ausgewählte t-Spalte und y-Spalte in Plot
- Verbesserung Exponentialfunktion
- Ersatz Logarithmus durch Sättigungsprozess (Logistsische Funktion)
- Filter
4:*erzeugt Zeitreihen für alle Werte von Spalte 4 (z.B. alle Bevölkerungsgruppen) - experimentelle Funktionen Sinus, Polynom n-ten Grades, Rationale Funktion n-ten Grades
(m-uls) Wenn Überlagerungen von Balkengrafiken in der Darstellung der Raten optisch stören, wäre vielleicht eine Liniengrafik eine Lösung. Herr Walla meinte einmal: Raten und Quoten stellt man als Linien dar, Absolutwerte als Balken. Ist natürlich sehr dogmatisch, aber vielleicht einfach der Erfahrung geschuldet, dass sich Raten und Quoten in Grafiken eher als Absolutwerte überlagern können und Balken dann zu einem Problem werden.
(s) Welches ist der bevorzugte "gnuplot terminal type" mit seinen Exportformaten?
| qt | clipboard png bmp pdf svg |
|---|---|
| wxt | clipboard png pdf svg |
| windows | clipboard emf |
In Ausgabedatei
bew.csv sind die Ströme
- Außenzuzug
- Neubauerstbezug von außen
- Außenwegzug
- Rückbauendauszug nach außen
Die (alten) Augabedateien
zuzug.csv und wegzug.csv
sind nur nach Typen und nicht nach Gebietseinheiten differenziert.Deswegen gibt es neue bzw. geänderte Ausgabedateien mit Differenzierung nach Außentyp, Gebietseinheit, BG, GG, AG.
zuzug.csvAußenzuzugneba.csvNeubauerstbezug von außenwegzug.csvAußenwegzugreaa.csv.csvRückbauendauszug nach außen
strom.csv siehe roadmap 44, 87
Man kann einzelne Altersgruppen von der Anpassung ausnehmen und konstant lassen oder gezielt verändern
1..$NTYS;1;1; 0.. 4;$f*$s # Anpassung an Lebenserwartung ohne Gewichtung 1..$NTYS;1;1; 5.. 9;$f*$s*1.2 # stärkere Anpassung 1..$NTYS;1;1;10..14;$f*$s*1.0+$y/100 # zunehmend stärkere Anpassung 1..$NTYS;1;1;15..19;$f*$s*1.03**$y # um 3% jährlich zunehmend stärkere Anpassung 1..$NTYS;1;1;20..24;$f*$s*0.8 # schwächere Anpassung 1..$NTYS;1;1;25..29;$f*$s*1.0-$y/100 # zunehmend schwächere Anpassung 1..$NTYS;1;1;30..34;$f*$s*0.97**$y # um 3% jährlich zunehmend schwächere Anpassung 1..$NTYS;1;1;35..39;$s # keine Anpaasung Sterberate 1..$NTYS;1;1;40..44;$s-0.001 # Reduktion Sterberate um 0,001 1..$NTYS;1;1;45..49;$s-$y/1000 # Reduktion Sterberate um 0,001 pro Jahr 1..$NTYS;1;1;50..54;$s*0.97**$y # Reduktion Sterberate um 3% pro Jahr 1..$NTYS;1;1;55..59;$s*1.03**$y # Erhöhung Sterberate um 3% pro Jahr 1..$NTYS;1;1;60..99; # ohne Gewichtung (entspricht $f*$s)Details siehe Hilfe im Tool
- Hauptmenü/?/Beispiel-Eingabedaten öffnet beispiel.zip zum Entpacken in ein Verzeichnis nach Wahl des Anwenders
- Bei der Prognose beim Einlesen Sterberaten wird ein Hinweis im Protokoll ausgegeben, wenn Raten ab Altersgruppe 90 < 0,1 sind
- Glätten Option Ersatz fehlende Werte/Interpolation entfernt da zu fehlerträchtig
Datei Extras Optionen ? Hilfe SIKURS-Homepage Hauptmaske Handbuch Bevölkerungsprognose Haushaletprognose ...- Ausgaben in Textfenster SIKURS Hauptmaske finden sich zusätzlich
in Datei
prot.htmim jeweiligen Arbeitsverzeichnis - Anzahl Altersgruppen NAG
NAG kommt in 3 Prognoseschritten vor:- Ableitung der Makrodateien aus dem Statistikdatensatz
Die Makrodateien enthielten dann NAG Altersgruppen, wobei die letzte "NAG-1 oder älter" bedeutet.- das Feld NAG wurde aus der Maske entfernt
Im Protokoll wird die höchste vorkommende Altersgruppe 114 erwähnt. - Berechnung Raten/Quoten/gem aus Makrodateien
Hier ist die Vorgabe von NAG (z.B 100 oder 110) sinnvoll und sie muss kleiner oder gleich NAG aus Schritt 1 sein.
Die oberste Altersgruppe wird dann beim Einlesen der Makrodateien durch Aggregation gebildet. - Prognose
Hier muss NAG im Methodenassistenten erneut vorgegeben werden, da Schritt 1 und 2 nicht notwendig existieren.
Im Methodenassistenten wird als Vorschlag für NAG:
NAG aus ../makro/raten.ini, falls dieses existiert, sonst 100 verwendet.
Wenn der Vorschlag für NAG aus raten.ini übernommen wird, kann er in der Eingabemaske nicht mehr verändert werden.
Die Unter/Obergrenzen Fruchtbarkeit (NAGFU, NAGFO) werden in "Berechne Raten aus Makrodaten" für die Berechnung von fruc abgefragt.
Bei der Prognose wird NAGFU, NAGFO nicht benötigt.
Bei der Visualisierung/Indikatoren/Berechnung werden diese Werte aus../makro/raten.iniübernommen, falls vorhanden. - Ableitung der Makrodateien aus dem Statistikdatensatz
- reftyp.csv
reftyp_roh.csv wird in "Berechnen Makrodaten aus Statistikdatensatz" erstellt.
Viele Anwender nutzen den Statistikdatensatz nicht und beziehen Makrodaten von anderen Stellen. Für diese Anwender gibt es im Schritt "Sikurs Eingabedaten aus Makrodaten" die Möglichkeit reftyp_roh.csv zu erstellen - Berechne Makrodateien aus Statiskdatensatz
- das erste Editorfenster mit der Logdatei wurde entfernt, stattdessen Ausgabe ins Hauptfenster.
- beim Anlisten der Dateien mit Statistikdatensatz werden
Hinweise auf Dateien ausgegeben, die nicht den
Namenskonventionen
dstbest*.txt/dstbew*.txtentsprechen
- Berechne SIKURS-Eingabedateien aus Makrodateien
Die Berechnung jeder SIKURS-Eingabedatei ist an Bedingungen geknüpft, z.B.
Für die Berechnung von fruc werden mindestens eine Makrodatei geburt und bestand benötigt.
Um die Bedienung zu vereinfachen wird die Wahlmöglichkeit für alle Ausgabedateien, für die nicht alle Eingabdateien vorhanden sind durch ausgrauen unterbunden.
Wenn für eine Rate Bestands- und Bewegungsdatei vorhanden ist, dann wird geprüft, ob die Jahresbereiche Bestand und Bewegung zusammenpassen. - Methodenassistent
Bei der ersten Maske gab es viele Bausteinkombinationen, bei denen nach Abschluß der Maske eine Fehlermeldung wie z.B. "ungültig M1, B1, K0" erschien und die Eingabe korrigiert werden musste. Jetzt ist dies nur noch in einem einzigen Fall "Bei A1 oder B1 darf nicht gleichzeitig M0, N0 sein" notwendig. - Reporting
- Unterstützung reft2010.csv, reft2011.csv, ...
- Unterstützung leerer Gebiete in Ausgangs-gem-Datei
- ahk 1:
in der letzten Lenkungsgruppensitzung wurde ja darüber diskutiert im Methodenassistenten bei Schritt 1 die Menüführung zu ändern. Aktuell ist es so, dass bei den ersten drei Optionen die Art der Prognose (natürliche oder mit Wanderungen) und bei den nächsten Optionen die Anpassung der Eckwerte (Zuzug oder Wegzug oder beides) festgelegt werden. Wobei es bei der Handhabung so darstellt, dass sich beim Anklicken der Optionen die Texte verändern, also nicht wie sonst: Anklicken heißt Entscheidung für das was dort steht, sondern Anklicken bedeutet eine andere Ausprägung des Bausteins. Für den Anwender wird das aber zu Verwirrungen führen, wir sollten deshalb in der nächsten LG-Sitzung unbedingt über die Gestaltung von Menü Schritt 1 sprechen. Hat es eigentlich immanent eine Bedeutung, dass die Options Felder ansonsten rund, bei diesen ersten drei Feldern eckig sind? Ein Möglichkeit die Menüführung plausibler zu gestalten wäre aus meiner Sicht das Erweitern der Felder folgendermaßen:
mit entsprechender "Ausgraulogik"! Wäre das programmiertechnisch machbar?T1 Natürliche Prognose T2 Prognose mit Wanderungen A0 ohne Anpassung Wegzug A1 mit Anpassung Wegzug B0 ohne Anpassung Zuzug B1 mit Anpassung Zuzug Im Schritt 4: Baustein Bevölkerungsgruppenwechsel, steht bei W1 "gegliedert usw. nach ...", hier wäre es aus meiner Sicht stimmiger wenn z.B. "W1 mit Bevölkerunggruppenwechsel" stehen würde, wie bei anderen Bausteinen, z.B. Binnenwanderung, Neubautätigkeit etc. (erledigt)
- ahk 2:
zur Menüführung in Schritt 1 - Festlegen der Außenwanderung haben wir uns noch einmal Gedanken gemacht, ohne allerdings zu wissen, was programmtechnisch "hinter den Kulissen" noch so abläuft und möglich ist. Es geht also lediglich um den Anwender, der klare, eindeutige Vorgaben braucht. Im mitgeschickten pdf ist ein Vorschlag, wie man die Texte (und nur die Texte)zu den einzelnen Optionen verändern könnte, hinterlegt sind ja immer noch die ausführlichen Beschreibungen zu den Bausteinen mit den Buchstaben und den Ausprägungen! wib - erledigt - Vorschlag hst - erledigt, beinhaltet Umbenennung der Bausteine T1/T2 in T0/T1
- Vorschlag 2 hst
- Verschiebung NTYA sieht erstens besser aus und zweitens passt
die Angabe zu NTYA besser zu den Bausteinen A, B, C und K und als
zu M, weil es sich da um die Wanderungen und nicht den Bestand
handelt
wib: erledigt - Überlegungen wib
Anliegen/Frage bezüglich der Kommentarzeilen in den Dateien: Aktueller Stand bei der Erzeugung der Eingabedateien ist der, dass bei den Makrodateien die Spaltenüberschriften ausgegeben werden und bei der Ratenberechnung dann die verrechneten Jahre, Datum, Uhrzeit SIKURS-Version usw. Glättet man dann, verschwinden diese Kommentare zum Ursprung und es wird Breite Gleitfenster, Erstelldatum etc. kommentiert. D. h. in den schließlich verwendeten Dateien findet sich nichts zur "Biographie" der Datei. Gibt es eine Möglichkeit die Historie der Eingabedaten zu bewahren, um in der endgültigen Eingabedatei den kompletten Werdegang nachvollziehen zu können? Vielleicht können Sie bis zur Lenkungsgruppensitzung darüber nachdenken ob das machbar ist? (Macht es überhaupt Sinn? Oder sind die Texte dann eventuell viel zu lang und unübersichtlich? )
Konzept:
Wenn bei
Optionen/Systemeinstellungen/CSV/Kommentarzeilen in Ausgabedateien
(*) Datum / Spaltenname oder
(*) Datum
ausgewählt wird, dann enthält die Ausgabedatei die Kommentare der
Eingabedatei, sowie einen neuen Kommantar mit Datum.
strb2016.csv: #SIKURS-Eingabedaten aus Makrodateien, Ausgabe strb #D:/trunk/sikurs/extra/Beispiel/DST/anonym/makro/sterb_2015.csv #[2015] #D:/trunk/sikurs/extra/Beispiel/DST/anonym/makro/baby_2015.csv #[2015] #D:/trunk/sikurs/extra/Beispiel/DST/anonym/makro/bestand_2014.csv #[2014] #SIKURS 10.2.0.636: Dienstag, 25. Oktober 2016 16:37:10 #manuell glätten D:/trunk/sikurs/extra/Beispiel/DST/anonym/bprog/strb2015_roh.csv #SIKURS 10.2.0.636: Dienstag, 25. Oktober 2016 17:01:05 #Typ Sterberaten;Bevölkerungsgruppe;Geschlechtsgruppe;Altersgruppe;Rate 1;1;1;00;0,0021 ...Von der Erweiterung betroffen sind
- Berechnen
- Hadwiger Synthese (Ausgabe mehr Kommentare nach fruc)
- Glätten (aufsammeln Kommentare Eingabedatei)
- Glätten über das Alter
- Manuelles Glätten über das Alter
- Glätten über Alter und Jahr
- Glätten Rohdateien im Prognoseverzeichnis
bei der Erzeugung der Makrodateien aus DST- Bevölkerungsbewegung sind Probleme aufgetreten. Mit Feldposition 250 - NEUB kann mit Informationen aus anderen Quellen eine Adresse als Neubau markiert werden. Zum Teil wurde dieses Feld aber auch von Anwendern genutzt, um irgendwelche Informationen zu hinterlegen, sind aber in diesem Feld Nennungen > 0 vorhanden, wird der Datensatz als Neubaubezug aus dem Innenraum ausgewiesen und der Satz fällt für die weitere Verarbeitung, z.B. die Erstellung der Datei aussenzug weg. In einem Fall war es extrem: es wurden überhaupt keine Aussenzuzüge (gilt wahrscheinlich für alle Wanderungen?) ausgegeben. In der Lenkungsgruppe sollten wir deshalb prüfen wie solche Fälle aufgefangen werden können!
In der Beschreibung Statiskdatensatz Bevölkerungsbewegungen steht:
NEUB 250 01 I Adresse ist Neubau(39)
(_) kein Neubau oder Feld nicht versorgt
(39) Hier kann mit Informationen aus anderen Quellen eine Adresse markiert werden, die im Berichtsjahr bezugsfertig geworden ist.Demnach kann NEUB 3 Werte annehmen:
_ nicht versorgt
0 kein Neubau
1 Neubau
den aktuellen Werte des Merkmals NEUB kann man prüfen
Haushalte/Anzeige/Start
[1-* ] Satznummern
[{ $bb->{NEUB}++; 1 }] Satzinhalt
mit beispielhafter Ausgabe ('4' kommt 13 mal vor, 'Q' 7 mal)
{ 4 => 13, Q => 7 }
Lösung:
Neue Checkbox in Eingabmaske
[ ] Ableitung Neubauerstbezug aus dstbew
Attina Mäding:
Nun habe ich noch einmal zwei Fragen zur Altersberechnung bei der Erstellung der Makrodateien in SIKURS und zwar zu folgender Anmerkung auf der Hilfeseite: file:///C:/Sikurs_10_1/html/d/00Hilfe/10Tools/00Eingabedaten/00TkRate.htm
(*) Das Alter wird nicht wie beim Bestand aus A01, sondern aus der Differenz der Jahresanteile von Z02 und P01 (AG = substr(Z02,0,4)-substr(P01,0,4)) berechnet, weil A01 in der Bewegungsdatei das Alter zum Zeitpunkt des Abzugs ist, SIKURS aber das Alter zum 31.12. benötigt.
Für Tests kann zwischen Z01, Z02 gewählt werden.
- Soweit ich ermitteln konnte ist in unseren Bewegungsdateien A01 das Alter zum Zeitpunkt des Ereignisses (Z02). "Abzug" ist hier missverständlich, wenn nicht gar falsch, oder?
- Wenn Sikurs das Alter zum 31.12. benötigt, dann kann es doch weder mit Z01 (Verarbeitungsdatum) noch Z01 (Ereignisdatum) das Alter errechnen, sondern muss das Geburtsdatum (P01) in Bezug zum 31.12. des jeweiligen Jahres setzen.
- Geschieht das und ist in der Hilfe nur falsch dargestellt oder
- muss ich die Bewegungsdateien vorab bearbeiten und Z01 auf den 31.12. des jeweiligen Jahres setzen oder
- benötigt Sikurs doch das Alter zum tatsächlichen Verarbeitungsdatums (Z01)?
wib:
Die Altersberechnungsmethode ABM=1 oder 2 ergibt sich aus der Startmaske
[1 ] Altersberechnungsmethode (1: Z01, 2: Z02)Auszug aus dem Programm zur Verarbeitung von dstbew:
/* svn diff -r85 dstbew.cpp
* 85 A01 zu ungenau
* 86 Z01-P01
* 87 Z02-P01
*/
// Z01 Verarbeitungsdatum (JJJJMMTT) (default)
// Z02 Ereignisdatum (JJJJMMTT)
// Z01/2_JJJJ-P01_JJJJ nur Jahr wegen Stichtag 31.12 für gem-Datei
// Prüfung, ob Felder Z01/Z02, P01 versorgt
Feld& _Z = (ABM == 2) ? _Z02 :_Z01;
if (_Z.all(line) || _P01.all(line))
Log("P01 oder Z01/Z02 nicht versorgt\n");
int ag = _Z.integer(line, 0, 4) - _P01.integer(line, 0, 4);
if (ag < 0)
Log("Alter %d negativ\n", ag);
Fortentwicklung Benutzerhandbuch
sinnvoll wäre Review Dokument durch
- hst mit Prüfung der methodische Anteile und Abschluß methodischer know-how Transfer
- wib mit Prüfung technischer Anteile und Ermittlung möglicher Verbesserungsvorschläge (Hilfe, GUI, Funktionalität)
m,h: Terminologie-Wanderungen v3
wib: für Handbuch (bhb.pdf) und Prognoseprotokolle (C++ Quellcode + datadict.xml)
und Excel-Bausteinkombinationsbeispiele
Beispiel:
Im Benutzerhandbuch (bhb.pdf) ist z.B. Seite 30, Beschreibung BEW zu ändern:
Feld 8: Außenwegzug ohne Rückbauendauszug (WA) -> Außenauszug ohne Rückbauendauzug (AA)
... analog einige weitere Felder
Im C++ Quellcode und datadict.xml Umbenennen DG4WA -> DG4AA und Protokolltest wie bei Benutzerhandbuch
Weitere Beispiele:
| alt | neu | dim | Text |
|---|---|---|---|
| DG4WA | DG4AA | GZ BG GG AG | Außenauszug |
| DG5WA | DG5AA | GZ TYA BG GG AG (besser TYA GZ ...) | Außenauszug |
| DR4WA | DR5AA | TYA QWA BG GG AG | Außenauszug |
| PR4WA | DR5AA | TYA QWA BG GG AG | Außenauszugsrate |
Begriffsänderung:
(s) Hauptmaske/Einwohner/Prognose Standardprognose -> Pauschalprognose ?
Bei der Prognose kann häufig beobachtet werden, dass die Altersgruppe 99 über die Jahre sehr stark zunimmt.
Um zu beurteilen, ob dies realistisch oder ein Fehler ist, sollte man folgendes versuchen:
Die aus dem Statistikdatensatz abgeleiteten Makrodateien enthalten Altersgruppen 0-999.
Bei Berechnen SIKURS-Eingabedaten aus Makrodateien wählen Sie Option:
[1] undefinierte Werte [100 (oder 110)] AltergruppenIn der Ausgabedatei strb suchen Sie dann nach Zeilen mit Werten:
1001;1;1;97;"undef" 1001;1;1;98;999
"undef" oder eine fehlende Atersgruppe kommt zustande, wenn in
einer Altersgruppe weder Sterbefälle noch Bestand vorhanden sind.Inf (∞) wird ausgegeben, wenn in einer Altersgruppe
Sterbefälle aber kein Bestand vorhanden ist (damit handelt es sich um einen
Datenfehler, da Sterbefälle ohne Bestand nicht möglich sind).Visualisieren Sie die berechnete Sterberate (und amtliche Sterberaten) mit SIKURS-Hauptmaske/Extras/Eigene Scripts/Start/gomperts.pl als Gompertz-Diagramm, um zu entscheiden, ob sie die fehlenden Altersgruppen durch Glätten oder Interpolation mit Nachbarwerten schließen wollen.
Damit kann man eine Variantenprognose für die Anzahl Altersgruppen machen:
- Untervarianten für das Glätten der Sterberaten:
- nicht glätten
- glätten AG 0-99
- AG 0 beim Glätten ausschließen, da diese viel größer als von AG 1 ist.
- AG 99 beim Glätten ausschließen, da diese aus den AG 99-999 berechnet werden, stattdessen evtl. festen empirischen Wert m: 0,4, w: 0,3 verwenden
- Untervarianten für das Glätten der Sterberaten:
- nicht glätten
- glätten
- Sterberaten ab 90 < S90+
(Ursache: z.B. zu geringe Fallzahl bei der Berechnung) - Sterberate 99: männlich S99m < 0,4, S99w weiblich < 0,3
(Ursache: z.B. Reduktion durch Glättung) - Notiz:
!option($MRDT 1)
MRDT nach Gompertz außerhalb [MRDTmin (7) .. MRDTmax (9)]
constant.csv und können in strb____.csv durch#! constant($S90 0,07) constant($S99m 0,5) ...überschrieben werden.
Für eine Prüfung könnte man einen Norm-Indikator und eine Toleranz
z.B. +/- 10% oder einen Indikator mit Untergrenze und Obergrenze vorgeben.
Der Indikator sollte nach Geschlecht aber nicht nach Bevölkerungsgruppe
gegliedert sein.
- Lebenserwartung, z.B. m: [70 .. 80], w: [75 .. 90]
- Gompertz-Koeffizienten, z.B. S30 m: [0.0005 .. 0.0015], w: [0.0003 .. 0.001], MRDT: [0.7 .. 0.9]
- Norm-Sterberaten mit 100 Altersgruppen und ein Anpassungsverfahren bei mehr als 100 Altersgruppen
(plot commands)
Für eine Variantenprognose sind vergleichende Zeitreihen von Indikatoren wie Gesamtbevölkerung (BS), Jugendquotient (JQ), Altenquotient (AQ), Zusammengefasste Geburtenrate (ZGZ/TFR), Lebenserwartung (LE), ..., hilfreich.
Extras/Eigene Scripts/Start/varianten_indikator.plnutzt für das gewählte Variantenverzeichnis
entenhausen
die csv-Dateien des Tools Indikatoren:.../entenhausen/high/v/ind/BS.csv .../entenhausen/medium/v/ind/BS.csv .../entenhausen/low/v/ind/BS.csvund führt diese zusammen:
.../entenhausen/varianten_ind/BS.csv: #Jahr:Gebiet;Bevölkerungsgruppe;Geschlechtgruppe;high_v;low_v;medium_v 2017;10;1;1;102610;102610;102610 ... 2026;10;1;1; 99100;102690;113221und plottet die Indikatoren (z.B. Bevölkerungssumme BS.csv)
Diese Plots kann man modifizieren:
Visualisierung/Zeitreihen/X-Y-Plot .../entenhausen/varianten_ind/BS.csv [1 ] X-Achse [ ] Schlüssel [ ] Geschlechtsgruppe [5 7 6] Wert [ ] Auswahlfilter Legende [Variantenprognose Entenhausen ] Titel [Jahr ] x-Achse [Einwohner ] y-Achse [ ] Referenzdatei Schlüsselwerttexteum z.B. Auswertungen in einer anderen Differnzierung wie z.B. Gebiet, Typ, Bevölkerungsgruppe, Geschlechtsgruppe vorzunehmen.
Will man z.B. nach Gebiet differenzieren, so wird man entweder
- pro Gebiet (Spalte 2 in BS.csv mit den Gebietschlüsseln 101, 102, ...) einen Plot über die Varianten (wie oben für den Untersuchungsraum) starten
[1 ] X-Achse [ ] Schlüssel [ ] Geschlechtsgruppe [5 6 ] Wert [#2 == 101 ] Auswahlfilter für die Gebietsschlüssel 101, 120, 201, ...
- Pro Variante (Spalte 5, 6 in BS.csv) einen Plot über alle Gebiete starten
[1 ] X-Achse [2 ] Schlüssel [ ] Geschlechtsgruppe [5 ] Wert für die Spalten 5, 6 [ ] Auswahlfilter ... (*) Linienplot Absolutwerte [linespoints ] ... [0:16000 ] y-Wertebereich (gleich für alle Varianten)
(*) Flächenplot je Wert
Hinweise:
Die Prognose aller Varianten (einzeln oder als Sammelprognose) muss berechnet sein mit:
- dem gleichen Prognosezeitraum 2017 bis 2026
- den gleichen Ausgabedateien gebam, bew haben
- zr_gem muss erzeugt werden
- Indikatoren müssen berechnet werden
(Einwohner/Prognose/Berechnen/Befehle
nach der Prognose
indikator; # siehe roadmap 106
zr_gem.csv vorhanden sind, werden diese
zu varianten_zr_gem.csv zusammegeführt.
Wenn man die Indikatoren mit
Befehle/nach der Prognose
indikator(refGKZ => 1, refTYG => 1, refTYS => 1, dir => 'ind_grob');mit dem Verzeichnisnamen
ind_grob berechnet, muss man diesen
Namen invarianten_indikator.pl:
[ind_grob ] Name Variantgenverzeichniseintragen.
Siehe auch Verzeichnis
variant bei den mitgelieferten
Beispielen beispiel.zip (Siehe ?/Beispiel-Eingabedaten)
Utz Lindemann: Bei SIKURS-Eingabedateien aus Makrodateien die Ausgaben ins Textfenster der Hauptmaske zusätzlich in eine Protokoll- oder Log-Datei schreiben (und über einen neuen Menüpunkt "Protokoll SIKURS-Eingabedaten aus Makrodaten" zugänglich machen)
Das Sichern der Textfenster-Ausgaben könnte man auf weitere Tools (Eingabedaten Berechnen/Glätten/Dynamisieren und evtl. Ergebnis Zeitreihen) ausdehnen.
Mit Optionen/Systemeinstellungen/Allgemein
[ ] Lösche Textfesterkann man die Ausgaben im Textfenster behalten, bei Bedarf Teile mit Copy/Paste retten oder
<F2> Textfenster als Datei prot.htm abspeichern<Entf> Textfenster löschen.
Bei Makrodateien aus Statiskdatensatz wird geprüft, ob es ein altes
Protokoll gibt und gefragt, ob man es sehen will.
Ein neues Protokoll im html-Format ersetzt die Datei log.txt und
die Ausgabe im Protkollfenster.
ahk: Beim Zeitreihentool bildet man öfters verschiedene Aggregate zu den Altersgruppen oder Gebieten. Die unterschiedlichen Aggregierungsvarianten stehen dann in einer Referenzdatei mit mehreren Spalten und in der zr_Ausgabe stehen immer nur die Nennungen 1, 2, 3, usw. Hier wäre es hilfreich eine Protokollierung zu haben, vielleicht sogar in den Kommentarzeilen der Ergebnisdatei mit den entsprechenden Informationen zum Aggregat, Pfad zur Referenzdatei, welche Spalte der Referenzdatei angesprochen wurde...
wib: Bei Einwohner/Prognose/Berechnen
[v] Aggregation Zeitreihe
erscheint im Textfenster der Hauptmaske das Protokoll
Aggregat Zeitreihe Aggregation über Jahr: keine Gebietskennzeichen: reftyp 1 3 Bevölkerungsgruppe: keine Geschlechtsgruppe: keine Altersgruppe: alle Ausprägungen < reftyp > zr_gem.csv < gem2009.csv < gem2010.csv < [2009..2010][11..31][3..3][2..2][0..2] > [2009..2010][1..3][3..3][2..2][1..1] 30 Eingabedatensätze + 3 Kommentarzeilen 6 Ausgabedatensätze + 1 Kommentarzeilen, 0,137sDie Ausgabe
Aggregation über wurde in Ergebnis/Zeitreihe ergänzt
zum Test empfehle ich:
Hauptmaske/Optionen/Systemeinstellungen
[3] Protokollumfang Tools
Hauptmaske/Ergebnis/Zeitreihe/Start
Aggreagtion über
... diverse Aggregate, z.B. refag 1 3
Anzeige
[v] Editor
[OK]
jetzt kopieren sie das Protokoll aus dem Textfenster der Hauptmaske
in die Ausgabedatei zr_gem.csv
Jetzt kann man beurteilen, ob es Sinn macht, sehr viele Informationen
als Kommentar in die Ausgabedatei zr_gem.csv zu übernehemen.
Alternativ könnte man den Namen der Ausgabedatei vom
Benutzer wählen lassen (mit Voreinstellung wie jetzt), z.B.
zr_gem_jugend.csv und die Informationen über
die Aggreagtion in eine Datei zr_gem_jugend.txt schreiben.
Im Protokoll und in Spaltenüberschriften gibt es bei Neubau, Rückbau, Sondergruppen ca. 10 Texte wie:
DG4OI - Innenauszug ohne Rückbauendauszug
Für Anwender könnte es verständlicher sein, je nach Baustein
| E0 | Innenauszug |
|---|---|
| E1 | Innenauszug ohne Rückbauendauszug |
| E2 | Innenauszug ohne Rückbauendauszug |
m,h: Konsistente Aufteilung Außenzuzug und Rückbauendauszug auf die GKZ eines Binnentyps
wib: TYZZA ist nicht mehr unabhängig, sondern muss gleich TYB oder
eine Verfeinerung von TYB sein.
Die Berechnungen mussten stark umstrukturiert werden.
Erweiterung von blackbox- und regression-test
- Aktualisierung Ablaufdiagramm und zugehöriger Texte bhb (m-hst)
(insbesondere für 50, 51, 72, 75) - Schwachpunkte
Bei der Außenwanderung werden - wie bei der Binnenwanderung - durch Planungsmaßnahmen Wanderungsbewegungen ausgelöst, die im "üblichen" Wanderungsgeschehen nicht enthalten sind. Beim Außenauszug handelt es sich um die vom Rückbauendauszug ausgelösten Wanderungen, bei denen die Beteiligten nicht im Untersuchungsgebiet verbleiben sondern ihren neuen Wohnsitz außerhalb des Untersuchungsgebietes suchen.
Wie der Binnenauszug so wird auch der Außenauszug aus den Gebietseinheiten im SIKURS-Programm auf der Basis gebietstypischer Raten ermittelt. Wenn Raten einer Bewegungsart zweimal auf denselben Ausgangsbestand bezogen werden, wird eine bestimmte Anzahl Personen zweimal am Wanderungsgeschehen beteiligt und dadurch das Wanderungsvolumen überhöht. Diese Ungenauigkeit/Verfälschung wird bei der Binnenwanderung vermieden, indem vor der Anwendung der Binnenwanderungsraten zur Ermittlung der "üblichen" Binnenwanderung die Ausgangsbevölkerung reduziert wird um die auf die Planungsmaßnahmen zurückzuführende, zusätzliche Wanderungen. Bei der Binnenwanderung sind dies die Neubauerstbezieher, die aus dem Untersuchungsgebiet stammen und die Rückbauendauszieher, die ihren neuen Wohnsitz im Untersuchungsgebiet finden. Analog zur Binnenwanderung soll daher vor der Berechung des "üblichen" Außenwegzugs die Ausgangsbevölkerung reduziert werden um die vom Rückbauauszug ausgelösten Außenwegzüge.
wib: siehe 050 Absicherung Binnenwanderung
Als Vorstufe zu 076 wurde das Tool Indikatoren erweitert:
- Ausgabe
- PA.csv Perzentilalter 10%, 20%, ..., 90%
- QA.csv Quantilalter 1/n, 2/n, ..., (n-1)/n; n wählbar
- neues Kapitel Bewegungsindikatoren
zu den in bew.csv vorhandenen Spalten ab Sterbefälle z.B. "Außenwegzug ohne Rückbauenauszug", "Bevölkerungsgruppen nach" werden die Indikatoren Summe, (Durschnitts, Median, Modal)-alter Jugend/Altenquotient, Sexualproportion, Ausländeranteil, ... berechnet.
Die Ausgabe erfolgt im Protokoll mit Zwischenüberschrift pro Bewegungsspalte und in csv-Dateien, so dass die Zeitreihen mit Visualisierung/Zeitreihen/x-y-Plot geplottet werden können. - Indikatoren aus Statistikdatensatz Bestand und Bewegung
(bei Optionen/Systemeinstellungen
[1] Einschalten experimenteller Programmfunktionen)
Hauptmaske/Visualisierung/Indikatoren/Statistikdatensatz/berechnen
berechnet Indikatoren wählbarer Differenzierung, Ausgabedatei indikator.csv.
Die vorhandenen Indikatoren müssen überprüft, und evtl. weitere benötigte Indikatoren festgelegt werden. - Hauptmaske/Visualisierung/Indikatoren/Makrodatei
Indikatoren einer auszuwählenden Makro-Datei oder gem-Datei
Diese Indikatoren sollten mit obigen Indikatoren übereinstimmen.
- Vergleich 2 csv-Dateien gleichen Namens mit Excel
Wenn man 2 Prognosen mit 2 ini-Dateienv1.iniundv2.inirechnet, dann entstehen 2 Ausgabedateien...\v1\bew.csv ...\v2\bew.csv
wib: Eine Excel-Instanz kann aber keine 2 Dateien gleichen Namens öffnen.
Lösungen- 2 Excel Instanzen starten (über Windows Start-Button Suchfeld: excel)
- mindestens eine Datei von Hand umbenennen
bew.csv -> bew_v1.csv
Hauptmaske/Einwohner/Prognose/Berechnen/?
suche Link: Variantenprognose
Vergleich von csv-Dateien gleichen Namens mit Excel - Abrundung Tools
- Option "Logarithmischer y-Wertebereich"
- Hauptmaske/Visualisierung/Zeitreihen/X-Y-Plot
wurde für Sterberaten um die Option "Logarithmischer y-Wertebereich" erweitert:[2 ] x-Achse [1 ] Schlüssel [3 ] Wert (*) Linienplot Absolutwerte [steps ] [0:0.5 ] y-Wertebereich
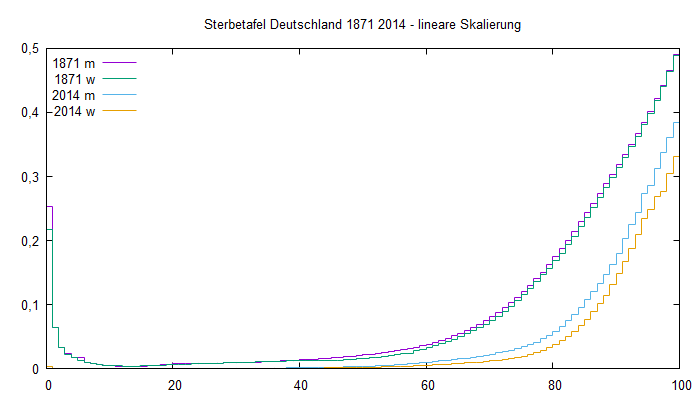
[1e-5:1 log ] y-Wertebereich
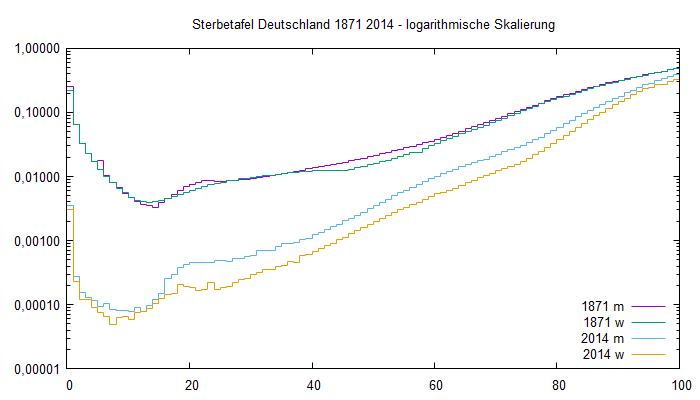
- Extrapolation
- SIKURS-Geburtenraten mit Hadwiger-Funktion visualisieren
- Extras/Eigene Scripts/Start/Weibull
- Manuelles Glätten
- Dendrogramm Clusteranalyse
- Hauptmaske/Visualisierung/Zeitreihen/X-Y-Plot
- Dokumentation Eingabeparameter in Kommentar Ausgabedatei
- Ergebnis/Zeitreihe
- Unterstützung reftyp Dateien mit Verkürzung Gebietskennzeichen
#!cut(4)
- Unterstützung reftyp Dateien mit Verkürzung Gebietskennzeichen
- Einwohner/Prognose/Berechnen/Parameter/Aggregation Zeitreihe sowie
- Wahlmöglichkeit Ausgabedatei (default
zr_gem.csv) - Aggregationsfunktionen (Entsprechung Ergebnis/Zeitreihe]
entferne Merkmal/5 (int($i/5))^99 (min($i,99))reftyp 1 0- Abbildung Gebietskennzeichen in Gebietsnummer
- Fehlermeldung bei fehlendem Schlüssel in reftyp
- Unterstützung reftyp Dateien mit Verkürzung Gebietskennzeichen
#!cut(4)
- Wahlmöglichkeit Ausgabedatei (default
- Eingabedaten/Dynamisieren/Regression
- Ergebnis/Zeitreihe
- entferne unnötige Parameter
[100 ] Anzahl Altersgruppenin
SIKURS Geburtenraten nach Vorgabe Zusammengefasste Geburtenrate und
SIKURS Sterberaten nach Vorgabe Lebenserwartung
- Option "Logarithmischer y-Wertebereich"
- Clusteranalyse
Verarbeitung von UTF-8 Eingabedateien.
Verbesserung Plot-Ausgabe Dendrogramm
ahk: Außentypen werden außerhalb der eigentlichen Ratenberechnung ermittelt und schon bei der Berechnung der Makrodateien verwendet. Die Frage in der Wartungsgemeinschaft war die, ob sich nicht auch die Außentypen über eine Referenzdatei zusammen mit der Berechnung der Raten und Quoten realisieren lassen.
Bei dieser Erweiterung sollte aber die jetzige Vorgehensweise mit der Ermittlung der Außentypen über reftya bei Berechnung der Makrodateien bestehen bleiben.
wib: Lösung:
- Berechnen/Makrodateien
[-3 ] Anzahl signifikante Stellen W40/W41
"-3" bedeutet, dass bei fehlender Datei reftya 3 Stellen W40/W41 in die Makrodateien als Außentyp ausgegeben werden - Berechnen/SIKURS Eingabedaten aus Makrodateien
Eine Datei reftya.csv im Verzeichnis der Makrodateien, führt zu einer Abbildung der Außentypschlüssel in aussenzuzug und aussenwegzug in Außentypnummern.
wib 12.11.2023: offenes Problem:
Wenn der Anwender sowohl
- im Verzeichnis
dst - als auch im Verzeichnis
makro
reftya.csv benutzt, dann ist in den Makrodateien
W40 bereits in den Außentyp abgebildet und das Programm meldet Warnungmissing keys in reftya: (1, 2, 3, 4, 5)Eine mögliche sinnvolle Hilfe wäre eine Warnung auszugeben:
bitte .../makro/reftya.csv entfernen, da W40 in den Marodateien bereits auf Außentypen abgebildetwenn in der Datei:
sikurs.ini: [RATEN] W40DST=3
W40DST einen positiven Wert hat und die Datei .../dst/reftya.csv existiert(bei
W40DST=-3 oder bei fehleder .../dst/reftyp.csv
ist die die Datei .../makro/reftya.csv o.k.
Auch ganz andere Lösungen wären denkbar, z.B.:
- Es gibt nur eine Datei
reftya.csvund zwar im Verzeichnismakro
Das Programm "Makrodaten aus dst" merkt sich inmakro/raten.ini, obW40in Außentypen umgeschlüsselt wurde; das Programm "Raten aus Makrodaten" verzichtet dann auf die Nutzung vonmakro/reftya.csv - In den Makrodateien
aussenwegzug aussenzuzugist die SpaltenüberschriftAußentyp. Wenn man bei der Ableitung diese Dateien je nach Abbildung mitreftyadie Spalte mitAußentypoderAußengebietsschlüsselbenennen würde, dann könnte mn bei der Berechnung der Raten prüfen, ob eine weitere Abbildung mitreftyaSinn macht (falls Systemeinstellungen/CSV/Spaltennamen ungleich 0 ist)
Bei den Neubautypen gibt es noch folgendes Problem:
Ursprünglich wurde in die Datei neubaubezug in Spalte 2 der Teilschlüssel aus R02,
also das Gebietskennzeichen übernommen,
das dann bei der Erstellung der Raten über reftyp
in den Neubauerstbeziehertyp gewandelt werden konnte.
Ich habe aber eine Notiz gefunden:
// Lindemann Lenkungsgruppe 28.11.2016 NEUB als Typ übernehmend.h. in neubaubezug wird der Inhalt des Feldes NEUB aus dstbew geschrieben:
NEUB 250 01 Adresse ist Neubau41 (_) kein Neubau oder Feld nicht versorgt
Hier kann mit Informationen aus anderen Quellen eine Adresse markiert werden, die im Berichtsjahr bezugsfertig geworden ist
d.h. wenn in NEUB=" " oder "0", dann ist es kein Neubau, bei Neubau hat sie anscheinend oft den Wert "1". könnte aber auch Werte "2" bis "9" haben?
Ich nehme an, Herr Lindemann empfahl 2016 einen "vernünftigen" Neubautyp in NEUB
von dstbew manuell einzupflegen (, was ich nur für
"Statisitkdatensatzprofis" empfeheln würde).
Wenn die der Fall ist,
dann muss ich bei der Erstellung der Neubau-Raten-Dateien auf die Abbildung
über reftyp verzichten (vorläufig eingebaut)
ansonsten
die Änderung "Lindemann 28.11.2016" zurücknehmen
oder
Der Anwender kann wählen
- Makrodateien aus Statistikdatensatz
[2 ] Ableitung Erstbezug Neubauten (0: nein, 1: mit R02, 2: mit NEUB)
- SIKURS Eingabedaten aus Makrodateien
[2] Neubaubezieherquoten (0: nein, 1: über reftyp, 2: mit NEUB)
ahk: In der dst-Bewegungsdatei gibt es das Feld Anst /Spalte 267: 0=Adresse ist Wohnheim, 1=Adresse ist weder Heim noch Anstalt, 2= Adresse ist Anstalt/Pflegeheim. Aktuell haben wir nur die Möglichkeit Raten mit dem Nettobestand berechnen zu lassen, korrekt wäre aber ein Erstellen der Raten auch mit den reduzierten Bewegungen. Wir müssen über eine Umsetzung in der nächsten Lenkungsgruppe diskutieren, um Anwendern aber die Möglichkeit zu geben, stimmig mit den Nettobewegungen zu rechnen, sollten wir in einem 1. Schritt in den Laufzeitparametern eine Option "Ausgabe der Bewegungsdateien ohne Anstaltsbevölkerung" aufnehmen. Für den Anwender sollte in der Kommentarzeile der erzeugten Datei dies vermerkt werden; prinzipiell sollten im Kommentar alle verwendeten Filter protokolliert werden.
siehe auch Nettobestand
ahk: Bei der Berechnung der Raten, gibt es die Optionen
- In Bewegungsdatei Gebiete auf Typen abbilden
- In Bestandsdatei Gebiete auf Typen abbilden
Wenn nicht müsste man in der Lenkungsgruppe nochmal darüber diskutieren, ob beide Optionen bleiben sollen oder wie man an der Stelle die Anforderungen modifizieren könnte. Wir hätten schon Ideen.
s,w: auf eine Option
- Gebiete auf Typen abbilden
(siehe roadmap 044, 059)
!AUSGABE_GSTROM n(siehe Einwohner/Prognose/Berechnen/?
Überschrift "Notiz", Link "trace items")
Beispiel:
!AUSGABE_GSTROM 5Ausgabe
gstrom_roh.csv
mit (unsortierten) Binnenströmen zwischen den Gebieten und
gstrom.csv mit den auf Binnentypen aggregierten
Binnenströmen indentisch mit Datei strom.csv.Die Information Binnenwanderung zwischen den Gebieten hat folgende Nachteile (siehe roadmap 044):
- bei sehr vielen Gebieten kann die Datei sehr groß, die Laufzeit der Prognose sehr lange werden
- die Strompyramiden zwischen Gebieten mit schwacher Wechselwirkung werden dünn besetzt sein, bedürfen also für statistisch relevante Aussagen weiterer Aggregation (z.B. über Altersgruppen oder räumliche Aggregate).
gstrom_roh.csv mit
strom.csv, sowie
bew.csv mit dem Spalten
Binnenwegzug, Binnenzugug, Innenauszug, Inneneinzug
(ebenfalls differnziert nach Gebieten)
durch Befehle nach der Prognoseblackbox_test 1, 1;erfolgreich getestet.
Integration in die Benutzeroberfläche:
Einwohner/Prognose/Berechnen/Ausgabe
[2 ] Binnenwegzugsmatrix
0: keine
1: differenziert nach Binnentyp (wie jetzt strom.csv)
2: differenziert nach Quell-Gebiet und Zieltyp (gstrom_weg.csv)
3: differenziert nach Quell-Typ und Ziel-Gebiet (gstrom_zu.csv)
4: 2+3
5: differenziert nach Quell- und Ziel-Gebiet (gstrom.csv)
gstrom.csv wird am Programmende sortiert.Analog wurde für die Außenwanderungsmatizen
zuzug.csv wegzug.csv neba.csv reaa.csv die Option
Differenzierung nach Typ oder Gebiet ergänzt.
Für
- Visualisierung/Zeitreihen/Stromkreise
- Visualisierung/Pyramiden/Pyramiden in Wanderungsmatrizen
Kommentare in csv-Dateien sollen die Arbeit des Anwenders erleichtern, können aber beim Einsatz von Folgeprogrammen Probleme verursachen.
Deshalb gibt es folgende
Optionen/Systemeinstellungen/CSV
[v] Byte Order MarkAusgabe UTF-8 Kennung (BOM) in csv-Ausgabedateien
[v] Verwende Umlauteoder wandle "ä" in "ae" etc.
Was sind die gewünschten Voreinstellungen für beide Optionen ?
Solle Ausgabe BOM default sein ?
Sind beide Optionen an, fragt z.B. Excel beim Öffnen einer csv-Datei nach der Codierung (utf8) und Spaltentrennzeichen (;).
Sind beide Optionen aus, ist die Codierung "plain ASCII" und somit sowohl UTF-8 als auch ISO-8859 Latin1.
Alternativ kann man in Systemeinstellungen/CSV
[ 1] Kommentar mit DatumKommentarzeile mit Datum und Zweck der Datei
[ 0] Kommentar mit Datumdie Kommentarzeilen mit Datum komplett ausschalten.
s,w: Die Bausteine P1 und P3 können gestrichen werden, stattdessen kann man P2 und P4 verwenden mit Untergrenze = Zielwert = Obergrenze in den Dateien eckgem und ecktyp.
Beispiel:
eckgem.csv für P1: 2020;1;101;123 eckgem.csv mit gleicher Wirkung für P2: 2020;1;101;123 2020;2;101;123 eckgem.csv wie oben in verkürzter Schreibweise: 2020;1..2;101;123 eckgem.csv wie oben in weiter verkürzter Schreibweise: 2020;*;101;123Arbeiten:
- Prüfe die Beispiele aus baustein, ob P2/P4 mit Untergrenze=Obergrenze
gleiches Ergebnis liefert wie P1/P3 mit Zielwert
Bei baustein/A1I1M1P1T1 wirdeckregnicht eingelesen, sondern auseckgemabgeleitet. Übertragung Verhalten auf P2, falls alle Unter- und Obergrenzen definiert und jeweils gleich sind. - Anpassen Testbeispiele und alte Prognosebeispiele
P1 eckgem.csv: ändern Spalte 2 von1in1..2P2 Methodenassistent: ändern P2 in P1 P3 ecktyp.csv: ändern Spalte 2 von1in1..2
Methodenassistent: ändern P3 in P2P4 Methodenassistent: ändern P4 in P2 - Anpassung Benutzerhandbuch
alt neu P0 P0 freie Entwicklung P1 Zielwerte Gebiete (eckgem) P2 P1 Unter-/Obergrenzen Gebiete (eckgem) P3 Zielwerte Binnentypen (ecktyp) P4 P2 Unter-/Obergrenzen Binnentypen (ecktyp)
Lenkungsauschuss 2018, keine Priorität
Bei den Dateien mit Außentyp (A) und Gebiet (G) / Typ (NEE, REA, QWA, ZZA) ist die Reihenfolge nicht konsistent
| Eingabe | ||
| NEUBAUZU | NEE | A |
|---|---|---|
| RUECKBAUWEG | REA | A |
| WEGV | G | A |
| WEGZ | QWA | A |
| ZUAQ | A | ZZA |
| ZUVL | A | ZZA |
| ZUVG | A | G |
| Ausgabe | ||
| NEBA | A | G/ZZA |
| REAA | A | G/QWA |
| WEGZUG | A | G/QWA |
| ZUZUG | A | G/ZZA |
gwegzug.csv wird der Index A an erster
Stelle benötigt, delhalb braucht das Programm zu Einlesen von
wegz000.csv die unnötige Hilfsmatrix PR4WA_.
Vorschlag ist die Anpassung der Eingabedateien an die Systematik der
Ausgabedateien, so dass A immer zuerst kommt
wird nicht gemacht, da für Anwender störend
Das Programm ist fertig, sobald eine Anleitung vorliegt, soll es den Anwendern zur Verfügung gestellt werden. Standardmäßig wird von SIKURS eine xml-Datei zur Beschreibung der gem-Dateien (2 Bevölkerungsgruppen, 2 Geschlechtsgruppen, 100 Altersjahre) mitgeliefert. Der Support wird von HHSTAT übernommen.
SIKURS-Hauptmaske/?/Hilfe/Suchen oder <Strg>f
testweise auf roadmap ausgeweitet
Die Layoutparameter von
Visualisierung/Pyramiden/Einzelpyramiden
[ ] Legende für Bevölkerngsgruppen anzeigen [BG ] Titel für Legende Bevölkerungsgruppen Legende und Farbe der Bevölkerungsgruppen [Deutsch ;rgb 'blue' ;0.4 ] 1 [Ausländer;rgb 'green';0.4 ] 2 Legende für Geschlechtsgruppen [m ] 1 [w ] 2wurden in die ini-Datei aufgenommen und werden auf für
- Visualisierung/Pyramiden/Pyramiden in Wanderungsmatrizen
- Prognose/Protokoll/Animierte Bevölkerungsprognose
- Glätten
- Reporting
[5 ] Anzahl Altersgruppen pro BalkenDarstellung von sehr dünn besetzten Pyramiden nach Aggregation von 100 auf 100/5=20 Altersgruppen (Beispiel mit 1, 2, 5, 10, 20, 25, 50 Altersgruppen pro Balken)
m,h: Zu prüfen ist, ob bei den unterschiedlichen Kombinationen die vorgegebenen Werte in eckreg.csv eingehalten werden. Gegebenenfalls ist der Text im Handbuch anzupassen.
wib: bei Bedarf Hinweise/Warnungen/Fehlermeldungen im Protokoll verbessern oder Algorithmen anpassen, falls man Anpassungsverhalten verbessern kann
m,h: Beim Baustein D1 Neubau, kann der Anwender vorgeben, in welchem Umfang die einzelnen Außentypen am Einzug in Neubaugebiete beteiligt sind. Eine vergleichbare Vorgabe wie für den Außenzuzug in Neubaugebiete sollte auch für den Binnenzuzug in Neubaugebiete möglich sein. Bei der Suche nach den Quelltypen für den Binnenzuzug in Neubaugebiete werden derzeit alle Binnentypen einbezogen. Es ist sinnvoll, alternativ die Suche auf eine vom Anwender vorgegebene Auswahl an Binnentypen mit Angaben in einer neuen Datei NeubauzuTYB beschränken zu können.
Derzeit werden die Anteile der Typen an den genannten Wanderungen der demografischen Gruppe aus der Binnenwanderung aller Binnentypen und dem Anteil aller Binnentypen am Zuzug- bzw. Wegzug der demografischen Gruppen ermittelt. Das halte ich für ungünstig, weil bei Rückbauten und bei Neubauten (je nach Neubautyp) sicherlich nicht die Typen mit den gehobenen Standorts in die Quantifizierung einbezogen werden sollten. Verkürzt: Ich schlage vor, die Basis für die Berechnungen problembezogen vorgeben zu können. Ich schlage nicht vor das Schema der Berechnung zu ändern, sondern als Basis der Quantifizierung nicht die gesamte Binnenwanderung zwischen allen Typen zu verwenden, sondern die Anteile der Typen für den Rückbaubinnenzuzug und Neubaubinnenauszug aus den Wanderungsdaten zwischen ausgewählten Binnentypen zu berechnen.
Arbeiten
- Datei Gewichte Quellen Neubauerstbezug Binnetypen
NEBGQT.CSV: #Jahr;tynee;tyb;Gewicht 2020;1;1;1 2020;1;2;0,8 2020;1;3;0 2020;1;4;1,4 2020;2;1;2 2020;2;2;1,8 2020;2;3;0,1 2020;2;4;1,0
oder ohne Gewichtung (=lauter gleiche Gewichte):#Jahr;tynee;tyb;Gewicht *;*;*;1
- Anpassung Dateinamen für "Neubauerstbezug":
alt neu NEBQ0000 NEBQ0000 demografische Quoten je Neubauerstbezugstyp (D1) NEUBAUB NEBB Anzahl Neubauerstbezugsbevölkerung je Gebietseinheit (D1) NEUBAUZU NEBQQA Anteil des Außenzuzugs am Neubauerstbezug je Neubauerstbezugstyp (D1) NEBGQT Gewichte Binnenauszug je Binnentyp und Neubauerstbezugstyp (D1) - Handbuch erweitern (hst)
NEBGQT mit der Differenzierung
nach tynee und tyb als schwierig erweisen sollte,
dann könnte die mögliche Erweiterung (siehe option($BSD)) mit einer Datei
NEBGQR mit der Differenzierung nach ngz helfen.
m,h: Beim Baustein E1 Rückbau, kann der Anwender vorgeben, in welchem Umfang die Außentypen als Ziele des Wegzugs aus den Rückbaugebieten beteiligt sind.
Eine ähnliche Vorgabe sollte auch auf die Binnentypen als Ziele des Binnenauszugs aus den Rückbaugebieten möglich sein, indem die Suche nach den Binnenzieltypen des Binnenauszugs aus Rückbaugebeiten Binnentypen/Gebiete gewichtet werden.
Erläuterung siehe Punkt 95.
Arbeiten
- Datei Gewichte Ziele Binnentypen
REAGZT.CSV: #Jahr;tyrea;tyb;Gewicht 2010;1;1;2 2020;1;2;1 2020;2;1;0,5 2020;2;2;1,3
- Änderung Dateinamen für Rückbauendauszug:
alt neu REAQ0000 REAQ0000 demografische Quoten je Rückbauendauszugstyp (E1) REAR REARB Rate Rückbauendauszugsbevölkerung (E2) RUECKBAUB REAB Anzahl Rückbauendauszugsbevölkerung je Gebietseinheit (E1) RUECKBAUWEG REAQZA Anteile der Außentypen als Ziele des Rückbauendauszug (E1/2) REAGZT Gewichte Binnenzuzug/-einzug je Binnentyp und Rückbauendauszugstyp (E1/2) - Bei E1 I1 P1 wird der Zielwert bei Identischen Gewichten erreicht, bei "echten" Gewichten nicht erreicht, eine Warnung wird ausgegeben
- Handbuch erweitern
reagzt.csv
bei P0/P2 auf GR2IBT DR5IB DR3IBR DG4IBR BGEM aus.
Wenn sich die Erstellung der Datei REAGZT mit der Differenzierung
nach tyrea und tyb als schwierig erweisen sollte,
dann könnte die mögliche Erweiterung (siehe option($BSE)) mit einer Datei
REAGZR mit der Differenzierung nach ngz helfen.
Rückbauendauszug könnte bei A1 M2 K0 verbessert werden (siehe roadmap 110)
wib:
Das Diagramm Prognoseablauf 10.3
ist nützlich für Handbuch, Schulungs-, Werbefolien und Vorträgen von
Anwendern über durchgeführte Prognosen.
hst hat Version 10.5 erstellt
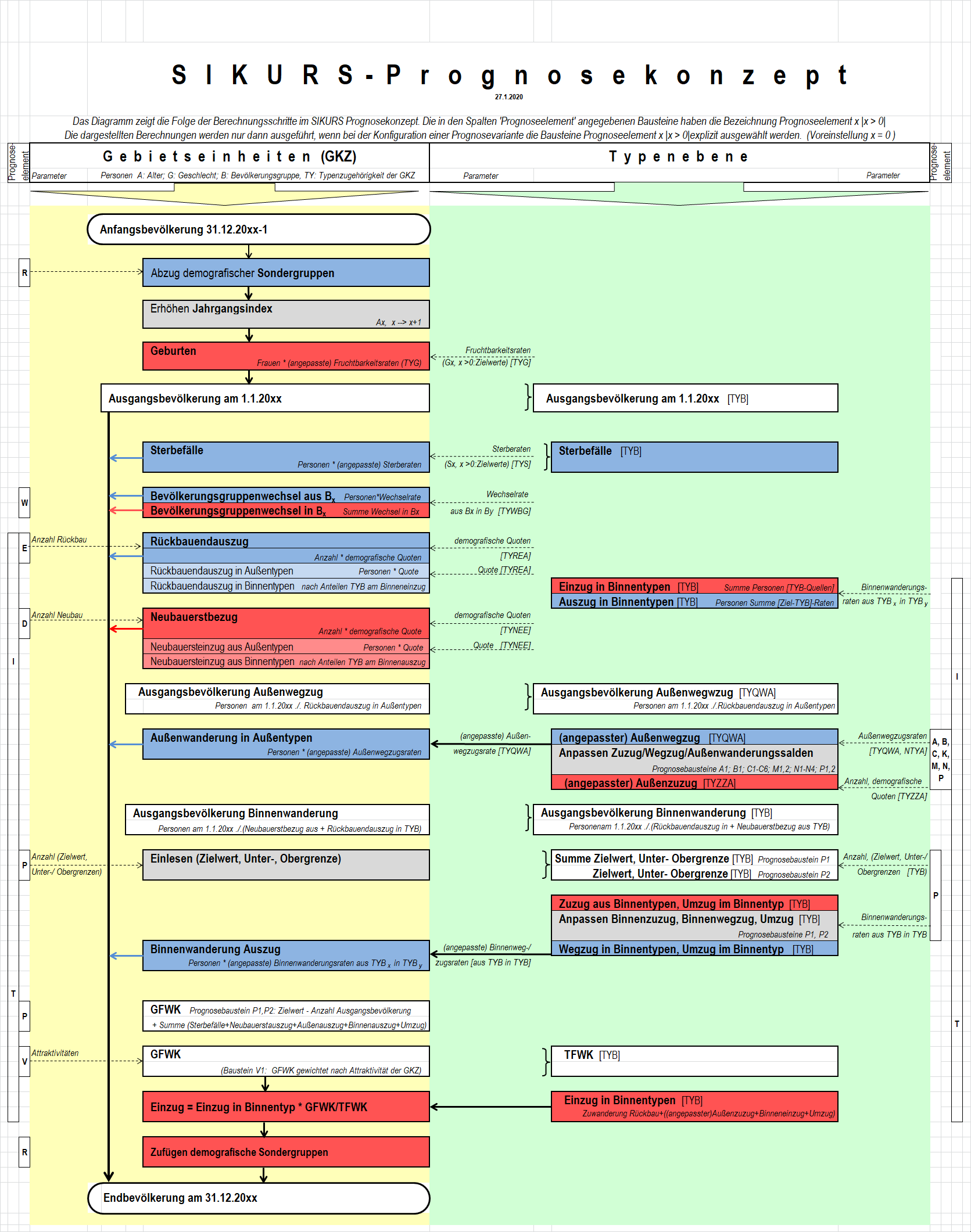{kind=link}
m,h: Die Hinweise, Fehlermeldungen zu zuaq und zudq sollen bei Bausteinkombination mit K0 entfallen.
wib: Bei K0 und
B1M2T1 wird der Außenzuzug (statt aus zuvol) aus eckreg abgeleitet, für die Verteilung auf die demografischen Gruppen wird zuaq benötigt, das Handbuch wurde ergänzt
A1M2T1 wurde zuaq unnötig gelesen, dies wurde korrigiert
Aufnahme von Typ 0 in Referenzdatei für alle Typen: 0= es finden keine Bewegungen bei diesem Typ/Gebiet in der entsprechenden Bewegungsart statt!
wib: erster Umsetzungsversuch mitte 2018 ist gescheitert
neue Lösung:
- Einlesen reftyp mit möglichen Typen = 0
- Ermittle für jede Spalte (bis auf AGF) die höchste Typnummer, z.B. NTYS
- Setze alle Typen = 0 auf Typ = NTYS+1
- NTYS = NTYS+1
- beim Einlesen von strb enthält der höchste TYS nur Nullen
- Beim Zugriff auf die Sterberaten vom TYS = 0 wird auf NTYS+1 zugegriffen (Wert = 0)
zr_gem.csv in Haushalteprognose (23h,10A,v10.4,Z:,B:)blh: HHPROG liest bei der Prognoseberechnung GEM-Dateien aus einer SIKURS-Prognose ein und erstellt dann für jede gefundene GEM-Datei zwischen Startjahr und Endjahr eine Haushalteprognose.
Wunsch: den Einlese-Prozess dahingehend zu erweitern, dass HHPROG auch eine
zr_gem-Datei verarbeiten kann, d.h., eine mit dem Zeitreihentool aggregierte GEM-Datei für mehrere Jahre? Das wäre sehr nützlich, da Haushalteprognosen häufiger auf einer höheren Aggregationsebene erstellt werden als Bevölkerungsprognosen, sowohl demographisch als auch räumlich.
wib: In der Startmaske der Haushalteprognose werden die Felder
[2019 ] Startjahr [2030 ] Endjahrentfernt.
Im Eingabeverzeichnis befinden sich
zr_gem.csv, sowie
zq.csv und hdsg(a/r).csv mit Jahr in Spalte 1.Das Programm liest die Dateien und ermittelt die darin gefundenen Jahre.
Für alle Jahre aus
zr_gem.csv wird eine Prognose gestartet
mit gleichem oder früherem Jahr für hdsga.csv hdsgr.csv zq.csv.Ein Update des Benutzerhadbuchs Haushalteprognose sollte möglichst durch die Autorin ahk erfolgen.
Als Folge musste die Standardprognose nachjustiert werden:
- Erweiterung Berechnung SIKURS-Raten um Möglichkeit "Infinity"-Raten aus Altersgruppen mit Bewegung aber ohne Bestand auszublenden.
- Aggregation Prognoseegebnisdateien
gem2019.csv, ... ingem.csv - Erzeugung
zq.csvmit Jahr in Spalte 1
gem2019.csv
die Ergebnisdateien gem2020.csv .. gem2029.csv.Wie kann man für die Haushalteprognose ein Aggregat
zr_gem.csv
aus den Ergebnisdateien ohne die Ausgangsdatei erstellen ?- Einwohner/Prognose/Berechnen
[1] Aggregation Zeitreihe [gem ] [reftyp 1 12 ] Gebietskennzeichen [keine ] Bevölkerungsgruppe [keine ] Geschlechtsgruppe [keine ] Altersgruppe
erstellt das gewünschte Aggregat ohne Ausgangsdatei
(Programm wurde erweitert
1 gem-Ergebnisdateien
2 gem-(Ausgangs + Ergebnis)-Dateien) - Einwohner/Prognose/Berechnen/Notiz
!option($GEMALL 1)
erzeugt als Ausgabdateizr_gem.csvohne die Ausgangsdatei
Mit- Ergebnis/Zeitreihe/Start
+-Aggregation über----------------------+ | Jahr [keine ]| | Gebietskennzeichen [reftyp 1 12 ]| | Bevölkerungsgruppe [alle Ausprägungen]| | Geschlechtsgruppe [alle Ausprägungen]| | Altersgruppe [keine ]| +---------------------------------------+ [3 ] Dateiauswahl (manuell)
- wähle Eingabedatei
zr_gem.csv
Nachteil: für Indikatoren und Reporting fehlen die Ausgabedateiengem2019.csv... - Ergebnis/Zeitreihe/Start
- Einwohner/Prognose/Berechnen
erzeugt Ergebnisdateien
- Zeitreihe/Start
[2] Dateiauswahl- wähle Aggregation
hst: Korrektur von Abweichungen der Variablennamen im SIKURS-Quellcode und folglich Prognoseprotokoll von der Namenssystematik für die Dokumentation des SIKURS-Programms in Excel (roadmap 053)
wib: auf eine entsprechende Anpassung im Programm-Quellcode wird aus
Aufwands- und Risikogründen vorläufig verzichtet.
Für die Anpassung der Namen im Prognose-Lauf-Protokoll wird stattdessen folgendes umgesetzt:
Enthält das Eingabeverzeichnis der Prognose eine Datei "Excel-Beispiel Variablennamen-Anpassung:
EVA.csv: #Programmquelle;Protokoll BR30;BR40 ...dann werden im Prognoseprotokoll die Namen der ersten Spalte (z.B.
BR30) durch den Namen der zweiten Spalte (BR40) ersetzt.Die Datei
EVA.csv kann vom Bearbeiter von roadmap 053 mit Hilfe
von SIKURS Datenflußgraph
undSIKURS Hauptmaske/?/Hilfe/Handbuch/Variabelnnamen
erstellt und gepflegt werden.
Wenn roadmap 053 abgeschlossen ist, kann die Datei EVA.csv für ein Angebot diese Variablennamen im Qullcode zu ändern, genutzt werden.
Zusätzlich wurden SIKURS-Eingabedateien von SIKURS-EXCEL.rar
so überarbeitet, dass sie als "Orakel-Regressionstest" geeignet sind
und als SIKURS-EXCEL_10_4_0_947.rar zur obigen Anpassung der
Namen an hst übergeben.
- RSR Rohe Sterberate
- Herr Krenkel hat einen Fehler gefunden und sehr viele
Indikatoren nachgerechenet.
Der Fehler wurde behoben.
Kontrollrechnung mitbewgem.csv:
RSR = 1000 * Tod / (Ausgangsbevölkerung ohne Geburt + Geburt) - AGR Allgemeine Geburtenrate
- Bei AGR rechnet man die GFF (Anzahl gebährfähige Frauen)
und Anzahl Kinder mit dem Intervall [GFFU .. GFFO]
Untergrenze .. Obergrenze gebärfähiger Altersbereich.
Die Berücksichtigung der Alterung der gem-Datei wurde ergänzt.
Kontrollrechnung mitbew.csvundgem2009.csv
AGR = 1000 * bew(2010,Geburt) / gem(2009,weiblich,[GFFU-1 .. GFFO-1]) - Differenzierung der Indikatoren
- die Parameter der Benutzeroberfläche bleiben bis zum nächsten Start erhalten
- RGR Rohe Geburtenrate, BRRagg Bruttoreproduktionsrate, ZGZagg Zusammengefasste Geburtenrate
- Fehler beseitigt
- PA Perzentilalter
- wurde entfernt, das QA Quantilalter Obermenge von PA ist
- QA Quantilalter
- Bei Quantil 10 heißt Ausgabedatei QA10.csv, damit kann man durch mehrere Läufe verschiedene Quantil-Abstände ansammeln
- ZGZagg BRRagg hwMO hwME hwVAR
- wurde bei gewählter Differenzierung ohne Geschlechtsgruppe unter HTML-Tabellen nicht ausgegeben
- LEagg Lebenserwartung in gewählter Differenzierung
- LEagg wird aus gem und bew berechnet. Wenn gem in der gewählten
Differenzierung Altersgruppen mit Nullwerten enthält, dann
kann LEagg nicht exakt berechnet werden, eine entsprechende Warnung
wird ausgegeben
(siehe auch 098 Indikatoren destatis)
stimmt die Berechnungsmethode (Problem mittlere Bevölkerung)?
Definitionen:
- Rohe Geburtenrate RGR = 1000 * Geburten / mittlere Bevölkerung
- Rohe Sterberate RSR = 1000 * Sterbefälle / mittlere Bevölkerung
siehe Benutzerhandbuch Seite 8:
Die Anfangsbevölkerung (gem2009) vom 31.12.2009 wird gealtert.
Mit fruc2010 werden die Geburten berechnet und zu Altersgruppe 0 addiert.
Damit hat man die Ausgangsbevölkerung des Prognosjahres 2010 auf die dann alle weiteren Raten (strb, wegz, ...) angewendet werden.
SIKURS nutzt also diese Ausgangsbevölkerung statt einer mittleren Bevölkerung
Entsprechen werden bei der Berechnung der Indikatoren die Formeln verwendet:
- RGR = 1000 * Geburten / (gem2009 gealtert ohne Geburten)
ab SIKURS 10.4.930 wurde die Berechnung geändert in:
RGR = 1000 * Geburten / Ausgangsbevölkerung - RSR = 1000 * Sterbefälle / Ausgangsbevölkerung
Bei SIKURS 10.2 bis einschließlich 10.4.0.938 gibt es einen Fehler bei dünn besetzten gem-Eingabedateien, bei denen weniger als 50% der Altersgruppen besetzt sind.
Das erste Prognosejahr wird richtig berechnet, aber die Endbevölkerung wird falsch als Ausgangsbevölkerung der Folgejahres übergeben, was zu falschen Prognoseergebnissen ab den 2 Prognosejahr führt.
workaround:
SIKURS Hauptmaske/Optionen/Systemenstellungen/Allgemein ... [ ] Log-Datei !SPARSEGEM 0Damit wird für alle Prognosen der Fehler verhindert.
Wenn Sie nur wenige Prognosen mit dünn besetzten gem-Eingabedateien haben, könnten sie stattdessen bei diesen Prognosen mit
SIKURS Hauptmaske/Einwohner/Prognose/Berechnen/Notiz !SPARSEGEM 0den Fehler verhindern.
Ab SIKURS 10.4.0.939 ist dieser Fehler beseitigt und Sie können auf den
Eintrag !option($SPARSEGEM 0) (in neuer Syntax) verzichten.
- Tools automatisch vor und nach einer Prognose starten
Um z.B. die Indikatoren automatisch nach jedem Prognoselauf berechnen zu können, könnte man das Menü:[v] Berechne Indikatoren Differenzierung der Indikatoren [2 ] Gebiet .... Ausgabeformat [v] Browser [v] CSV
als neuen Reiter "Indikatoren" in
Einwohner/Prognose/Berechnen
aufnehmen.
Das Protokoll Prognose würde dann am Ende vor "Ende Prognose" um einen Link
Inidkatoren
erweitert, der auf das Protokoll "indikator/index.html" verweist.
Die Speicherung der Parameter für die Indikatoren erfolgt für alle Prognosen zentral in der Dateisikurs.ini.
Sollte die Speicherung in die ini-Datei der aktuellen Prognose verlegt werden?Bei Reporting könnte man ähnlich wie bei Indikatoren vorgehen.
Eine Zeitreihe für gem-Dateien kann man bereits bei der Prognose anstoßen, weitere Zeitreihen muss man manuell nach der Prognose starten.
Damit könnte man nur jeweils einen Indikator, Report, Zeitreihe anfodern und nicht z.B. Zeitreihen von gem und gebam jeweils in voller Differenzierung und verschiedenen Aggregationen.Viele neue Reiter in der Startmaske Prognose würden diese überladen.
Deshalb wurde stattdessen
Einwohner/Prognose/Berechnen/Befehle
nach der Prognose
um Befehleindikator, report, zeitreihe, xyplot, matrix, hhprog, ...erweitert
siehe Änderungshistorie
(siehe auch Einwohner/Prognose/Berechnen/?/Befehle) - SIKURS-Funktionen aus einem anderen Programm
(bat-Datei, powershell, Julia, Python, R, jupyter, ...) aufrufen
Eine Prognose lässt sich z.B. aus R (Anforderung Mirko Jatsch, Statistisches Landesamt Bremen) wie folgt starten:system("C:\...\sikurs\App\sikern64.exe sikern -c -w C:\...\sikurs -d D:\...\prognose_1\ -v v_1")Der switch-csorgt dafür, dass die festgelegten Tools vor und nach der Prognose mitgestartet werden, man kann jedoch ebenso explizit z.B. "srnvle" (Sterberaten nach Vorgabe Lebenswerwartung) aus R starten:system("C:\...\sikurs\sikurs64.exe -w C:\...\sikurs -e 'run(q(-e),q(srnvle(q(strb2020),57,1)))'";mit den Sterberaten strb2020, 57 Iteration und Ausgabe Nullwerten).
Im Verzeichnis von strb2020 muss dann die Datei eckle.csv und optional ecklew.csv sein.Noch ein ausführlicheres Beispiel zu Start eines Tools und einer Prognose von einem cmd-script:
:: batch.bat [p [d]] :: start sikurs tool und Prognose im batch modus set ROOT=C:\trunk\sikurs set BSP=beispiel\tools\raten if "%~1" == "" ( :: SIKURS GUI Programm set PROG=%ROOT%\sikurs64.exe ) else ( :: SIKURS Perl GUI [ im Debugger ] set PROG=call sikurs.bat %2 ) :: setzte ini-Datei %PROG% -w %ROOT% -e "ini(q(%ROOT%\%BSP%.ini))" :: Sterberaten nach Vorgabe Lebenserwartung %PROG% -w %ROOT% -e "srnvle(q(strb2000),57,1)" :: Prognose %ROOT%\App\sikern64.exe sikern -c -w %ROOT% :: Zeitreihe %PROG% -w %ROOT% -e "zeitreihe" :: Ausgabe Protokoll am Bildschirm set PROT=%ROOT%\%BSP%\prot.tmp if exist %PROT% ( type %PROT% del %PROT% ) else ( echo %PROT% not found )
Aus
Einwohner/Prognose/Berechnen/Parameter
könnte man den Abschnitt "Zeitreihe" streichen, da es
2 Alternativen gibt:
Befehle
nach der Prognosezeitreihe 'zr_gem', [qw($i $i $i $i $i)]; # Alternative 1 subsystem 'zrgem' -o 'zr_gem' -a '$i,$i,$i,$i,$i'; # Alternative 2
weitere Befehle vor der Prognose (Aufbereitung der Eingabedaten) und nach der Prognose (Weiterverarbeitung Ergebnisdaten) könnten auf Anforderungen von Anwendern ergänzt werden.
- Integration der SIKURS-Funktionen in eine Scriptsprache z.B. R
Mit Rcpp lassen sich C++-Funktionen so in R integrieren, als wären sie eine in R geschriebene Funktion aber mit der höheren Performanz von C++:
Programme mit den für SIKURS typischen Operationen auf 5-dimensionalen Matrizen dauern in R (bench.R) 120 mal länger als in C++ (bench.cpp)
R mit SIKURS ließe sich dann in Jupiter integrieren. Ähnliches gilt für Scriptsprachen Python, Julia, ... - Verarbeite SIKURS-Ausgabedateien mit externen Programmen (z.B. R, Python, Julia)
Plotte Jahressummen der Dateizr_gem.csvmit- R mit weiteren Beispielen
R for Data Science:
gem <- read.csv("zr_gem.csv", header=FALSE, sep=";", dec=",", comment.char="#") agg <- aggregate(gem$V6, by=list(jahr=gem$V1), FUN=sum) png(filename="zr_gem.png") plot(agg$jahr, agg$x, type="B", xlab="Jahr", ylab="Bevölkerung") dev.off()
- Julia mit weiteren Beispielen
Statistics with Julia:
using DataFrames, CSV, Plots zr_gem = DataFrame(CSV.File("zr_gem.csv"; decimal=',', delim=';', comment="#", header=0)) zr = combine(groupby(zr_gem, [:1]), :6 => sum) gr() # GR plot backend p = plot(zr[!,:1], zr[!,:2], title="Entwicklung", label="Tübingen", legend=:botomright, lw=3, xlabel="Jahr", ylabel="Bevölkerung") savefig(p, "zr_gem.png") - Python:
import pandas as pd import matplotlib.pyplot as plt zr_gem = pd.read_csv('zr_gem.csv', header=None, sep=';', decimal=',', comment='#', prefix='C') zr = zr_gem.groupby(['C0'])['C5'].agg('sum') plt.plot(zr); plt.savefig('zr_gem.png') # for Jupyter notebooks use bokeh visualisation library: from bokeh.plotting import figure, output_file, show ... output_file('zr_bokeh.htm') plot = figure(title = 'Prognose', x_axis_label = 'Jahr', y_axis_label = 'Bevölkerung') plot.line (zr.index, zr.values) plot.circle(zr.index, zr.values, size = 8) show(plot) zr_bokeh.htm
Prognose und Visualisierung mit jupyter/Python
- R mit weiteren Beispielen
R for Data Science:
!option($M2NEU 1)
Beschreibung neues default-Verfahren aus BG3GG2/A1I1K4M2T1W1.xslx im Benutzerhandbuch:Anpassung Außenwegzug DG4WA(GZ,BG,GG,AG) an Eckwert eckreg.csv (BR21(BG,GG,AG) auf Gebietsebene
!option($M2NEU 0)
startet zum Vergleich das alte Verfahren:Anpassung DR3WA(TYQWA,BG,GG,AG) an eckreg.csv (BR21(BG,GG,AG) auf Typenebene
Siehe auch roadmap 053.16.
Das neue Verfahren erreicht bei ../beispiel/baustein/A1E2I1K5M2R2S2T1 den Zielwert aus eckreg erst nach Anpassung
2010..2011;3;2;2;1500 -> 1400Das Problem wurde durch Prüfung der angepassten Außenwegzüge (DU3WA) auf umgekehrtes Vorzeichen behoben.
Das alte Verfahren wurde nach Erkenntnissen des neuen Verfahrens verbessert und ist einziges Standardverfahren
Aktuell können bei der Glättung nur die Randbereiche ausgeschlossen werden, es wäre hilfreich, verschiedene Altersbereiche (Beipiel ?) in einem Menü auswählen zu können.
Änderung in der Maske "Pyramide - Glätten über das Alter
Eingabedaten [00 ][99 ] Altersbereich ... Glättungsparameter [01 ][98 ] Zu glättender Altersbereichersetzen durch
Eingabedaten [0:99 ] Altersbereich ... Glättungsparameter [1:30,21:60,91:98 ] Zu glättende AltersbereicheDas Programm prüft dann, ob die zu glättenden Arbeitsbereiche eine Teilmenge von
Eingabedaten [00 ][99 ] Altersbereichsind und glättet dann über die vorgegebenen Bereiche.
Die Lücken der Atersbereiche (0,61:90,99) werden nicht, überlappende Alterbereiche (21:30) doppelt geglättet.
(siehe test/smooth_range,pl)
Auf Anforderung von Herrn Stein beim Lenkungsauschuss 2019 wurde das Dokument SIKURS_Anpassung_Wanderungsstroeme.pdf erstellt
Bei Bausteinkombination A1 M2 Angleichung der Berechnung des Außenwegzugs bei K0 an die Berechnung bei K1-K6 mit besserer Verteilung jeder demografischen Gruppe auf die Typen Quellen Außenwegzug (TYQWA)
(von hst dokumentiert mit Beispiel A1I1M2T1-V1043/V1055)
Siehe roadmap 096
-
Kapitel03/Prognose03_01/AlleDateien/Prognose03_01.ini T0 Kapitel03/Prognose03_01/AlleDateien/Prognose03_02.ini T0 eckle ecklew hadwiger_synthese Vereinfachte Syntax für ecklew.csv eingebaut: #TYS;BG; GG;AG;Formel;# Kommentar 1; 1;1..2;99;$s ;# keine Anpassung Sterberaten Kapitel06/Prognose06_01/AlleDateien/Prognose06_01.ini T1K3 Kapitel06/Prognose06_02/AlleDateien/Prognose06_02.ini T1K3B1N3 Kapitel06/Prognose06_03/AlleDateien/Prognose06_03.ini T1K2B1M1 Kapitel08/Prognose08_01/AlleDateien/Prognose08_01.ini T1K3A1M2- Eintrag
RELEASE=10.2ist für SIKURS 10.2 statt 10.4 - Dateien z.B. reftyp.csv sollten in utf8 statt latin1 codiert sein
- evtl. Gründe für Hinweise und Warnungen in den Protokollen beseitigen, z.B.
Hinweis 1: Datei enthält ab Zeile 4 1400 endende Strichpunkte
- Eintrag
Kapitel07/AlleDateien/daten_clusteranalyse_kmedoids_index.htmenthält absolute Links auf z.B.href="file:///E|/Kapitel05/daten_clusteranalyse_vec.htm"Statistik, diese werden nach Programmänderung in relative Links umgewandelt, damit man die Dateien verschieben kannKapitel09/AlleDateien/gem2016.csv
Die 72 Gebiete sind teilweise sehr dünn besetzt, man sollte im Text auf die Problematik zu kleiner Gebiete hinweisen.- Seite 26 Anmerkung:
So können Sie ein Demografisches Sonder-Gebiet von der Simulation von Altersgruppenfortschreibug, Geburten, Sterbefällen oder Wanderungen ausnehmen, wenn Sie in der der Bewegungsart zugehörigen Spalte einem Gebiet den Typ „0“ in der reftyp.csv zuteilen. - Seite 30: Datei
fruc0000.csv, d.h. Fruchtbarkeitsraten zur Zeit von Christi Geburt hält das Programm bei einer Prognose ab 2017 für nicht plausibel, stattdessen z.B.fruc2010.csv - Programmiermeinung:
- Beim Glätten würde ich den Schwerpunkt anders setzten:
Wenn die Datenlage z.B. zu Binnenwanderung zu dünn für Raten ist, dann sollte man nicht versuchen durch extrem aufwändige Savitzki-Golay-Glättungen unterschiedlicher Altersgruppen diese Tatsache zu "verschleiern", sondern z.B.- die Anzahl Binnetypen reduzieren und/oder
- (nach Hanika:) die Altergruppen in für Binnenwanderung relevante Klassen einteilen (z.B. Kleinkinder, Schüler, ..., Alte) und allen Kleinkindern (evtl. beiden Geschlechts) die gleiche Wegzugsrate geben
- Typisierung
Neben der Typisierung nach Sozio-ökonomischen Gesichtspunkten kann man die Typen inreftypaus den Makrodateien am Beispiel Geburten wie folgt ableiten:- Berechne SIKURS-Eingabedaten aus Makrodateien:
[v] Geburtenraten (FRUC)(+ STRB + ...) auswählen[ ] Gebiete auf Typen abbilden
damit die Geburtenraten Gebiets-, nicht typenspezifisch berechnet werden.[v] Bevölkerungsgruppen zusammenfassen[v] Geschlechtsgruppen zusammenfassen
(neue Option ab SIKURS 1096)
fruc2018_roh.csv: #Gebiet;Bevölkerungsgruppe;Altersgruppe;Geburtenrate 40;1;19;0,0555555555555556 40;1;20;0,0416666666666667 40;1;21;0,04 ... 49;1;42;0,0476190476190476 49;1;43;0,0266666666666667
- Berechne Indikatoren der Geburtenraten
- Umbenennen
fruc2018_roh.csv -> fruc2018.csv - Berechnen
hadwiger_analyse.csv
hadwiger_analyse.csv: #Jahr;Gebiet;Bevölkerungsgruppe;F;MODE;MEAN;VAR 2015;40;1;1,79443114020087;28,5;30,3835532417762;31,9393377600142 2015;41;1;3,19166666666667;19,5;26,5130548302872;35,5168008507798 2015;42;1;0,5;28,5;28,5;0 2015;43;1;1,98093137729293;21,5;29,6946671393791;55,0228302353985 2015;44;1;1,50625049985304;31,5;32,8310943156691;19,7130519951109 2015;45;1;1,67332209161757;26,5;29,3158260929136;36,3913084714918 2015;46;1;1,5463420931671;26,5;31,1433249438001;32,0838705398792 2015;47;1;1,0487234987235;27,5;32,1749929878968;24,6921784321768 2015;48;1;1,50419623233443;30,5;31,5204396327853;26,0464487109803 2015;49;1;1,60169643008236;34,5;32,6180117854993;26,0174243907413
- Umbenennen
- Clusteranalyse
- Entferne Spalten Jahr, Bevölkerungsgruppe aus
hadwiger_analyse.csv - Clusteranalyse
hadwiger_analyse.csv
[v] Distanzmatrix Vektorelemente
(neue Option, damit kann man überprüfen, ob man einzelne Gebiete auch einem anderen Typ zuordnen könnte) #Gebiet;Cluster 40;3 41;1 42;2 43;1 44;3 45;3 46;3 47;3 48;3 49;3
- Entferne Spalten Jahr, Bevölkerungsgruppe aus
- Eintragen der Cluster in die Datei
reftyp.csvSpalte Geburt (Sterbefälle, ...) im Verzeichnis der Makrodateien - Erneut Berechne SIKURS-Eingabedaten aus Makrodateien:
[v] Geburtenraten (FRUC)(+ STRB + ...) auswählen[v] Gebiete auf Typen abbilden[ ] Bevölkerungsgruppen zusammenfassen[ ] Geschlechtsgruppen zusammenfassen
fruc2018_roh.csv: #Typ Geburtenraten;Bevölkerungsgruppe;Altersgruppe;Rate 1;1;20;0,125 1;1;25;0,133333333333333 1;1;32;0,142857142857143 1;1;33;0,117647058823529 1;1;38;0,142857142857143 1;1;40;0,142857142857143 1;1;44;0,111111111111111 1;2;19;0,5 ... 3;2;40;0,0555555555555556 3;2;41;0,0384615384615385 3;2;42;0,0166666666666667
Bei Bedarf glätten und für die Prognose verwenden
- Berechne SIKURS-Eingabedaten aus Makrodateien:
- andere Differenzierung der Typen (Geburten-, Sterbe-, Wegzugs-, ...-raten)
Die Raten sind nach Typ und Bevölkerunggruppe differenziert.
Wenn man inreftypdie Typen ebenso nach Bevölkerungsgruppe differnzieren würde, dann könnte es für BG 1 einige Cluster (Juppies, ..., Rentner) und für BG andere Cluster (Gastarbeiter, ..., Asylbewerber), anstatt der jetzigen diffusen Mischgruppen "Juppies mit kleinem Anteil Asylbewerber) gebenreftyp.csv: #GKZ;BG;TYG; ... 1001; 1; 3; ... 1001; 2; 5; ... ... 9404; 1; 2; ... 9404; 2; 7; ...
Für die Visualisierung der Typen als Karte bräuchte man dann (Anzahl Typspalten * Anzahl Bevölkerungsgruppen) thematische Karten.Die Namen der Gebietseinheiten würde man in eine neue Tabelle auslagern
refname.csv: #GKZ;"Name" 1001;"Bogenhausen" ... 9404;"Hasenbergl"
- Bei der Verwendung der Prognoseparameter Geburten-, Sterbe-,
Wegzugs-, ..., Raten, Außenzuzugs-Zahlen und Quoten
sowie weiterer Eckwerte und Gewichte gibt es zwei Möglichkeiten
für die Verwendung der Parameter für den Prognosezeitraum
- konstant
Berechnung der Parameter möglichst gemittelt über mehrere Jahre, die man dann bei der Prognose über einen (nicht zu langen Zeitraum) konstant läßt. - dynamisch
Man analysiert Kennzahlen z.B. TFR und Modalwert einer Zeitreihe von Geburten aus der Vergangenheit, extrapoliert die Kennzahlen in die Zukunft und passt damit die Geburtenraten für den Prognosezeitraum an. Da jede Extrapolation unsicher ist, empfiehlt sich eine Variantenprognose mit z.B. Varianten niedrige, mittlere und hohen Annahmen.
- konstant
- Quellenangaben und ein Index fehlen
- Beim Glätten würde ich den Schwerpunkt anders setzten:
- Offene Fragen
- Wie soll das Stein-Handbuch incl. Beispiele gepflegt werden,
d.h. an
- die jährliche Weiterentwicklung des Programms angepasst werden?
- an Anregungen von Benutzern und aus Kursen?
- Wie ist die Auswirkung auf vorhandene Dokumente
- SIKURS-Handbuch:
Soll dieses gekürzt werden, z.B. die Beispiele entfernt werden ? - SIKURS Hauptmaske/?/Beispiel-Eingabedaten entfernen ?
- SIKURS Kurzbeschreibung?
- SIKURS-Handbuch:
- Wie soll das Stein-Handbuch incl. Beispiele gepflegt werden,
d.h. an
- (Westholt, Osnabrück) erkenne falsche Dateicodierung (UTF-16 oder UTF-32) in Perl und C++ (5h)
- erlaube endende Kommentare in CSV-Eingabedateien (3h)
2020;1;1;0;0,123;# diesen Wert bitte überpüfen
- Katharina Wolf Rostock 12.08.2020
Leider stimmen die generierten Dateien zu den demografischen Sondergruppen und den Nebenwohnlern auch nach Fehlersuche und Absprache mit Frau Hohenberger-Krieg immer noch nicht. Ich habe mir jetzt beholfen, indem ich beide Dateien (hnws und hdga) selbst mit den korrekten Zahlen erstellt habe. Jetzt scheint die Prognose ohne Probleme durchzulaufen. Wir sind dennoch irritiert, dass die Ergebnisse nicht so gut mit unseren Zahlen aus der Haushaltegenerierung zusammen passen, bzw. eine Abweichung in ganz bestimmten Gruppen zu sehen ist. Die Abweichungen sind in der letzten Spalte der folgenden Tabelle zu sehen, es scheint ein Problem mit den 2-Personen-Haushalten zu geben. - Berechnen Sterberaten nach Vorgabe Lebenserwartung (5h)
Die SIKURS-Betaversion kennt 3 Berechnungsmethoden für die Lebenserwartung- Summe akkumulierte Überlebenswahrscheinlichkeit (SIKURS 8.3)
- Summe akkumulierte Überlebenswahrscheinlichkeit + 0,5 (SIKURS 8.4)
- destatis Methode (nach SIKURS 8.4.1035)
eckleangepasst werden.
Ein Anwender oder Methodenexperte sollte auswählen, welche der 3 Methoden fest eingebaut werden soll. - Korrektur (Katharina Wolf Rostock) person.csv bei hhprog-Prognose mit Testbeispiel BLH (17h)
Die Summe über HDO und PDO von person.csv wich von der aggregierten Summe von GEM ab.
In Tabelle "Übersicht zum Zusammenhang zwischen prognostizierten Personen- und Haushaltetypen":
In Altersgruppe <35 ist ZPN != ZPN2 + ZPN3 + ZPN4
Fehler korrigiert. - hhprog: unterstütze Verzeichnisnamen mit Umlauten (2h)
- hhprog: Prognose, Protokoll B2.5, PHG, UZPH verbessert
- hhprog: Wenn die Eingabedatei gem.csv, dsga.csv mehr als 100 Altersgruppen (z.B. 105) haben, dann wurden die Bevölkerungsgruppen 99 .. 105 nicht richtig auf Altersgruppe 99 aggregiert. (3h)
- BLH hat einige
SPSS-
(oder PSPP-) Prüfscripts für
die Konsitenz des Statistikdatensatzes erstellt, um die Ergebnisse der
Haushalteprognose besser nachvollziehen zu können.
Wie könnte man diese Hilfsmittel (z.B. PDO_HDO_erzeugen.sps) den Anwenderen zugänglich machen ?
Soll SIKURS Schnittstellen und/oder Anleitungen zu Statistik-Software bereitstellen ?
Bisher kann man- csv-Dateien austauschen
- R kann kann SIKURS fernsteuern:
- csv- und ini-Daten erstellen
- SIKURS im batch starten
- SIKURS-Ausgabedateien weiterverarbeiten
- SIKURS kann R fernsteuern in Befehle:
- vor der Prognose Eingabedateien erzeugen
- nach der Prognose Ausgabedateien weiterverarbeiten
- Nach Test Haushalteprognose mit kleinräumiger gem dirch BLH:
Verbesserung Codierung SH2i in q.csv () mit Gebietskennzeichen statt Gebietsnummer. (5h) - Auswertung der Außenwanderung in und von den Außentypen
neue scriptsaw.pl awbilanz.plund Beschreibung Außentypen (8h) - upgrade auf Perl 5.32 (4h)
- upgrade auf gnuplot 5.4 (3h)
das windows terminal von 5.4.1 ist fehlerhaft, deshalb vorläufige Rückkehr zu 5.2.8 - Verbesserung Navigation Prognoseprotokoll und alle Daten incl. Verzeichnis Ein-/Ausgabedateien sind in Datei index.html enthalten (erleichertert Fehlersuche). (5h)
- Frau Egloff Kanton Thurgau: Verbesserung Fehlerbehandlung und Warnungen bei Baustein P1 mit eckgem.csv ohne Untergrenzen (d. h. mit Untergrenzen 0 (angezeigt als -0)) (3h)
- Ergänzung fehlender Baustein C5 (4h)
- Dietmar Halmich Salzgitter: Tabelle "Zeitreihe Alleinerziehende ZRHTa" immer 0 wurde geändert in "Anzahl nicht Alleinerziehende",
Im Benutzerhandbuch "SIKURS Haushalteprognose" Seite 25 Aufbau hdo2.csv scheint falsch zu sein, richtig in Kommentar hdo2.csv "21 allein erziehend, 22 nicht allein erziehend (3h) - Extras/Eigene Scripts/Start/beventy.pl
Klassifiziere für jedes Prognosejahr für jede Gebietseinheit/Aggregat die prozentuale Bilanz der natürlichen Bevölkerungsbewegung (Geburt - Sterbefälle) und der Wanderungsbewegungen (Außenwanderung, Binnenwanderung incl. Neubau, Rückbau und Innenwanderung)Ableitung aus bewgem.csv oder bewgemagg.csv
siehe:
Teubner Studienbücher Geographie
W. Kuls/F.-J. Kemper
Bevölkerungsgeographie
^ G | \G>WV|G>WG/ \ | / WV>G \ | / WG>G \a|b/ h\|/c ----------*--------> WV g/|\d WG /f|e\ WV>S / | \ WG>S / | \ /S>WV|S>WG\ | | S G = Geburtenüberschuss S = Sterbefallüberschuss WG = Wanderungsgewinn WV = Wanderungsverlust dabei bedeuten die Klassen a-d Zunahme e-h Abnahme der Bevölkerung - Einwohner/Prognose/Berechnen/Protokoll
[v] Animation [200 ] Wartezeit [v] Summenbalken
Korrektur Wirkung Wartezeit und neue Option Summenbalken (3h) - Visualisierung/Pyramiden/Einzelpyramiden
Legende für Geschlechtsgruppen [12 ] Fontgröße
In ? (Hilfe) Texte für Unicode-Zeichen überarbeitet (1h) - IPF Algorithm 2 (factor estimation)
Die Anpassung der Binnenwanderung und Innenwanderung an Unter-/Obergrenzen (P1/P2) erfolgte durch Iterative proportional Fitting Algorithmus 1 (classical IPF) mit folgenden Unterschieden:- Das Zeilenziel ist die Summe der Zeilen der Ausgangsmatrix
- Das Spaltenziel hat Unter- und Obergrenze
Hauptmaske/Einwohner/Prognose/Berechnen/Notiz
!option($FIT_BW 2)
Eine Umstellung auf Algorithm 2 (factor estimation) brachte Vorteile- weniger Laufzeit bei hoher Anzahl Binnentypen bei der Anpassung der Binnenwanderung
- Die errechneten Zeilen/Spaltenfaktoren dokumentieren die prozentuale Anpassung des demografisch differenzierten Wegzugs/undifferenzierten Zugzugs der Binnenwanderung an die Unter/Obergrenzen der Binnentypen.
- den Superkompensationsexponenten, der aber vermutlich kaum genutzt wurde.
- bei IPF.pl die Abbruchschranke, statdessen immer Auführung aller Iterationen
Schwachpunkte - VDSt Indikatoren- und Merkmalskatalog zum demografischen Wandel
einarbeiten in- Indikatoren Makrodatei
- Faktor 100 bei JQ und AQ ergänzen
- Abhängigkeitsquotient
- Greying-Index
- Reporting
- Abhängigkeitsquotient
- Aging-Index Faktor 100 ergänzt
- Greying-Index
- Indikator Prognose
- Abhängigkeitsquotient
- Billeter J
- Greying-Index
- Indikator Statistikdatensatz
- Greying-Index
plot_indikator.pdf
(5h)
- Indikatoren Makrodatei
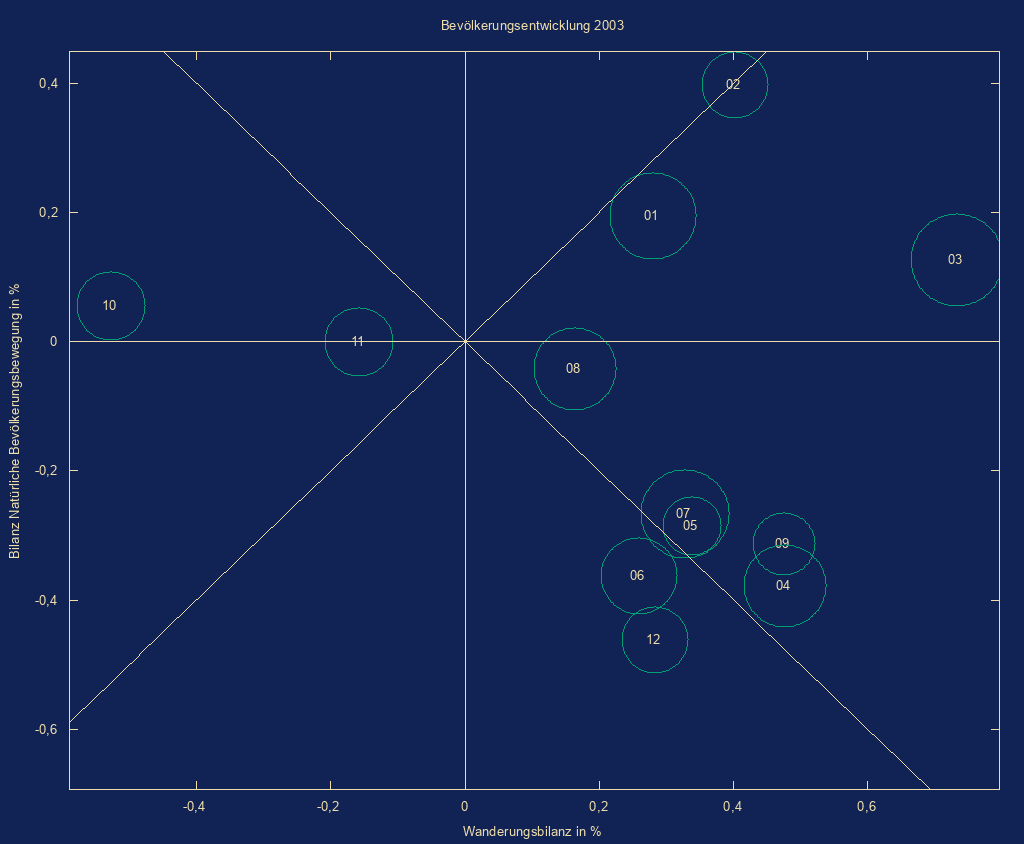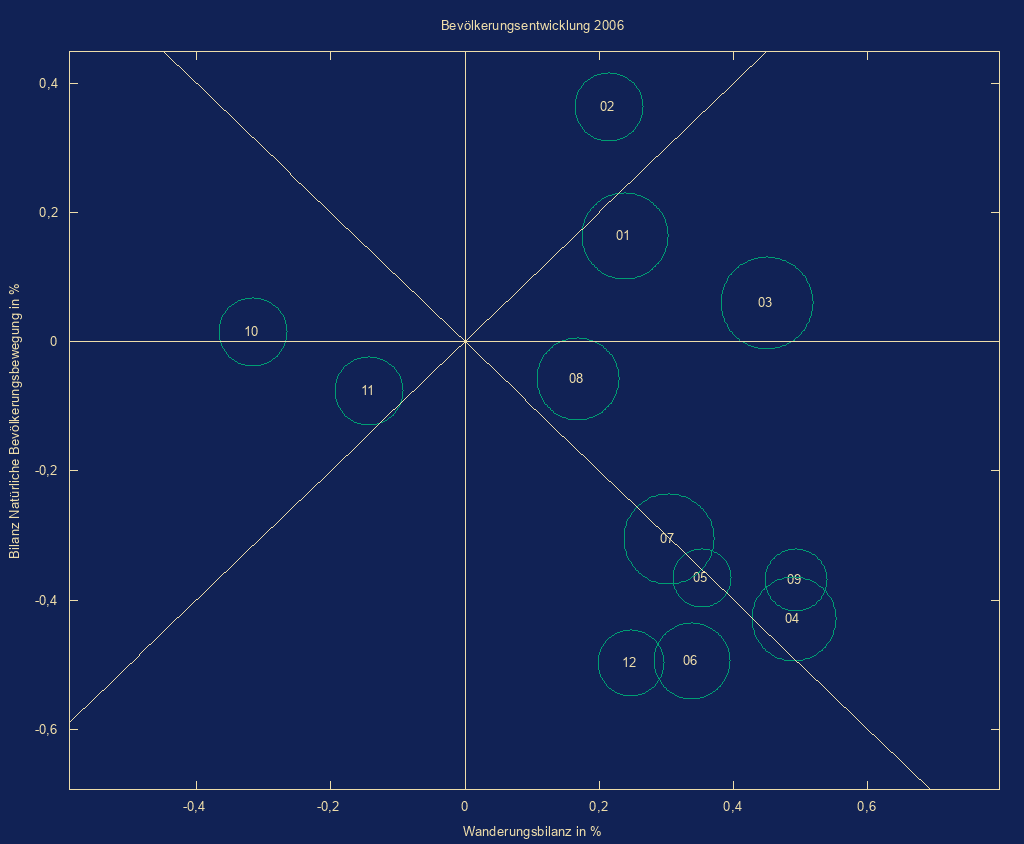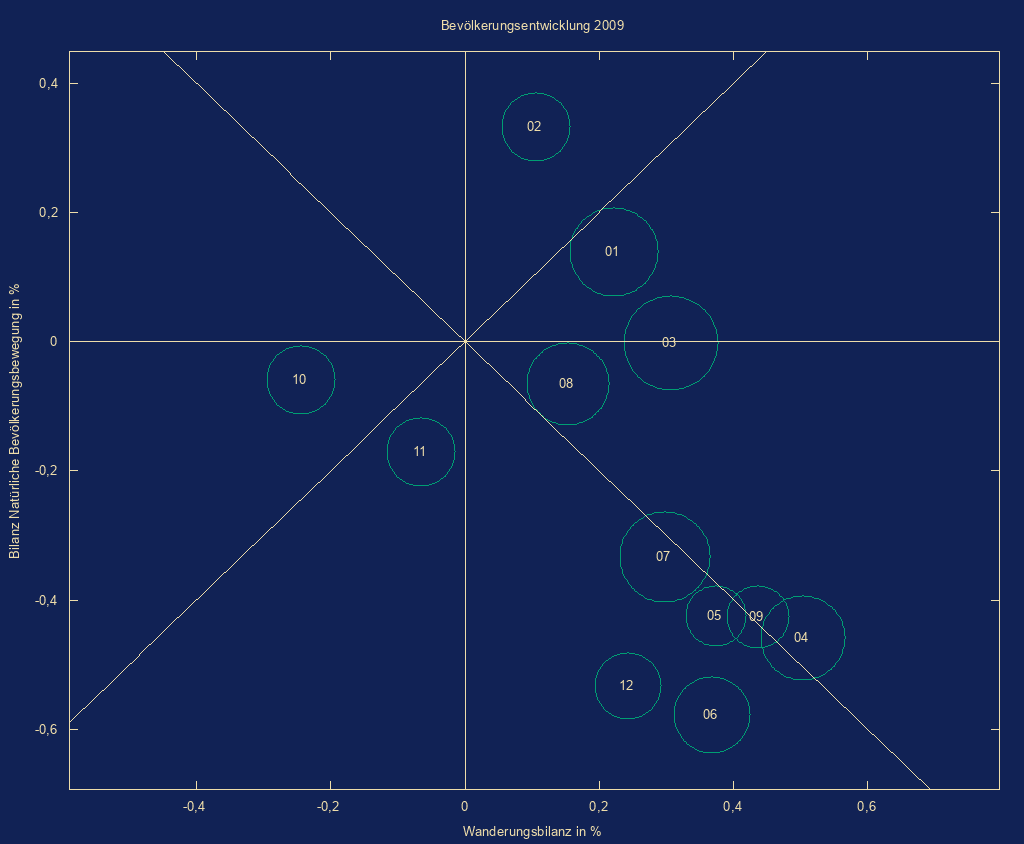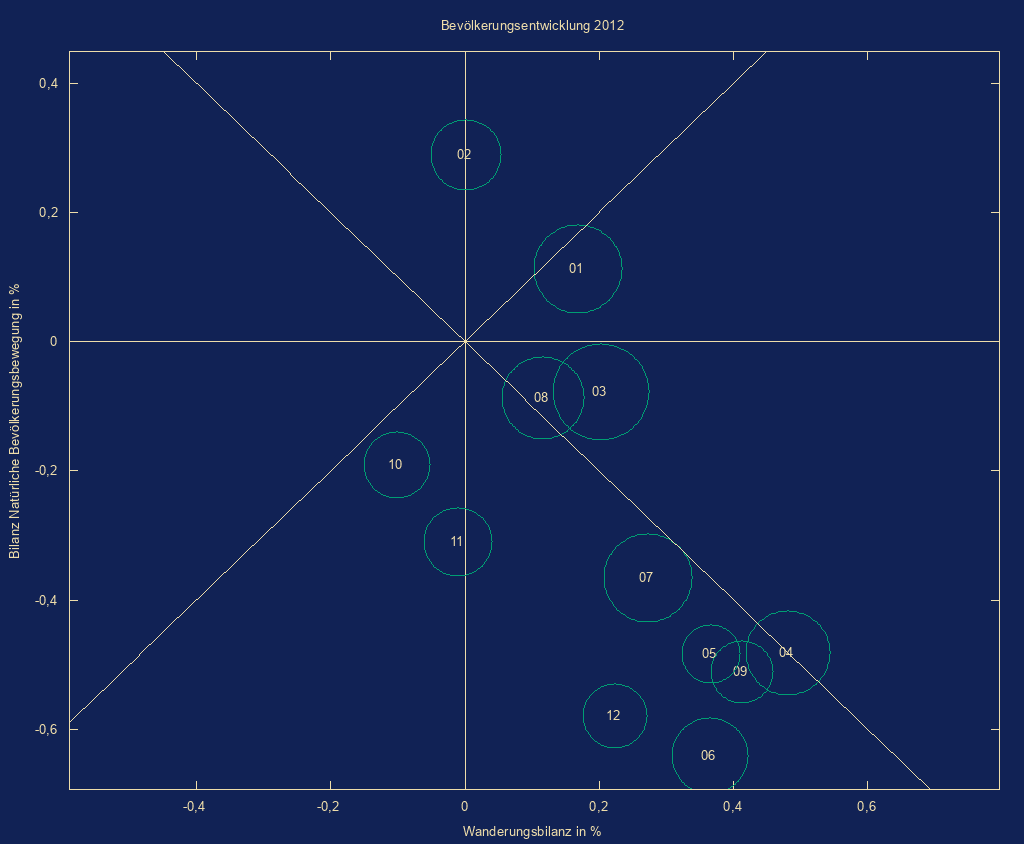{kind=link}
Herr Stein zum Baustein Neubau:
- In der reftyp.csv muss ich allen Gebieten einen TYNEE zuordnen,
auch wenn gar kein Neubau in einem Gebiet stattfinden soll.
Ich hätte vermutet, dass eine „0“ als Typnummer dazu führen würde, dass SIKURS diese Gebiete dann von der Simulation des Neubauerstbezugs ausnimmt. Dies
funktioniert aber nicht, d.h. ein Indexwert von 0 wird als vollgültiger Indexwert eingestuft, weshalb z.B. auch Angaben in der nebq-Datei für diesen
0-Typen einzupflegen wären. Gibt es eine Möglichkeit, einem Gebiet, wenn es keine Neubautätigkeit in dem Gebiet gibt (geben soll), keinem der TYNEE
zuzuordnen?
wib: Der Typ 0 wurde in reftyp für die Spalte 11 AGF (Altesgruppenfortschreibung) eingeführt, um einzelne Gebiete (mit Anstaltsbevölkerung) von der Alterung auszuschließen.
Ich habe die Wirkung des Typs 0 auf die Ausgabedatei bew untersucht fürWirkung G keine Geburten (+G) ! S keine Sterbefälle (-S) ! B keine Binnenwanderung und ZZA = 0 (-OBN -WB -OI +ZB +II) ! ZZA kein Außenzuzug (+ZA) ! QWA kein Außenwegzug (-WA) ! NEE Neubau (Dateien nebb nebgqr nebgqt nebq nebqqa) ?
neu: man kann jetzt mit TYNEE = 0 ein Gebiet aus dem Neubaubezug nehmen
Bei der Eingabedatei nebb wird geprüft, ob die Anzahl Erstbezieher bei TYNEE = 0 Null ist (//!NEE)REA Rückbau (Dateien reab reagzt reaq reaqza rearb) ?
neu: man kann jetzt mit TYREA = 0 ein Gebiet aus dem Rückbau nehmen Bei der Eingabedatei reab wird geprüft, ob die Anzahl Rückbauendauszieher bei TYREA = 0 Null ist (//!REA)WBG kein Wechsel der Bevölkerungsgruppe (-WBGv) ! - SIKURS erwartet für jedes Prognosejahr in der neubauzu.csv eine Angabe zur Anzahl der Neubauerstbezieher für mindestens 1 Gebiet. Zumindest eine „0“ für
die Anzahl muss dann eingetragen sein. Ansonsten bricht SIKURS die Berechnungen ab. Hier kommt mir SIKURS zu pingelig vor. Wenn es keinerlei Angaben zum
Volumen der Neubauerstbezieher in einem Prognosejahr gibt (z.B. weil keine Neubautätigkeit simuliert werden soll), könnte die Simulation des
Neubauerstbezugs eigentlich übersprungen werden (oder übersehe ich etwas?).
wib: jetzt Warnung ohne Abbruch - Einen krassen Anwenderfehler habe ich begangen, indem ich versehentlich als Ausgangsbevölkerung eine gem-Datei für die Gesamtstadt an SIKURS übergeben
habe (das bedeutete 1 Gebietseinheit in der gem-Datei, bei 72 Gebietseinheiten in der reftyp). Dies hat zu sehr erstaunlichen Ergebnissen geführt, da
SIKURS die Berechnung nicht abgebrochen hat. SIKURS hat die in der gem-Datei nicht vorhandenen Gebiete zum Teil mit Einwohnern gefüllt (nicht alle) und
die Gesamteinwohnerzahl durch einen positiven Binnenwanderungssaldo im ersten Prognosejahr mehr als verdoppelt. Eventuell wäre es sinnvoll eine Art
Füllungsgrad auch hinsichtlich der Gebiete zu ermitteln (Anteil der Gebietseinheiten in der reftyp zu denen mindestens ein Datensatz entweder in der
gem-Ausgangsdatei oder der neubauzu-Datei vorliegt). Taucht ein Gebietskennzeichen aus der reftyp in keinem weiteren Zusammenhang auf, wäre ein Abbruch
der Berechnungen eventuell sinnvoll, weil die Berechnung dann wohl auch zu sehr falschen Ergebnissen führen kann.
wib: habe nach Einlesen gem
Hinweis 1: in BGEM werden 2 von 5 Gebietskennzeichen aus "reftyp.csv" nicht genutzt
ergänzt.
- Teams Lenkungsausschuss Beratung Badger-System 26.07.2023 10:30 (1h)
- Teams Lenkungsausschuss Beratung Badger-System 06.07.2023 14:00 (1h)
- Teams Lenkungsausschuss Beratung Badger-System 29.06.2023 9:00 (1h)
- Teams Besprechung Badger-Systems 22.06.2023 11:00 (1h)
- Lenkungsausschuss 3.5.2023 13:00 - 14:30 (1h)
- Lenkungsausschuss zum Thema AraCom am 4.4.2023 9:00 - 10:00 (1h)
- Besprechung mit AraCom 14.03.2023 13:00 - 15:00 (2h)
- LA 27.10.2022 Abstimmung Prio-Excel-Liste SIKURS features incl. Vorbereitung (3h)
- Erstellung Dokument
- SIKURS Entwicklerhandbuch mit Kapitel Grobkonzept (3h)
- Teams-Lenkungsausschuss 28.10.2021 (3h)
- Kandidaten Nachfolge
- AraCom in Gersthofen.
Die AraCom betreut auch die KOSIS-Gemeinschaft AGK bzw. deren Programm, und Vertriebsleiter Herr Pahr ist sogar derjenige Herr gewesen, der mit für AGK zuständig ist und sich somit auch schon mit dem Wartungsgemeinschaftsprozedere auskennt. - BADGER SYSTEMS Herr Overbeck in Köln
- AraCom in Gersthofen.
Der Betrieb von SIKURS mit remote login auf eine Server (z.B. Parallels Client, Citrix / VDA-Verbindung)) scheitert an der Prüfung des Lizenzschlüssels.
SIKURS 10.5.1245 verwendet MAC-Adresse statt Nodename um dies zu lösen.
Notwendig ist neuer Lizenzschlüssel.
SIKURS 10.4 mit altem und SIKURS 10.5 mit neuem Lizenzschlüssel können parallel betrieben werden.
Herr Dr. Tüllmann findet folgende Grafiken
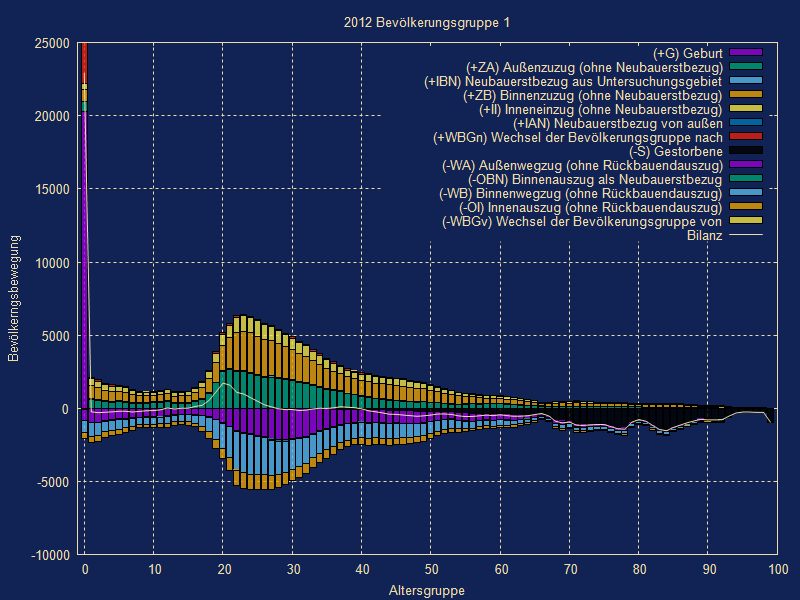
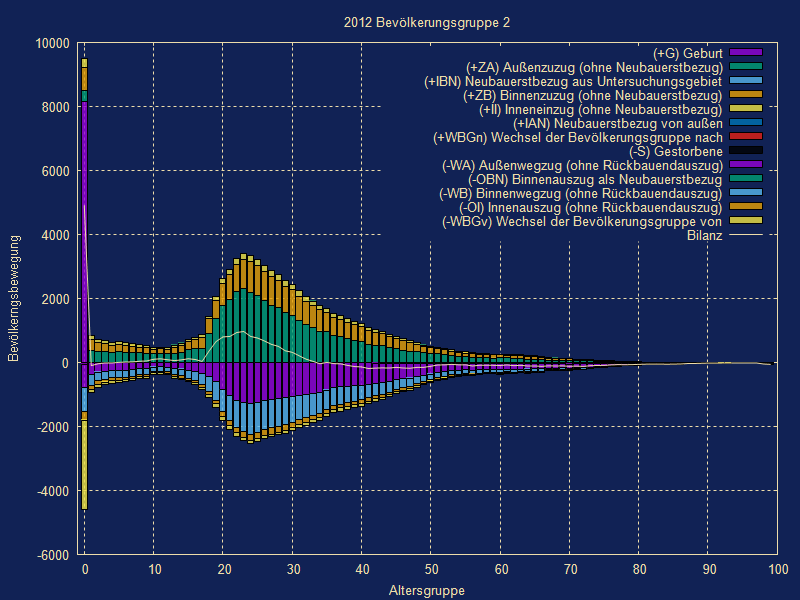
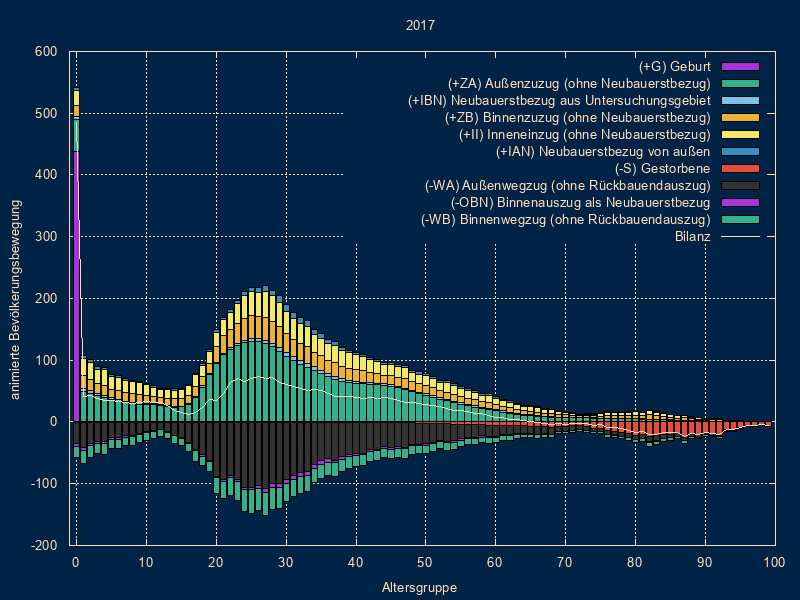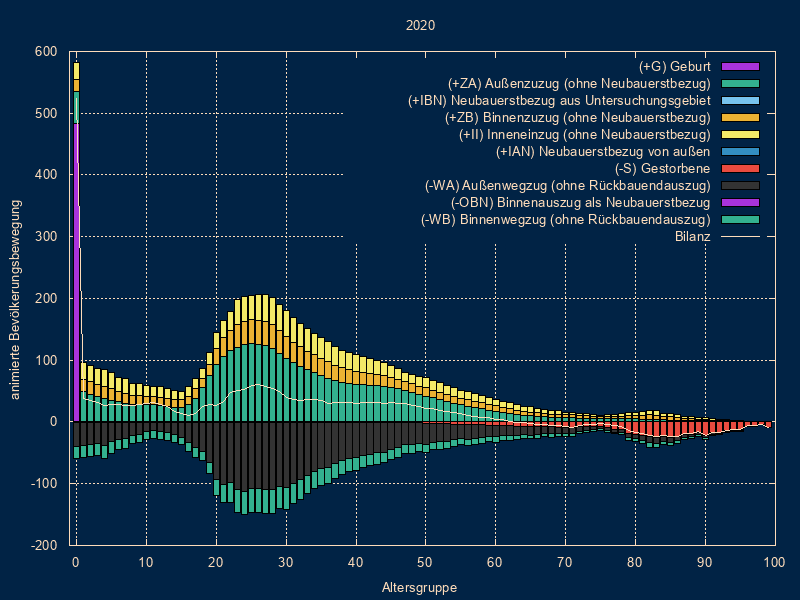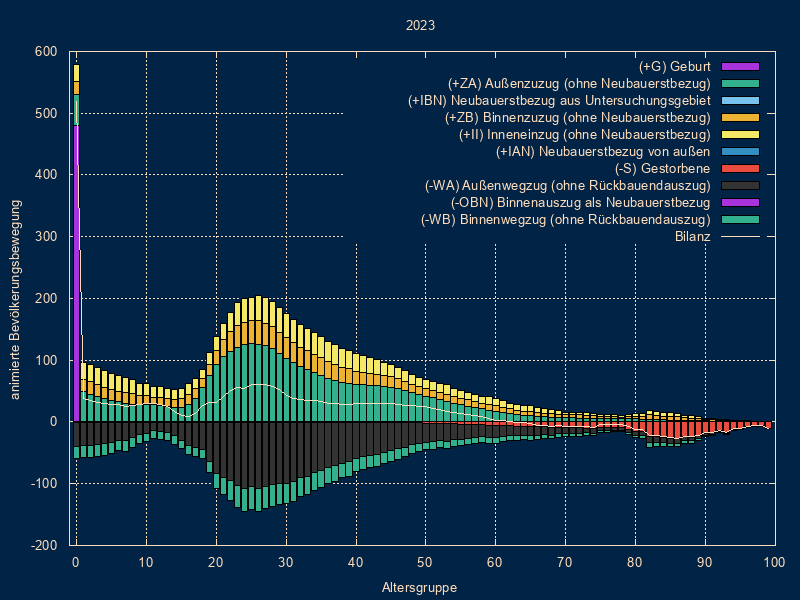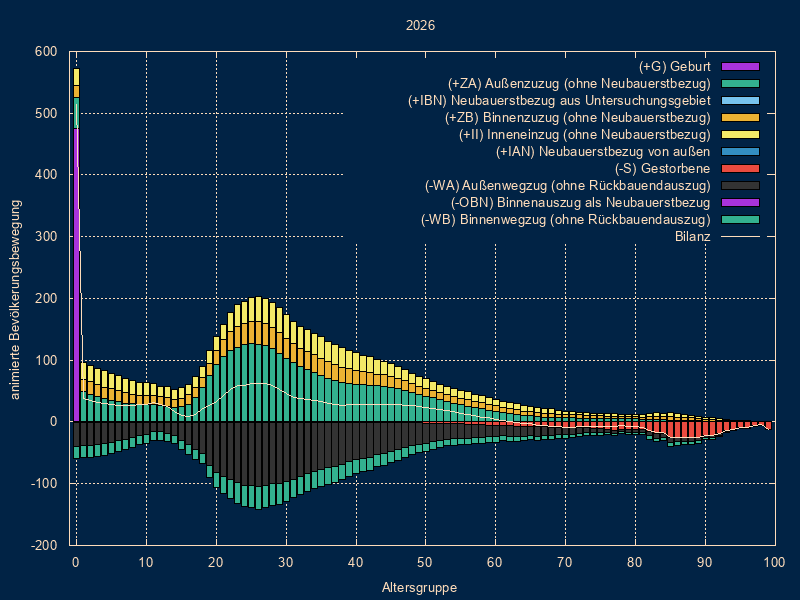
informativ, sowohl bei einer Kontrolle der Berechnungen als auch bei der Analyse der demografischen Prozesse.
Die Grafik beschreibt die Bewegungen im Untersuchungsraum des Jahres 2012.
Möglich und sinnvoll sind Grafiken weiterer Prognosejahre sowie Differenzierungen nach nicht zu dünn besetzten Gebieten, eines Typs oder räumlichen Aggregats sowie hier der Bevölkerungsgruppe (aber nicht Geschlechtsgruppe).
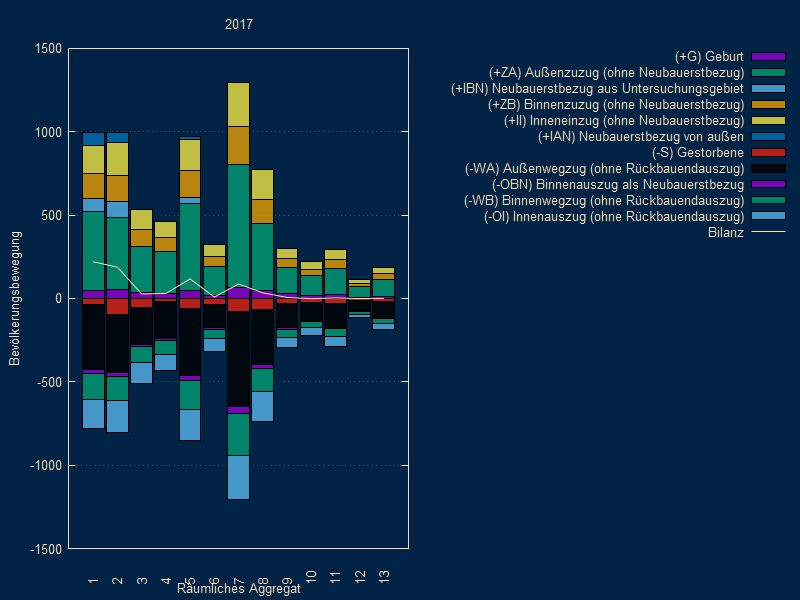
Die Auswertung erfolgte durch:
Visualisierung/Zeitreihen/X-Y-Plot
Auswahl
bew.csv
[5 ] x-Achse (Spalte Altersgruppe) [6..16 ] Wert (alle Wertespalten) [3 ] Blätter (Bevölkerungsgruppe) [v] Vorzeichen aus Spaltenüberschrift (+G) Geburt, (-S) Sterbefälle, ... [#1 == 2012 ] Auswahlfilter [set key right top ] Legende (*) Histogramm
Visualisierung/Zeitreihen/X-Y-Plot
wurde hierfür wie folgt erweitert:
[1 2 3 ] Blätter
Erstelle für jeden Wert der Spalten 1 (Jahr), 2 (Gebiet), 3 (Bevölkerungsgruppe) eine eigene Grafik[v] Vorzeichen aus Spaltenüberschriften
Übernehme aus den Spaltenüberschriften "(+G) Geburt", "(-S) Sterbefälle", ... das Vorzeichen für die zu- und abgehenden Bewegungen und die Bilanz
- Zur Berechnung von Außentypen und Neubauerstbezugstypen aus Statistikatatensatz und Makrodateien gibt es neue Anforderungen in roadmap 080
- Einwohner/Prognose/Berechnen/Protokoll
[v] Animation [2500] Wartezeit [v] Summenbalken
Die Wartezeit in ms wurde am Ende des Protokolls nicht richtig umgesetzt - Ergebnis/Anzeige/Thematische Karte
Das Programm startet mit Voreinstellungen für die Parameter:[7,5, 15 ] Farbcodierung [ ] Merkmalsnummer ...
Wenn man eine Thematische Karte für ein Shapefile erstellt hat, dann sollten bei jedem neuen Start die angepassten Parameter vorgeschlagen werden. (2h) - Verbesserung Lizenzschlüsselprüfung bei MAC-Adressen
"Nicht vorhanden" (3h)
Weitere Verbesserung:
Suche mitgetmac/NH /Vden EintragEthernet, und falls nicht vorhanden, nutze den letzten Eintrag (2h) - Haushalte/Anzeige/Start/Auswahl dstbest oder dstbew
Die Anzeige dient dazu als Alternative für SPSS, R, Python, ... die Eigenschaften und Qualität einer Statistikdatensatzdatei zu untersuchen.
Denkbare zu diskutierende Erweiterungen bzw. Verbesserungen- Erklärung statistischer Abkürzungen wie
count min max mean stddev kurosis skewness variance ... - Ausgabe der Erläuterungen der Einzelfeldnamen, z,B.
A01 Alter der Person
- Erklärung statistischer Abkürzungen wie
- Fehlen bei Baustein G1: Geburtenzielwert / S1=Sterbefallzielwert in der Datei eckgeb / eckstrb Zielwerte für einzelne Jahre, so erfolgt für diese Jahre keine Anpassung der nach Raten berechneten Geburten / Sterbefälle an einen (nicht vorhandenen) Zielwert (3h)
- Haushalte/Quoten|Prognose: zusätzlicher Reiter Notiz wie in
Einwohner/Prognose/Berechnen und Speicherung in
hhprog.iniwurde probehalber programmiert, soll es eingebaut werden ? - Beseitigung Problem, wenn csv-Eingabedatei ein Eingabefeld länger
als 1024 Zeichen enthält, z.B. Zeile 1
zuvol.csv #Erzeugt aus X:/.../aussenzuzug_2001.csv ... X:/.../aussenzuzug_2021.csv;;;;
(3h) - verbesserte Warnung, wenn csv-Eingabdateien fehlerhafte UTF-8 Condierung enthalten (1h)
- mitgelieferte Beispiel-Eingabedateien beispiel.zip überarbeiten (3h)
- Eingabedaten/Berechnen/Sterberaten nach Vorgabe Lebenserwartung
Um die Erstellung der Datei eckle.csv zu erleichtern, kann man mehreren vorhandene Dateien strb2015.csv, strb2018.csv, strb2020.csv auswählen, dann wird lebenserwartung.csv mit den Jahren 2015, 2018, 2020 berechnet.
Mit dieser Vorlage kann man die Datei eckle.csv mit den gewünschen Lebenserwatungen zukünftiger Jahre erstellen.
Alternativ kann man nach
Visualisierung/Indikatren/Prognose/Berechnen
die Ausgabedatei eckLE.csv verwenden. (4h) - Im Protokoll führen Links auf csv-Dateien bei manchen Anwendern
beim Anklicken zu merkwürdigem Verhalten
(Download, Wandlung in Excel Datei, Fehlermeldung beim Löschen).
Optionen- gem2022.csv belassen, man muss ja nicht anklicken, den Speicherort sieht man in der Fußleiste des Browsers, wenn die Maus über dem Link steht)
- gem2022.csv: nur Text ohne Link, der Anwender sollte wissen, wo die Datei ist
- F:/hier/und/da/gem2022.csv: voller Pfadname als Text
- F:/hier/und/da/gem2022.csv: voller Pfadname als blauer Text
- gem2022.csv "tooltip statt link" ?
- öffnen gem2022.csv mit javascript und Ausgabe entweder als plain text oder als Tabelle, mit der Gefahr, dass der Browser den Zugriff auf manchen Datenträgern verweigert.
- Umbenennung in gem2022.txt, danach öffnet der Browser sie als Textdatei.
erfordert Umbenennunng aller vorhandenen csv-Dateien, so wie in der ganzen Programmkette "Statistikdatensatz, ..., Haushalteprognose".
Excel kann gem2022.txt weiterhin als csv-Datei öffnen.
- Verwendung von Buchstaben A, B, C, ... wie in Excel statt Spaltennummern 1, 2, 3, ...
in SIKURS-Benutzerhandbuch, Hilfe-Dateien und Programm, z.B.
Ergebnis/Zeitreihe:Aggreagtion über Jahr [ keine ] Gebietskennzeichen [ reftyp A E ] ...
BK: nicht nötig - Für die Ableitung Makrodateien und SIKURS-Eingabedateien aus dem Statistikdatensatz Abbildung mehrerer Teilschlüssel aus R02 auf ein Gebiet (z.B. Schulsprengel)
gibt es mehrere Lösungsmöglichkeiten:
- Nutzung raümliches Aggregat in reftyp
Leiten Sie die SIKURS-Eingabedateien in einer zu feinen Struktur ab und weisen Sie dann in reftyp Spalte "räumliches Aggregat" mehreren Gebieten den gewünschten Schulsprengel zu.
Prognose in der zu feinen Struktur.
Aggregation aller Ergebnisse nach reftyp räumliches Aggregat. - Erweiterung Tools
- Makrodateien aus DST (6h)
Nach einem ersten Lauf nimmt man Spalte 1 der Dateimakro/reftyp_roh.csv: 102;"";1;1;1;1;1;1;1;1;1;1;1;1 103;"";1;1;1;1;1;1;1;1;1;1;1;1 105;"";1;1;1;1;1;1;1;1;1;1;1;1
und baut damit die Datei auf:dst/refgem.csv: #R02;Schulsprengel 102;11 103;11 105;12 ...
Nach einen zweiten Lauf mit dieserdst/refgem.csventhalten die Ausgabedateien im Verzeichnismakroincl.reftyp_roh.csvden Schulsprengel statt R02.makro/reftyp_roh.csv: #Gebietskennzeichen;Gebietsname;...;räumliches Aggregat 2" 11;"";1;1;1;1;1;1;1;1;1;1;1;1 12;"";1;1;1;1;1;1;1;1;1;1;1;1
Aus dieser Datei kann man dann die Dateimakro/reftyp.csv: #Gebietskennzeichen;Gebietsname;...;räumliches Aggregat 2" 11;"";1;1;1;1;1;1;1;1;1;1;1;1 12;"";2;2;2;2;1;2;2;1;1;1;1;1
mit der gewünschten Abbildung in Typen erstellen und fortfahren
Eingabedaten/Berechnen/SIKURS Eingabedaten aus Makrodateien
- Nutzung raümliches Aggregat in reftyp
- Statistikdatensatz-Beispieldateien für Haushalteprognose und
Ableitung Makrodateien und SIKURS-Eingabedateien
Entweder als Ergänzung in Hauptmaske/?/Beispiel-Eingabedaten (sikurs/html/de/00Hilfe/beispiel.zip) oder als SIKURS-Anwenderhandbuch ähnliches Kapitel im Mitgliederbereich
Die Beispiel-Dateien sollten- dateschutzkonform
- nicht zu umfangreich
- Parameter der Eingabemaske
(RMfilter, R02DST, RTKGZ, W40DST, DSTBEWABM, ANST, NEUB, NETTOBEW)
sind zentral für alle DST-Verzeichnisse in der Datei
C:/Users/"user"/AppData/Roaming/sikurs/sikurs.iniim Abschnitt[RATEN].
Will man die Parameter pro DST-Verzeichnis, sollte man sie in eine neue Datei dst/makro.ini (analog zu makro/raten.ini) verlegen.
Damit könnte man Beispiels-DST-Dateien mit Verarbeitungsparametern ausliefern. - zu vernünftigen Ergebnisdateien führen
- keine oder kaum Hinweise, Warnungen und Fehler im Protokoll erzeugen
- downgrade gnuplot 5.4.3 nach 5.2.8 wegen bugs in pipe und windows terminal (3h)
- Ergänzug Spezifikation SpezHHProg20201105.pdf nach Vorgaben Lux-Henseler und Lindemann (3h)