Eine wahlweise Differenzierung der Eckwerte für Geburten (eckgeb), Sterbefälle (eckstrb), Zuzug (zuvol), Wegzug (wegvol) zusätzlich nach Gebiet:
Aufspaltung Baustein "L Zielwert für die natürliche Bevölkerungsbewegung" in Baustein G (Zielwert Geburten) und S (Zielwert Sterbefälle) (Baustein "G Generische Daten" in Laufzeitparameter umwandeln) (erledigt siehe 030)
zuvol: Baustein K erweitern (erledigt siehe 031)
wegvol: Baustein C erweitern (erledigt siehe 031)
Notwendig sind noch:
- Analyse, in welchen Bausteinkombinationen mit C6/K6 benötigt werden
- Test und evtl. Korrektur dieser Kombinationen
- Ausschluss der nicht benötigten Kombinationen im Methodenassistenten
Der Zuzug in den Zieltyp Außenzuwanderung 7, Bevölkerungsgruppe 2, Geschlechtsgruppe 1, Altersgruppe 97 ergibt sich aus zuvol, zudq und zuaq und sei ZT[7][2][1][97] = 100.
Der Zieltyp Außenzuwanderung 7 bestehe aus 20 Gebieten u.a. Gebiet Nummer 143.
Die Aufteilung der Zuwanderung auf eines dieser Gebiete ZG erfolgt im Verhältnis der Gebietsbevölkerung BG zur Typebevölkerung BT:
ZG[143][7][2][1][97] = ZT[7][2][1][97] * BG[143][7][2][1][97] / BT[7][2][1][97]
Wenn BT[7][2][1][97] Null ist muss eine Ersatzformel verwendet werden.
Derzeit wird in diesem Fall der Zuzug ZT gleichmäßig auf alle Gebiete verteilt, im Beispiel 100/20=5.
Dieses Verfahren ist bei grobkörnigen Prognosen vertretbar, weil leere Altergruppen kaum vorkommen und wenn dann nur prozentual wenig Köpfe zu verteilen sind.
Da sich SIKURS inzwischen technisch für feinkörnige Prognosen eignet, werden vermutlich auch häufiger feinkörnige Prognosen gerechnet (siehe auch Handbuch zu diesem Thema).
Bei feinkörnigen Prognosen sind leere Altergruppen der Regelfall, so dass Methodenexperten und Anwender Alternativen diskutieren sollten.
Eine Alternative aus Programmierersicht wäre folgendes Eskalationsschema:
Wenn BT[7][2][1][97] gleich Null ist, dann aggregiere BT[7][2][1] über die Altersgruppe.
Wenn das Aggregat Null ist, dann aggregiere auch noch über die Geschlechtsgruppe und notfalls über die Bevölkerungsgruppe.
Ist auch dieses Aggregat gleich Null, dann verteile ZT gleichmäßig auf die Gebiete, sonst im Verhältnis BG in der gleichen Aggregatsstufe wie BG zu BT.
Für eine Mikrosimulation mit SIKURS gibt es folgende Ansätze
- Erstellung feinkörniger und dünn besetzter gem-Dateien mit reduzierten reftyp-Dateien wie oben beschrieben
- Erstellung eines Programms zur Prognose auf Basis dstbest und dstbew
- ermittle angepasste Raten auf Basis einer SIKURS Prognose über aggregierte Daten
- Mikrosimulation mit den angepassten Raten
- Haushalteprognose als Mikrosimulation
Statt einer Adeton-Anpassung der Haushalte an eine grobkörnige SIKURS-Prognose kann man eine feinkörnige SIKURS-Prognose mit Gebiet = Haushalt durchführen.
Zu klären ist, wie folgende Daten aus ersterer Prognose ermittelt werden können- Haupt-/Nebenwohnsitzler, Faktor wohnberechtigte Bevölkerung
- Aggregat
person.csvmit Gebiet, Typ, PDO, Geschlecht, Altersgruppe, HDO, Anzahl - Aggregat
haushalt.csvmit Gebiet, Typ, HDO, Haushaltsgröße, Anzahl - Aggregat
hdo2.csvmit Gebiet, Typ, HDO2, Anzahl - Aggregat
kinder.csvmit Gebiet, Typ, Anzahl Kinder, Anzahl Haushalte
Bei (Außen-zu/weg, Binnen)-Wanderungen braucht man eine Möglichkeit ganze Haushalte wandern zu lassen.
Bei Binnenwanderung könnte die so aussehen:
Eine neue Eingabedatei:HHSTRM.csv - Binnenwanderungsrate Haushalte #von;nach;Rate ... 21;34;0,03 ...
Die Verarbeitung könnte so erfolgen:Über alle Einzelpersonen sammle Haushalt wenn nach Haushalt nach HHSTRM und Monte-Carlo umzieht lösche Haushalt und füge ihn als "nach" ohne laufende Nummer in Warteschlange ein führe Einzelpersonen und Warteschlange mit neuer lfd zusammen
Bei kleinräumigen Prognosen, d.h. wenn man viele Stellen von R02 verwendet, und die Schlüssel auf viele Blöcke abbildet. sind viele Quoten nicht definiert, weil sie im Zähler und Nenner eine Null enthalten, z.B.
Q10(g,t,a) = SPK(g,t,a)/SP(g,t,a)
Die Spezifikation sollte auf diese Problematik eingehen, mit folgenden denkbaren Antworten
- Generelle Regel für die Quotenbildung:
Bei Division a/0 (a > 0) ist mit Fehler abzubrechen, bei Division 0/0 ist Ersatzwert 0 (oder 0.5 oder 1 ?) zu verwenden. - Bei jeder Formel mit Division folgt eine Anweisung für 0 im Nenner
- Festlegung, wo die Grenze der Kleinräumigkeit der Prognose liegt
Eingabedaten/Berechnen/Makrodaten aus dst
[ 1] Altersberechnungsmethode/(A01)|Z01|Z02
Das Alter A01 wird aus Ereignisdatum, Z02 - Geburtsdatum, P01 ermittelt;
Monat und Tag werden berücksichtigt. Für die "normalen" statistischen Auswertungen ist das so korrekt.
In SIKURS sollte aber nur das Jahr verarbeitet werden, damit es zur
Logik von SIKURS passt. Das wäre dann Z02jjjj - P01jjjj. Da es bei der
Berechnung mit dem Ereignisdatum im betrachteten Verarbeitungsjahr aber
Bewegungen geben kann, die längere Zeit zurückliegen, könnte dies die
Raten verfälschen.
Als Ersatzlösung hat Frau Lux-Henseler vorgeschlagen, das
Verarbeitungsdatum zu nehmen, weil die Bewegung erst im
Verarbeitungsjahr bestandsverändernd wirksam werden. Ihre Berechnung Z01
- P01 und zwar nur das Jahr wäre dann Ok. Aus meiner Sicht sollte Herr
Dr. Tüllmann dies noch mal in Bezug auf SIKURS durchdenken.
In Tests wollen wir jetzt herausfinden, ob sich Z01 oder Z02 - und zwar immer nur das Jahr - besser für den Altersindex eignen. Ich habe vor Jahren schon mal ähnliche Tests gemacht und die Bewegungen mal nach Verarbeitungsjahr und mal nach Ereignisjahr ermittelt. Die berechneten Raten und das Prognoseergebnis haben sich nur minimal unterschieden. Ähnlich vermute ich, wird der Vergleich Z01 / Z02 ausgehen.
Wenn das Ergebnis der Analsyse vorliegt, kann die Umsetzung geplant werden
A01 226 03 I Alter der Person P01 109 08 I Geburtsdatum (JJJJMMTT) Z01 148 08 I Verarbeitungsdatum (JJJJMMTT) Z02 156 08 I Ereignisdatum (JJJJMMTT)
die Situation bei Graphikformaten ist unübersichtlich
- wxt: gnuplot Ausgabeformat in ein Bildschirmfenster ohne zugehörige Graphikdatei. Graphik im Bildschirmfenster kann interaktiv manipuliert werden (Zoomen, 3D-Ansichten drehen, Grid ausblenden) und über Zwischenablage in Dokumente eingefügt werden.
- gif: Pixelformat, wird von allen Browsern verstanden, ist animierbar, aber als Pixelgraphik nicht gut in der Größe skalierbar. Für Pyramiden o.k., für Dendrogramm ungünstig.
- webp: moderner Nachfolger von gif, png, jpeg, wesentlich kompakter, ab gnuplot 6:
set term webp size 640, 480 animate delay 500 loop 0 font 'Arial,8' background rgb bgcol Legende Geschlechtsgruppen: {/Arial=30 \U+1F468 ♂} {/Arial=30 ♀ \U+1F469}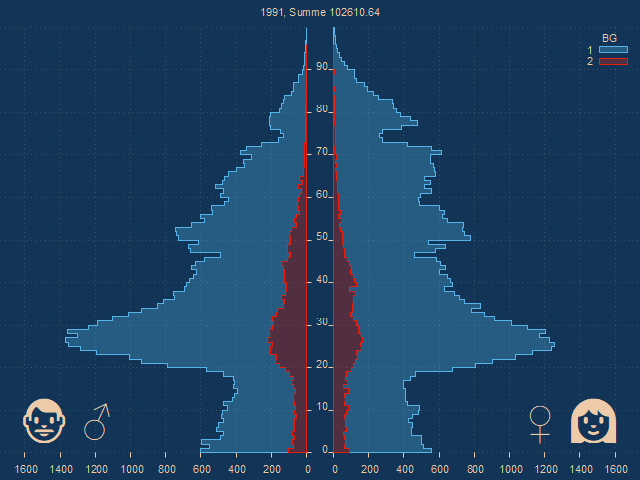
- png: ähnlich gif, aber nicht animierbar, dafür unter gnuplot mir transparenten Farben und schönen Schriften.
- svg: ideales Format für Dendrogramm, Pyramiden
und Thematische Karte.
svg ermöglicht, dass sich die Graphik inklusive
Schrift stufenlos and die Größe der Browserfensters anpasst.
Leider hat Adobe die Unterstützung des sehr guten Plugins
für IE aufgekündigt.
SVG Resource Directory
Internet Explorer 9 unterstützt SVG.
Beispiele für Bevölkerungspyramiden und Thematische Karten mit SVG
Wahlatlas mit SVG
Die Unterstützung von SVG im Firefox ist brauchbar und verbessert sich von Release zu Release. Allerdings unterstützt Firefox 3.0 noch keine SVG-Animation. Chrome und Opera unterstützen svg. - canvas: gutes prozedurales Vektorformat mit Unterstützung durch Firefox, Safari, Opera, Chrome ind IE9. canvas ist Bestandteil von HTML 5.
- VML: (MSDN) IE spezifisches Vektorformat.
Unterschiedliche Maßeinheiten für Linien, Kreiese etc.
und für Text machen vermutlich eine automatische Skalierung
einer Graphik auf die aktuelle Größe des Browserfensters
praktisch unmöglich.
Protovis ist eine Beschreibungssprache für svg-Datenvisualisierung von der Stanford Universität. - Silverlight: Plugin von Microsoft mit Unterstützung von Vektorformat XAML. Animationen sind ähnlich möglich wie in SVG.
- Flash von Adobe ist ein Plugin, das in fast jedem Browser installiert ist. Hauptzweck von Flash ist das Abspielen von Videos, aber es lassen sich damit auch Vektorgraphiken erzeugen.
Eine Flash Anwendung programmiert man mit flex als mxml-Datei und kompiliert sie zu einer swf-Datei, die man in eine html-Datei einbettet und die Daten (z.B. Koordinaten bei Dendrogramm oder Balkenlängen bei Pyramiden - max. 64kByte) mit flashVars übergibt.
Alternativ nutzt man das Paket Ming SWF zur dynamischen Generierung von swf-Dateien, die Unterstützung für Perl 5.10 und die Qualität sind jedoch unklar.
Beispiel für Flash-animierte Pyramiden Bertelsmann-Stiftung - eps (Encapsulated Postscript) kann aus gnuplot (z.B. Visualisierung Zeitreihen) und Perl/Tk (z.B. Glätten manuell) erzeugt werden. eps ist ein Vektorformat und eignet sich sehr gut zum Einbetten in Dokumente und Präsentationen. Die Größe kann beim Einbetten fast beliebig skaliert werden.
- Erstellung aller Graphiken mit gnuplot und Nutzung weniger gnuplot Formate (wxt, gif, png, svg)
- Einsatz von HTML5-Techniken svg und canvas
- Verzicht auf die dynamische Anpassung von Graphiken (Dendrogramm, Pyramide, Stromkreise) auf die Größe des Browserfensters und Ausgabe aller Graphiken als (animated) gif.
- Prüfung Plotly als Alternative
Die in SIKURS verwendeten csv-Dateien sind fehleranfällig, weil beim editieren mit Excel oder einem Texteditor Unsinn passieren kann. Die natürliche Speicherform für SIKURS ist eine Datenbank. Das Jahr ist immer in Spalte 1, d.h. es entfällt die Konstruktion, dass das Jahr manchmal in Spalte 1, manchmal im Dateinamen, bei GEM in Spalte 1 und Dateinamen steht. Für GEM bedeutet dies, dass sowohl das Jahr, das als Eingabe für die Prognose dient, als auch alle prognostozierten Jahre in der gleichen Tabelle GEM befinden.
Damit sind die Eingabedateien:
| ATTR | Jahr, GKZ, Wert |
| BGWQG | Jahr, TYg, BGm, BGk, Wert |
| BGWR | Jahr, TYw, BGv, BGn, GG, AG, Wert |
| DSGA/R | Jahr, GKZ, BG, GG, AG |
| ECKGEB | Jahr, Wert |
| ECKGEM | Jahr, Index, Gebietsnummer, Wert |
| ECKREG | Jahr, BG, GG, AG, Wert |
| ECKSTRB | Jahr, Wert |
| ECKSTRBG | Jahr, GKZ, Wert |
| ECKTYP | Jahr, Index, TYb, Wert |
| FRUC | Jahr, TYf, BG, AG, Wert |
| GEM | Jahr, GKZ, BG, GG, AG, Wert |
| NEBQ | Jahr, TYq, BG, GG, AG |
| NEBB | Jahr, GKZ, Wert |
| NEBGQT | Jahr, TYn, TYb, Wert |
| NEBQQA | Jahr, TYn, TYa, Wert |
| REAB | Jahr, GKZ, Wert |
| REAQ | Jahr, TYr, BG, GG, AG |
| REAQZA | Jahr, TYr, TYa, Wert |
| REAQZT | Jahr, TYr, TYb, Wert |
| REAR | Jahr, GKZ, Wert |
| SADVOL | Jahr, TYs, BG, GG, AG, Wert |
| STRB | Jahr, TYs, BG, GG, AG, Wert |
| STRM | Jahr, TYxv, TYxn, BG, GG, AG, Wert |
| WEGVOL | Jahr, TYA, BG, GG, Wert |
| WEGT | Jahr, TYa, BG, GG, AG, Wert |
| WEGV | Jahr, TYa, BG, GG, AG, Wert |
| WEGZ | Jahr, TYx, TYa, BG, GG, Wert |
| ZUAQ | Jahr, TYa, TYx, BG, GG, AG, Wert |
| ZUDQ | Jahr, TYa, BG, GG, AG, Wert |
| ZUVOL | Jahr, TYa, BG, GG, Wert |
| ZUVG | Jahr, TYa, GKZ, BG, GG, AG, Wert |
| ZUVL | Jahr, TYa, TYz, BG, GG, AG, Wert |
Die Eingabedateien GEMREF, TYPREF und AGGREF sind unter 74 beschrieben, die ini-Datei wird ersetzt durch eine Tabelle mit vielen Spalten (Startjahr, Endjahr, EPS, ...).
Die csv-Ausgabedateien:
| AGG | - entfällt, wird bei Bedarf aus GEM gebildet |
| B | Jahr, GKZ, Art, BG, GG, AG, Wert -- differenzierte Bewegungen |
| BEWAGG | - erfällt, wird bei Bedarf aus B gebildet |
| BEWGEM | - erfällt, wird bei Bedarf aus B gebildet |
| GEMYYYY | - Daten sind in GEM |
| PYRAMID | - entfällt, wird ad hoc gebildet |
| STROM | Jahr, TYx, TYx, BG, GG, AG, Wert |
| WEGZUG | - erfällt, wird bei Bedarf aus B gebildet |
Vorzusehen sind Dienstprogramme zum Import und Export in die Formate csv und xls. Beim Import werden die Daten auf Konsistenz geprüft. In der Datenbank sind die Daten immer expandiert, die Rolle der Generic-Daten wird von einem generic-Importprogramm übernommen.
Das Konzept enthält noch nicht die Verwaltung mehrerer Prognosevarianten mit den gleichen Daten. Dazu sind folgende Erweiterungen nötig
- Erweiterung der ini-Tabelle auf mehrere benannte Zeilen
- die Tabellennamen ATTR .. ZUVOL müssten nicht fest, sondern vom Benutzer zu vergeben sein und in der ini-Tabelle gepeichert werden
- Eine zusätzliche Tabelle ordnet dem SIKURS internen Datenquelle FRUC einen konkreten Tabellennamen FRUC_V3 zu.
- die Namen der Ausgabetabellen werden mit dem Versionsnamen verknüpft
- Der Sonderfall GEM (sowohl Ein- als auch Ausgabedatei) muss noch gelöst werden, z.B. als Kopie mit Namen der Version.
Die zu verwendende Datenbank muss Schnittstellen zu C++ und Perl besitzen. Mögliche Datenbanken sind (Duva ist mehr als eine Datenbank und kann schon jetzt zur Verwaltung der SIKURS Daten verwendet werden), snowflake, Exasol, Oracle, DB2, Access, FoxPro, SQL-Server, MariaDB, MySQL, Postgres, Apache Derby, BerkeleyDB, dBase, Filemaker, Firebird, Interbase, MaxDB, Paradox, SQLite, DuckDB, HDF5.
- SQLite
- wurde getestet uns scheint sich zu eignen.
Es gibt einen Prototyp für die Bausteinkombinationen I0-1, K0-4
Man wählt eine vorhandene ini-Datei und das Programm sqlite.pl lädt alle Eingabdateien und Laufparameter in die Datenbanksqlite.db3.
Der Prototypsikern.exerechnet die Prognose auf der Datenbank.
SQLite ist eine open source Datenbank, sie wird beispielsweise von FireFox (ab Version 3?), Google-Gears und Adobe AIR verwendet.
Mit dem FireFox-Plugin SQLite Manager kann man eine SQLite Datenbank bearbeiten (ähnlich Access oder Open Office Datenbankmanager).
Bei Perl (und PHP) ist sie im Standard-Lieferumfang. Die C/C++-Schnittstelle ist in den frei verfügbaren Quellen enthalten. Zu klären ist, ob es Versionsprobleme zwischen Perl und C++ gibt. Eine Datenbank mit vielen Tabellen entspricht einer Datei.
Die Organisation der vielen Protokolldateien ist noch festzulegen
Beispiel: Alle Daten einer Prognose liegen im Verzeichnis NBG mit der Datei PROGNOSE.DB3, INDEX.HTML und dem Unterverzeichnis P - DuckDB
- ist eine in-process
OLAP
SQL Datenbank mit Python/R/C++-Schnittstelle
und Import/Export von csv und parquet-Dateien
parquet - Dateien sind eine effiziente Alternative für csv-Dateien.
Zum Test kann mat mit dem cli-Interface von DuckDB eine csv-Datei aggregierenSELECT BG, GG, sum(Anzahl) FROM read_csv_auto('gem1991.csv', decimal_separator=',') GROUP BY BG, GG; ┌───────┬───────┬────────────────────┐ │ BG │ GG │ sum("Anzahl") │ │ int64 │ int64 │ double │ ├───────┼───────┼────────────────────┤ │ 1 │ 1 │ 42867.39071 │ │ 1 │ 2 │ 47199.813660000014 │ │ 2 │ 1 │ 7034.68125 │ │ 2 │ 2 │ 5508.755260000002 │ └───────┴───────┴────────────────────┘eine csv-Datei in eine parquet-Datei umwandeln:COPY (SELECT * from read_csv_auto('gem1991.csv')) TO 'gem1991.parquet' (FORMAT 'parquet'); - HDF5
- HDF5 verwaltet ein hierarchische Sammlung mehrdimensionaler
Matrizen, HDF5 ist eine Instanz des im Penta-Projekt geforderten
Penta-Quaders.
Eine HDF5 Datei könnte die Daten aller Eingabedateien eines SIKURS-Datenverzeichnisses (REFTYP, GEM, FRUC, STRB, ...) sowie aller Ausgabdateien aller Versionsuntervezeichnisse (GEM, BEW, ...) enthalten.
Die Daten werden selbsbeschreibend, plattformübergreifend, binär, kompakt mit schnellem Zugriff gespeichert.
Möglicherweise ist die Perl-Schnittstelle PDL::IO::HDF nicht brauchbar.
Der Autor ist skeptisch, falls doch, muss die Spaltenstruktur diskutiert werden. Naheliegend ist es den Statistikdatensatz mit einem C++-Programm zu lesen und die Makrodaten in die Datenbank einzufügen.
siehe Spiegel
Sehr geehrter Herr Braunschober,
folgende Beschreibung stammt von meinem Kollegen Chris Kurt, der sich mit der technischen Seite unserer Visualisierung beschäftigt hat:
There are two maps with 96 regions of Germany build from free Shapefiles (http://de.wikipedia.org/wiki/Shapefile) and converted with Python (https://www.python.org/) into TopoJson-files (http://en.wikipedia.org/wiki/TopoJSON). The distortion of the map is done with a Javascript Cartogram (http://en.wikipedia.org/wiki/Cartogram Solution based on this http://prag.ma/code/d3-cartogram/#births/2011.
Furthermore the Application uses RequireJS, Jquery and D3.
requirejs.org
jquery.com
d3js.org
Ich hoffe, Ihnen damit weitergeholfen zu haben.
Mit besten Grüßen
Christina Elmer (christina_elmer@spiegel.de)
wib: testweise Umwandlung shapefile in TopoJSON:
nodejs.org
python.org 2.7.7
npm install topojson rw d3 optimist shapefile queue-async d3-geo-projection
node bin\topojson -o test.json test.shp
test.json:
{
"type":"Topology",
"objects":{
"test":{
"type":"GeometryCollection",
"bbox":[0,0,180,170],
"geometries":[
{
"type":"MultiPolygon",
"arcs":[[[-1]],[[1]]]
},
{
"type":"Polygon",
"arcs":[[2]]
},
{
"type":"Polygon",
"arcs":[[2]]
}
]
}
},
"arcs":[[[1111,1176],[0,589],[556,0],[-556,-589]],[[0,0],[5555,0],[0,5882],[-5555,0],[0,-5882]],[[8333,8823],[555,0],[1111,1176],[-1666,-1176]]],
"transform":
{
"scale":[0.018001800180018002,0.017001700170017002],
"translate":[0,0]
}
}
Probleme:
- läuft nicht unter Windows 8.1 64-Bit
- eignet sich nicht für eine Integration in SIKURS, da zu viel externe Software (node, python und viele Javascript Bibiliotheken) benötigt wird.
- 1000-er Trennzeichen
Überarbeitung Ausgabe der Gleitkommazahlen ins Protokoll und in csv-Dateien
Bei der Ausgabe ins Protokoll ist die Voreistellung 1000-Punkt und eine feste Anzahl Nachkommastellen (2 bei Anzahl, 6 bei Rate/Quote), weil sich dieses Format gut lesen läßt. Zur genauen Überprüfung der Ergebnisse kann man das Format auf maximale Genauigkeit (defaultfloat/width(15)) umstellen.html csv Beispiel defaultfloat/width(15) (*) 1234,567 scientific/width(15) 0,1234567e004 fixed/precision(2/6) (*) 1234,56 1000-Punkt (*) 1.234,56
Bei Ausgabe nach csv empfiehlt sich maximale Genauigkeit (da man das Anzeigeformat in Excel selbst bestimmen kann). Wenn benötigte Nachfolgeprogramme kein scientific-Format (0,123456e004) verarbeiten können, dann kann man auf z.B fixt/precision(12) ausweichen.
Der 1000-Punkt hängt von der Ländereinstellung ab (z.B. deutsch 1.234,567, Schweiz 1'234.567, english 1,234.567) - Ausgabe gem.csv statt gem2015.csv .. gem2025.csv (!GEMALL 1/2)
zum Standard machen mit weiteren Auswirkungen
- Aggregation Zeitreihe in Startmaske Prognose
Option entfernen, falls nicht mehr benötigt, oder auf neue Datei gem.csv umstellen - Ergebnis Zeitreihe auf gem.csv anpassen
- Bedienung Visualisierung Pyramiden Einzelpyramiden anpassen
- Reporting
- Haushalteprognose an Eingabedatei gem.csv anpassen
- Aggregation Zeitreihe in Startmaske Prognose
- Anpassung Klassenstruktur an modernes C++ (siehe vc/cx11/sikern_class2.cpp)
- Anpassung an C++20:
- modules (.../SUL/sibatch/sibatch.sln)
- concepts
- std::execution::par/par_unseq
- std::ranges
- std::format
- filesystem
- Anpassung an C++23:
- linear algebra library with multidimensional vector support (mdspan/mdarray)
- std::print mit "python style format" incl. locale specific 1000-Trennzeichen
std::locale::global(std::locale("German_Germany.1252")); std::print("{:L.2f}", BG41[G,BG,GG,AG]);
- alle n-Jahre statt nur für Start- und Endjahr der Prognose
für welche Graphiken (Abb 1), Tabellen (Tab3, Tab4 wie?) ?
Bei einer Prognose 2001 bis 2013 und "alle 5 Jahre": 2001 2006 2011 2013? - Ausgabe wahlweise als html oder pdf
Dafür gibt es einige Optionen- Warten auf Windows 10:
Der neue Browser "Edge" kann html-Seiten als PDF drucken - Installation eines PDF-Druckertreibers
- HTML in PDF umwandeln
- Einsatz einer Bibliothek, die das Erzeugen von pdf aus dem Programm ermöglicht, z.B. PDF::Haru
- Warten auf Windows 10:
- weitere Indikatoren
- t.b.d.
Der aktuellen Installation von SIKURS fehlt die Möglichkeit SIKURS durch "Systemsteuerung/Programme deinstallieren" zu löschen.
Dies könnte druch den Einsatz von "Advanced Installer" für MSI Dateien verbessert werden (siehe sikurs/source/ai).
Dies würde allerdings die Option SIKURS ohne Admin-Rechte in ein Verzeichnis der Wahl (z.B. C:\SIKURs_10_1) zu installieren und evtl. mehrere SIKURS-Vesionen paralell zu betreiben einschränken.
Einbeziehung Flüchtlinge
wib: Wenn man den Gebieten Schwerpunktkoordinaten (eigene Datei
center.csv oder zusätzliche Spalte in
reftyp.csv) zuordnen kann,
oder eine Distanzmatrix der Entfernungen vorgibt,
dann könnte man die Entfernungen zwischen Gebieten zur Berechnung
von Attrativitäten zur Gewichtung des "freien Wohnangebotes" bei der
Aufteilung des Binneneinzugs pro Quellgebiet verwenden.(siehe Baustein V)
wurde auf Lenkungsausschuss 2018 kontrovers diskutiert
- Vergleich Bevölkerungspyramiden
Mit Visualisierung/Pyramiden/Einzelpyramiden wählen Sie die Ergebis-gem-Datei eines Referenzjahres ihrer Referenzprognose.
Wählen Sie im MenüEinzelpyramiden [Vergleich mit expost Prognose %file%, Abschnitt %key%, Summe %sum%] Bildüberschrift ... [v] Auswahl Nebenpyramiden
und wählen die die Ergebnis-gem-Datei des gleichen Jahres Ihrer Vergleichsprognose
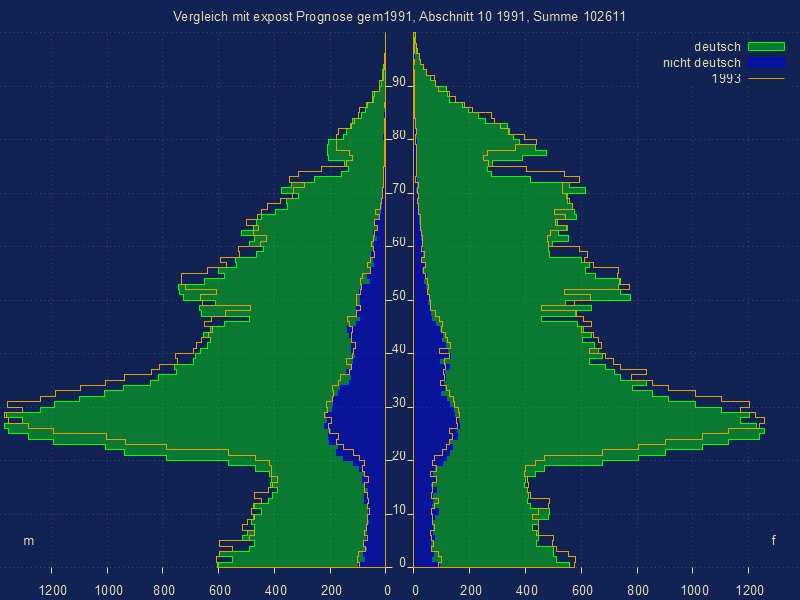
- Vergleich Indikatoren
Für eine ex-post-Prognose von 2003 bis 2017 benötigen Sie (möglichst) alle Statiskdatensätze Bestand und Bewegung von 2000 bis 2017.
Aus des Statistikdatensätzen 2000-2003 leiten Sie die Makrodateien und anschließend Sikurs-Eingabedateien für eine oder mehrere Variantenprognosen von 2003 bis 2020 ab.
Die Ergebnisse der Prognose sind gem2003 bis gem2020, bew, Indikatoren und Reporting.
Aus den Statiskdatensätzen 2000-2017 (im Beispiel fehlen 2013, 2014) leiten Sie Ihre gewünschten Indikatoren ab. Dazu wird ein neues Programm benötigt, das die Indikatoren entweder direkt aus dem Statistik-Datensatz, oder über die abzuleitenden Makrodateien errechnet.
Indikatoren der Prognosen (Summe Bevölkerung, Medianalter, Lebenserwarung, ...) in einer gewünschten Differenzierung (Untersuchungsraum, Gebiet, ..., Räumliches Aggregat n (siehe reftyp)) entnehmen Sie den Tools Indikatoren und Reporting (oder neue Indikatoren aus Daten der Datei bew, z.B. Summe und Medianalter Rückbauendauszug ins Untersuchungsgebiet - siehe 077).
Damit können Sie viele Zeitreihen plotten:
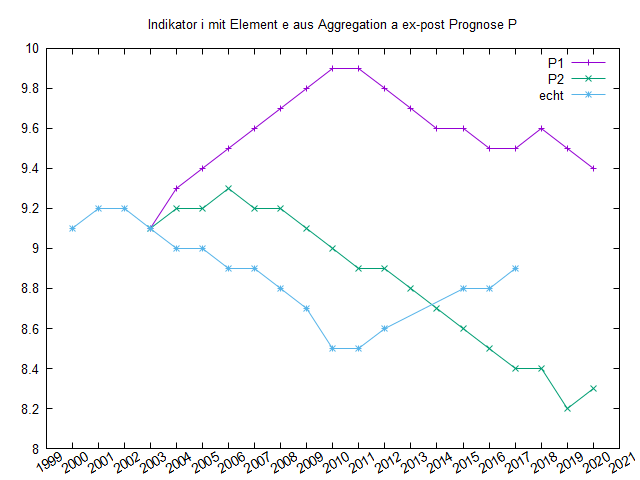
(plot commands)
siehe Zwischengeschlecht
Hat das Bundesverfassungsgerichts-Urteil vom 8.11.2017 zur Intersexualität Auswirkungen auf SIKURS ?
Im Dokument KOSIS-DST_Bestand_2021-02.pdf ist P02 nach wie vor binär (1) männlich, (2) weiblich, genaueres siehe
Weitere Merkmale P02MR 330 01 Geschlecht (DSMeld 0701) (m) männlich (w) weiblich (d) divers (62:nach § 22 Abs. 3 Personenstandsgesetz sowie § 45b Personenstandsgesetz) (x) ohne AngabeMit einer kleinen Erweiterung von SIKURS könnte man die Modellierung des Geschlechts dem Nutzer überlassen:
- das Feld Geschlechtsgruppe kann (wie die Bevölkerungsgruppe) Werte 1..n (n ≥ 1) annehmen
- die Datei
frucbekommt zusätzliche Spalte Geschlechtsgruppe und der Anwender muss dafür sorgen, dass die Geschlechtsgruppe für männlich keine Geburtenraten > 0 und die Geschlechtsgruppe "divers" vermutlich niedrige Geburtenraten enthält. Personen "ohne Angabe" kann man entweder die halbe Geburtenrate von "weiblich" zuweisen, oder sie je zur Hälfte auf "männlich" und "weiblich" aufteilen. - Eine neue Datei in den Varianten für 1, 2 und mehr Geschlechtsgruppen
GP.csv: GP.csv: GP.csv: GP.csv (mit Geschlechtsbezeichnung): #GG;Rate #GG;Rate #GG;Rate #GG;Rate ;Kürzel;Bezeichnung 1;1 1;0,512 1;0,512 1;0,510;m;männlich 2:0,488 2;0,486 2;0,485;w;weiblich 3;0,002 3;0,002;d;divers 4;0,003;x;ohne Angabe ... ...mit Ratensumme 1 legt Anzahl Geschlechter fest und verteilt die Geburten auf die Geschlechter
- klassisch mit 1 (oder 2) Geschlechtern
- mit einem 3. Geschlecht "divers" und 4. "ohne Angabe"
- mit männlich, weiblich und vielen "diversen" Untertypen
Bei der Visualisierung als Pyramide könnte man je die Hälfte von "divers" und "ohne Angabe" auf männlich und weiblich aufteilen und wie die Bevölkerungsgruppe farblich abgrenzen.
Auswirkungen auf Berechnung von Indikatoren müssen diskutiert werden.
das Problem taucht (ausser in Stuttgart bei Baustenkombination B1D1I1K1M1P4R1W1Y1) häufiger auf.
s,w: Ein Teil des Problems können wegen hoher Differenzierung sehr
dünn besetzte Eingangsdateien wie wegz und strm
sein.
Dadurch haben einzelen Bevölkerungsgruppen (z.B. 96-jährige) sehr hohe
Wegzugsraten, die zu negativer Bevölkerung dieser Altergruppen führen.
Da Nachbargruppen viel zu niedrige Wegzugraten haben,
läßt sich dies durch Glätten oder besser durch Bildung von
wenigen Altersklassen bei der Berechnung dieser Dateien aus den Makrodateien
verbessern.
Weiterhin könnte man prüfen, ob es Sinn macht zu große Wegzugsraten zu
reduzieren, statt später im Programm entstehende negative gem-Werte wegen
a) negative Wanderungsbilanz > Bestand
b) Sonderbevölkerung > Bestand
auf 0 zu setzten
und dadurch die Ziewerte zu verfehlen.
siehe auch 043_2 (dynamische Bevölkerungsbewegung - verkürztes Prognoseintervall)
m,u: Wegzugsraten > 1 entstehen beim Bezug von Stromgrößen (Wegzugsvolumen) auf Bestandsgrößen an einem Tag X (Einwohnerzahl). Wenn also die
durchschnittlichen Wohndauern in bestimmten Altersjahrgängen niedrig sind (unter 1 Jahr), ist der Bezug auf ein (zu langes) Zeitintervall (von einem Jahr)
in dieser Art der Berechnung wohl problematisch.
Singapur hat eine Exportquote von fast 200% (200% des Inlandsprodukts wird innerhalb eines Jahres exportiert). Dies liegt daran, dass Singapur ein
Umschlagsplatz ist und dass viele Waren zunächst importiert werden und dann nach einer Lagerzeit (kürzer als einem Jahr) wieder exportiert werden. Bei
jahrgangsspezifischen Wegzugsraten über 1 werden die vielen Bevölkerungsim- und -exporte eines bestimmten Jahrgangs innerhalb eines Jahres und die sequentielle
Abfolge der Berechnungen wohl zum Problem (Großstädte haben bei manchen Altersgruppen quasi die Funktion der Welthäfen im Handel).
Ich sehe die Problemlösung weniger bei Glättung (ich erkenne zumindest im Verlauf der Kurve eine gewisse Systematik in den Raten), sondern einer Verkürzung des
Prognoseintervalls (man könnte bei sehr hoher Mobilität der Bevölkerung das Prognoseintervall auf ein halbes Jahr herabsetzen und so die "Exportquoten" unter
die 1 drücken, das Prognoseintervall muss dafür kürzer als die durchschnittliche "Lagerzeit" sein). Im Kern handelt es sich wohl um ein Taktungsproblem: ein
Prognoseintervall, dass den Wohndauern in einzelnen Altersjahrgängen (und Typen) nicht angemessen ist. Wenn SIKURS also negative Bevölkerungszahlen feststellt
(Wegzugsraten > 1), könnte man rechnerisch vielleicht eine Lösung finden, indem man das Prognoseintervall von einem Jahr (im Hintergrund) künstlich
unterteilt, sodass zumindest außenwanderungsbedingt zu keinem Zeitpunkt negative Einwohnerzahlen vorkommen können. Außenwegzugsraten > 1 sind aus meiner Sicht für den Anwender eigentlich ein Zeichen, dass sofern die Raten sorgfältig generiert wurden und er bei einer jahrgangsspezifischen Rechnung mit der gleichen
Gebietstypisierung bleiben will, ein kürzeres Prognoseintervall als 1 Jahr angezeigt ist.
m,h: Bestandsmindernde Raten < -1 und damit verbunden - wenn auch nicht zwangsläufig, aber auch nicht unvermeidbar - negative Bestandszahlen sind Hinweise auf konzeptionelle Schwächen eines Prognoseansatz, der Bewegungen eines Jahres mit Raten bestimmt, die auf den Bestand zum 1.1. des Beobachtunsgzeitraums bezogen sind. Während des Beobachtungszeitraums können nämlich mehrere Entwicklungen die Besetzung der Bevölkerungsgruppe verändern, auf die die Bewegungsdaten bezogen werden. Wie oben bereits dargestellt können bei wachsenden, bei abnehmenden Bevölkerungsbestand oder bei kurzer Verweildauer der Wandernden die auf den Bestand vom 1. Jan. bezogenen Ausprägungen der Raten die Verhaltensweisen nicht zutreffend abbilden.
Aus diesem Grund werden die Raten der amtlichen Statistik aus den Werten der im Jahr beobachteten Bewegungen und der durchschnittlichen Jahresbevölkerung bestimmt. (Durchschnittliche Jahresbevölkerung = Mittelwert von 12 mittleren monatlichen Bevölkerungsbeständen). Die Aufteilung eines Jahres in mehrere, kurze Beobachtunsgzeiträume berücksichtigt, dass die Bewegungen in einer Bevölkerungsgruppe zeitgleich verlaufen und die Fehler, die bei der Vernachlässigung dieser Tatsache in Kauf zu nehmen sind, umso kleiner werden, je kürzer die Zeiträume innerhalb der die Bewegungen registriert und damit die zeitlichen Abstände zur Aktualisierungen der Bezugsbevölkerung werden.
Die für die Prognoserechnungen beschriebenen negativen Konsequenzen lassen sich zwar nicht gänzlich vermeiden jedoch erheblich mindern. Mit der Unterteilung einer Prognoseperiode in mehrere Simulationsrechnungen für kürzere Zeitintervalle wird die Nichtbeachtung der Gleichzeitigkeit erheblich entschärft. Das Prognoseergebnis zum Jahresende wird so als Fortschreibung der Ergebnisse von mehreren - monatlichen/ vierteljährlichen- Simulationsrechnungen bestimmt. Voraussetzung ist, dass auch die Datenaufbereitung entsprechend modifiziert wird, indem auch die Bewegungsparameter nicht auf den Ausgangsbestand zum 1. Jan. des Beobachtungszeitraums sondern auf den mittleren Jahresbestand bezogen werden.
Eine entsprechende Weiterentwicklung des SIKURS -Programms würde die Gültigkeit der Prognoseergebnisse verbessern und vermeidbare Unschärfen beseitigen. Diese Änderungen sind mit überschaubaren Aufwand machbar, weil - anders als bei den altersspezifischen Raten - die Bezugsbevölkerung der Sikurs-Prognoserechnungen und damit der Ratenberechnung durch das Geburtsjahr festgelegt werden; d.h. dass der Alterungsprozess der Bezugsbevölkerung im Laufe des Jahres nicht mit abgebildet werden muss.
Um eine Basis zur Abschätzung des Arbeitsaufwands und des Nutzens der vorgeschlagenen Änderung zu haben, wäre es sinnvoll, für eine entsprechende
Voruntersuchung und für die Überprüfung von Prognoseergebnissen, die mit der aktuellen SIKURS-Version und mit einer Werkstattversion der geänderten
SIKURS-Version ausgeführt wurden, ein Stundenkontingent von xy vorzusehen.
(s,b: mit synthetischem Beispiel oder in Zusammenarbeit mit einem Anwender mit Beispiel mit hohen bestandsmindernden Raten und zugehörigem Statiskdatensatz ?)
Ehlert: Berechnung der z.B. Sterberaten aus den Makrodateien:
Sterberate = Sterbefälle 2017 / Bestand Mitte 2017
Für die Berechnung der Makrodatei "Bestand Mitte 2017" aus dem Statisitikdatensatz gibt es zwei mögliche Methoden:
- (Bestand 2107 + Bestand 2018) / 2
- Bestand 2017 + Anwendung aller Bewegungen 2018 bis 31.06.2018
Zum besseren Verständnis der in den Laufprotokollen dokumentierten Sikurs-Berechungen und der EXCEL-Bespiele (roadmap 053) sollen die SIKURS-Berechnungen dokumentiert werden.
Dafür gibt es folgende Alternativen:
- Handy-Fotos von Handzeichnungen
- Ablaufdiagramme
Ein Ablaufdiagramm zeigt die Schrittweise Umformung der Eingabedateien in Matitzen und schließlich Ausgabedateien.
Jede Bausteinkombination der Excel-Beispiele kann in jeweils 2 Ablaufdiagramme abgebildet werden. Das erste Diagramm soll lediglich die Elemente der dargestellten Bausteinkombination enthalten, dazu passend sollen im zweiten Diagramm, das die Pfade für alle zulässigen Bausteinkombinationen darstellt, der Pfad der aktuellen Bausteinkombination grafisch hervorgehoben sein (siehe Beispiele).
Die Ablaufdiagramme mussten überarbeitet werden, weil z.B. in T0 der Pfeil von reftyp nicht zu BGEM, sondern zu DG1G und DG4S gehen muss.# Excel-Beispiel Diagramm 01 A0bisY0 T0 (existiert) 02 A1E2I1K6M2R2S2T1 AEIKMRST 03 A1I1K4M2T1W1-BG3GG2 AIKMTW 04 A1I1K5M1T1V1 AIKMTV 05 B1D1G1I1K1M1R1S1T1 BDGIKMRST 06 B1E1I1K2M2R2T1 BEIKMRT 07 C1G1I1K2T1 CGIKT 08 C2I1K3T1 CIKT 09 C3I1K4T1 =#= 10 C4I1K5T1 =#=
Der Nutzen dieser Ablaufdiagramme ist beschränkt, da die Rechenwege in Excel und Programm nicht identisch sind. - erzeugung Ablaufdiagramme mit Graphviz
Die Ablaufdiagramme, die aus den Programmquellen generiert werden, nutzt Kommentare im C++ Quellcode in DOT Language.
Anlaog könnte man in einem Excel-Beispiel auf einem eigenen Blatt "DOT" die Beischreibung eines Graphen eingeben:digraph SIKURS { rankdir=LR; node [shape=box,width=.4,height=.2] labelloc="t" label="Ausschnitt Datenfluß I1P2" gem2019 [shape=oval tooltip="Anfangsbevölkerung"] reftyp [shape=oval tooltip="Abbildung Gebiet Typen"] REF [tooltip="Abbildung Gebiet Typen"] fruc2000[shape=oval tooltip="Fruchtbarkeitsraten"] DG3G [tooltip="Geburten\nDG3G[G,m]+=BG40a[G,w]*GP*fruc2000[reftyp[G,TYG]]\nDG3G[G,w]+=BG40a[G,w]*(1-GP)*fruc2000[reftyp[G,TYG]]"] GP [shape=diamond tooltip="Geschlechterproportion"] BG40a [tooltip="Anfangsbevölkerung gealtert"] BG40 [tooltip="Ausgangsbevölkerung"] reftyp -> REF gem2019 -> BG40a [ label="AGF" labeltooltip="Altersgruppenfortschreibung"] REF -> BG40a { BG40a REF fruc2000 GP } -> DG3G { BG40a DG3G } -> BG40 [label="+" labeltooltip="Summe"] }und mit folgendem Befehl in eine SVG-Graphik wandelndot -Tsvg -oI1P2.svg I1P2.dot
- doxygen Dokumentation des Programms
Aus den Programmquellen kann mit doxygen eine Dokumentaion erstellt werden, die als Vergleich zur Excel-Dokumentaion und dem Prognoselaufprotokoll herangezogen werden könnte.
Die Programmquellen müssten dafür aktualisiert werden, wobei auf Kompatibilität mit den Visual Studio XML Kommentaren zu achten ist.
Die XML Kommentare werden für IntelliSense benötigt. - die XML-Kommentare können mit DocFX und Sandcastle zu einer Dokumentation weiterverarbeitet werden.
{kind=link}
m,h: Beim Baustein P0 werden bei der Innenwanderung, d.h. der Wanderungen zwischen den Gebietseinheiten eines Typs, die Auszüge aus den einzelnen Gebietseinheiten als Einzüge in die einzelnen Gebietseinheiten des zugehörenden Binnentyps bestimmt. Die Zuordnung auf die einzelnen Gebietseinheiten ist orientiert an den freien Wohnkapazitäten der einzelnen Gebietseinheiten.
Bei den Baustein P(x)|x>0| werden die Ströme in einer Verflechtungsmatrix den vom Anwender vorgegebenen Zielwerten angepasst. Bei der rekursiven Anpassungsrechnungen der Verflechtungsmatrix (1), in der die Ströme der Innenwanderung zwischen den Gebietseinheiten des betrachteten Binnentyps abgebildet werden, bleibt das Wanderungsvolumen konstant, angepasst werden die Einzüge in die einzelnen Gebietseinheiten. Damit bleibt auch die Anzahl Stayer je Gebietseinheit konstant, d.h. derjenigen, die nicht ihre Wohnung wechseln.
Wir schlagen vor, das Wanderungsvolumen und damit auch die Anzahl Stayer bei den Anpassungsrechnungen zu modifizieren und zu dynamisieren.
Die Ergebnisse der beiden Anpassungsrechnungen (1) und (2) sind am Beispiel von drei unterschiedlichen Ausgangssituationen in den pdf-Dateien im Anhang dargestellt und mit den jeweiligen Ausgangsdaten verglichen.
Die Beispiele für die beiden alternativen Ansätze zeigen, dass
- die Ergebnismatrizen der Vorgehensweise (2) der Ausgangsmatrix ähnlicher sind als die Ergebnismatrizen der Vorgehensweise (1);
- bei der Vorgehensweise (1) sind die Restriktionen für die Vorgaben der Spaltenziele erheblich größer als bei der Vorgehensweise (2). Die Vorgehensweise (2) hat demnach ein erheblich weiteres Einsatzspektrum als die Vorgehensweise (1): Bei (2) kann der Zielwert für eine Gebietseinheit bei den Anpassungsrechnungen bis auf 0 herabgesetzt werden, bei (1) muss der Zielwert für eine Gebietseinheit bei den Anpassungsrechnungen >= die Anzahl Stayer der Gebietseinheit.
wib:
Fragen:
- welche Variante entspricht der aktuellen SIKURS-Version ?
(sollte Vorgehensweise (2) sein, führt (z.B. beibeispiel/baustein/I1P1T1) wegen der Anpassung vonDG5FIundSTAYERzu Abweichung der Ausgabedateienstrom.csvundgstrom.csv(aggregiert auf Binnentypen)
(erkennbar durch
[ 6] Ausgabe Binnenmatrix
undblackbox_test 1, 1;in Befehle nach der Prognose
Lösung: Anpassung der Modifizierten Stayer instrom.csv? - soll eine Variante festgelegt werden, oder Option auf beide Varianten ?
m,h: Weitere 10 Excel-Beispiele mit den Bausteinen P(x) |x>0| und der Baustein-kombination (A1-B1, N(x) |x>0|) simultane Anpassung von Zu- und Wegzug. Diese Bausteinkombinationen wurden bislang ausgespart, weil für die die iterativen Berechnungen tools bereitgestellt werden müssen.
wib:
Eine systematische Überprüfung des Bausteins P könnte so aussehen:
- Prüfe I1P2T1, d.h. ob die Grenzwerte von
ecktypeingehalten werden - Prüfe I1P1T1, weil die Grenzwerte von
eckgemGrenzwerte der Binnentypen umd Grenzwerte der Gebiete ergänzen - Für die Grenzwerte P1/2 sind folgende Fälle relevant
- (Untergrenze = Obergrenze) = Zielwert
- Untergrenze < Obergrenze
- fehlende Unter- oder Obergrenze
- Bei mind. 1 Gebiet/Typ fehlt Unter- und Obergrenze
- Prüfe zusätzlich Zielwert Bevölkerungsbestand M1/M2 mit den Untervarianten
- Anpassung Außenwegzug A1
- Anpassung Außenzuzug B1 und zusätzlich Vorgabe Außenzuzug K1-K6
- Prüfe statt Baustein M Bausten N1/N2/N3/N4 Zielwert Außenwanderung mit den Untervarianten
- A1 Anpassung Außenwegzug
- B1 Anpassung Außenzuzug und K1-K6
- A1 + B1 simultane Anpassung Außen-weg- und -zu-zug und K1-K6
- Neubautätigkeit D1
- Rückbau E1/E2
- Zielwet Geburten G1/G2
- Zusätzliche Vorgabe Außenzuzug K1-K6 bei Anpassung Außenwegzug A1
- Ausschluss demografischer Gruppen R1/R2
- Zielwert Sterbefälle S1/S2
- Attraktivität von Gebieten V1
- Wechsel von Bevölkerungsgruppen W1
- Gesonderter Bevölkerungsgruppenwechsel der Altergruppe 0 Y1
- I1P2T1 - ohne Zielwerte für die Außenwanderung
- A1I1M1P2T1 - Anpassung Außenwegzug an Zielwert Bestand
- B1D1I1K1M1P2R1T1W1Y1 - Anpassung Außenzuzug an Zielwert Bestand (+ D1 R1 W1 Y1)
- A1I1K1N1P2T1 - Anpassung Außenwegzug an Zielwert Außenwanderungssaldo
- B1I1K1N1P2T1 - Anpassung Außenzuzug an Zielwert Außenwanderungssaldo
- A1B1I1K1N1P2T1 - Anpassung Außen-zu+weg-zug an Zielwert Außenwanderungssaldo
Sollen die Variablennamen in den Excel-Beispielen, den Programmquellen, in
datadict_de/en.csv, im Protokoll und im Datenflußgraph
auf Konformität mit den
Namenssystematik überprüft und bei
Bedarf angepasst werden werden,
z.B.
eva.csv: # Anpassung Variablennamen C++ and Excel #C++;Excel ATTR;GG1ATTR BG01;BG21E DG1G;(ist im Graph aber nicht in Protokoll) PR2G;PR3G DG3G;DG2G DSGA;BG40DSG DSGR;QG40DSG ECKGEB;DU01GE ECKGEBG;DG11GE ECKSTRB;DU01SE ECKSTRBG;DG11SEDiese vom Methondenexperten für die Erstellung der Excel-Beispiele gepflegte Datei
eva.csv kann als Vorgabe für einen Auftrag an die
Sysrtemtechnik die Namenssystematik in den C++ Programmquellen zu verbessern
herangezogen werden.
hst:
Ich habe mir die Namenssystematik angesehen:
Wenn alles konsequent der Systematik entsprechend geändert werden soll, dann wird dies ein Mamutvorhaben: ca. 90 Namen müssten geändert werden, wenn R in T, W
in O, Z in I und die Angabe der Dimensionen (ohne dabei die Jahreszahl mit einzubeziehen) konsequent angepasst würden. Es sollten daher die ersten 2 Zeichen
erhalten bleiben und nur dort geändert werden, wo sie nicht der Systematik entsprechen. Bei der Angabe zur Anzahl Dimensionen gibt es widersprüchliche Aussagen.
Das finde ich schlecht.
Die allgemeine Systematik wird nicht eingehalten bei der Verwendung von Namen wie ECKSTRB, SFAK, saldvol, rueckbaub, rueckbauweg, reaq. Das sind die Namen der Inputdateien, die Namen ihrer Variablen nehmen die Bezeichnung der Datei auf. Das Prinzip ist aber nur in Ausnahmefällen beibehalten.
wib:
Besprechung hst - wib 26.05.2023 in München:
Eine Unterstützung des Methodenexperten durch die Systemtechnik ist sinnvoll
und notwendig zu mindestens folgenen Themen
- Namenssystematik mit der optionalen Datei
eva.csvzur Anpassung einzelner C++-Variablennamen and die EXCEL-Variablennamen - Test und evtl. Anpassung der Optionen (Einwohner/Prognose/Berechnen/?/Notiz/Optionen)
$PUT_IPF 1
$FIT_BW 2
und dem Script
Extras/Eigene Scripts/Start/IPF.pl
zur Synchronisation der Excel-Beispiele an die Zielwertanpassung Binnenwanderung P2 mit Eingabedateiecktyp.csvim C++ Programm - Varianten der Anpassung von Binnenwanderung an Zielwerte mit Option
$FIT_BW n- classical IPF
- factor estimation
- ADETON Verfahren
- Für die Anpassung Binnen- und Innenwanderung
(P1 Datei
eckgem.csv) erfolgt die Anpassung der Binwenwanderung wie bei P2 und für die Anpasssung der Innenwanderung wird für jeden Binnentyp eine DateiIPFjahr_tyb.csv(z.B.IPF2027_3.csv) für das ProgrammIPF.plausgegeben. Nach der Anpassung durch IPF.pl können die ErgebnisdateienIPFjahr_tyb_fit.csvmir der Ausgabedateigstrom.csvdes C++ Programms verglichen werden. - Für die Anpassung der Außenwanderung an ein Außenwanderungssaldo (A1,B1,N1-4) muss die Schnittstelle Excel-C++
(Eingabe Außenwegzug, Außenzuzug, Außenwanderungsbilanz
saldvol.csv, Ausgabe Außenwegzugwegzug.csv, Außenzuzugzuzug.csv) noch konzipiert, programmiert und getestet werden.
Für P1/P2 kann die Schnittstelle C++ Excel bei Bedarf neu konzipiert werden.
Optionen sind- Nutzung Paket
mipfp
für R oder
ipfn
für Python (siehe
IPF Implementation) mit Beispiel nach
sudo pip install ipfn#!/usr/bin/python # https://pypi.org/project/ipfn/ import numpy as np from ipfn import ipfn m = [[40, 30, 20, 10], [35, 50, 100, 75], [30, 80, 70, 120], [20, 30, 40, 50]] m = np.array(m) xip = np.array([150, 300, 400, 150]) xpj = np.array([200, 300, 400, 100]) aggregates = [xip, xpj] dimensions = [[0], [1]] IPF = ipfn.ipfn(m, aggregates, dimensions, convergence_rate=1e-6) m = IPF.iteration() print(m)
- Berechnung in Excel mit IPFP oder Beispiel für 2d 3d 4d oder Programmierung IPF mit VBA oder C# in Excel
- Ausgabe der anzupassenden Daten im C++-Programm als
IPF.plkompatible csv.Datei, Anpassung durchIPF.pl, Import Ergebnis nach Excel - Anpassung der Daten im C++-Programm und Import der angepassten Daten in Excel.
- Anpassung der Daten mit "IPF factor estimation" im C++ Programm, Ausgabe von Zeilenkorrekturfaktor (ZKF), und Spaltenkorrekturfaktor (SKF) als csv-Datei, Import dieser Datei in Excel zur Berechnung der angepassten Daten aus den Ausgangsdaten.
- Nutzung Paket
mipfp
für R oder
ipfn
für Python (siehe
IPF Implementation) mit Beispiel nach
Vor Beginn der Arbeiten sollte diskutiert werden, ob das Anpassungsverfahren
in Excel und C++ von "classical IPF" auf "IPF factor estimation"
(oder gar "ADETON") umgestellt werden soll.
Weiterhin sollten Erkenntnisse
(Fehler, Schwachstellen, Ideen für Verbesserungen)
wie in roadmap 053 gegen Mehraufwand sofort umgesetzt werden.
Beim Lenkungsausschuss am 26.07.2023 10:30 wurde besprochen
- hst empfiehlt die Anzahl der EXCEL-Beispiele für die Bausteine P(1-2), N(1-4) von 10 auf 2 oder 3 zu reduzieren und dafür die EXCEL-Beispiele aus roadmap 053 an die aktuelle SIKURS 10.5 anzupassen und die Ergebnisse der Prognose zu vergleichen.
- wib empfiehlt in Zukunft alle 12-13 EXCEL-Beispiele für die Qualitätssicherung zu nutzen, d.h. bei jedem neuen SIKURS Release zu überprüfen, ob die Berechnungen im Programm mit den Excel-Beispielen übereinstimmen.
Dies kann manuell oder automatisch über eine "non regression test" Prozedur, die die SIKURS-Eingabedateien aus der Excel-Datei extrahiert, die Prognose startet und die Ergebnisdateien (z.B. mit diff) mit der EXCEL-Datei vergleicht.
Bei Abweichungen muss der Ursache untersucht und eine Lösung erarbeitet werden
(siehe auch roadmap 053)
m,h: Der Ableitung der Sterblichkeit aus der amtlichen Statistik für die Gruppen des Altersindex 0 wurde die mittlere Verweildauer dieser demografischen Gruppe im Prognosejahr zu Grunde gelegt und die amtliche Sterberate halbiert. Dabei blieb unberücksichtigt, dass etwa die Hälfte aller Neugeborenen in den ersten 8 Wochen nach der Geburt versterben. Die wöchentliche Sterberate des ersten Lebensjahres ist demnach eine dynamische Größe und nicht für alle Wochen des ersten Lebensjahres gleich. Dieser Sachverhalt wurde bei oben beschriebenen Ableitung der SIKURS Sterberaten aus den Sterbetafeln nicht berücksichtigt. Die Berechnung der Sterberaten aus den Sterbetafel sollte daher korrigiert werden.
wib: Überarbeitung Spezifikation von
Sterbetafel_Deutschland_2014_2016.csv
- Verschiebung Raten der Altergruppen durch Mittelung um ein
halbes Jahr nach oben/unten mit folgenden Problemen
- Mittelung von Raten (Bewegung/Bestand) ist ungenau, wenn Bestand nicht konstant
- Im nichtlinearen Bereich der Kurve (z.B. bei Sterberaten 0..5 fallende Exponentialkurve, siehe "unterste Altersgruppe", 30..99 steigende Exponentialkurve, siehe Gompertz roadmap 01 068 098) ist Mittelung auch bei konstantem Bestand ungenau
- Sonderbehandlung unterste/oberste Altersgruppe, z.B. Sterberaten (siehe auch Hilfe Glätten):
- unterste Altersgruppe
hst: Justierung Faktor auf mehr als 0,5:
Bei der Erörterung dieses Themas muss man wissen, dass in der ersten Woche nach der Geburt etwas mehr als die Hälfte aller im ersten Lebensjahr verstorbenen Säuglinge sterben.
wib: Einfache praktische Lösung:
Option Quote Sterbefälle erstes Halbjahr (q)
(Beispiel BRD 1986/88 m: 0,886, w: 0.866)
mit geeignetem default, z.B. 0.9SIKURS amtliche Sterbetafel Index Bezeichnung ---------+------------------------------ 0 asz(0)*q 1 (asz(0)*(1-q) + asz(1))/2 2 (asz(1)+asz(2))/2 ... 30 (asz(30)+asz(31))*g(i) 98 (asz(97)+asz(98))*g(i) 99 (asz(98)+asz(99 und älter))*g(i) ??? 100 (asz(99 und älter) ??? ... 104 (asz(99 und älter) ???
mit g(i) ein Faktor etwas größer als 0,5, abzuleiten aus der Gompertz - Funktion - oberste Altersgruppe
Erfahrungswert, z.B. (m: 0,4, w: 0,3) oder
uls: die durchschnittliche Sterbewahrscheinlichkeit der 99jährigen (und älteren) so zu berechnen, dass im Höchstalter von X Jahren ein Schwellwert von y% Überlebenden unterschritten wird (als X könnte als Konstante z.B. bei den Frauen 114 und bei den Männern 112, als Schwellwert 0,001 gewählt werden). Dann wäre die durchschnittliche SIKURS-Sterbewahrscheinlichkeit im Alter von 99:
Schwellwert ^ (1/(Höchstalter-99)), also z.B.0,001 ^ (1/16) = 0,649
- unterste Altersgruppe
- Abbildung Quell-Altersbereich amtliche Raten auf anderen
Ziel-Altersbereich SIKUR-Raten
- Sterbefälle von z.B. 0..100 auf z.B. 0..99 oder 0..104
- Geburten:
Eine Änderung des Altersbereichs wird vom Tool nicht unterstützt, da bei der SIKURS-Prognose jeder Altersbereich für Geburten unterstützt wird.
Der Anwender kann manuell eine Reduktion des Altersbereichs z.B. von 13..49 auf 15..44 näherungsweise durch Verteilung der Quell-Altersgruppen 13..14 und 45..49 auf andere Altersgruppen vornehmen, falls diese sehr seht klein sind
- Die Ausgabe der Indices als Formel
(
1..$NTYS;1..$NBG;1..$NGG) erfolgt nur auf Anforderung, Alternativen z.B. für Bevölkerungsgruppen sind1..2, *und1. - Skalierung Lebendgeburten je 1 oder 1000 Frauen
wib: Berechnung
von Sterbetafeln
Ein Vergleich 098-12621-0001.pdf
(098-12621-0001.xls)
SIKURS-Sterberaten mit
amtlichen Sterberaten
zeigt, dass sich die jeweils zugehörige Lebenserwarung von 74,66 bzw. 78,35
deutlich unterscheidet.
Vielleicht gelingt es mit den aus der Sterbewahrscheinlichkeit q(x)
abgeleiteten Werten Überlebende l(x) und Gestorbenen d(x)
plausiblere Werte für die SIKURS-Sterberaten abzuleiten?
Ein oder mehrere Parameter für die Korrektur der Altersgruppe 0
sollten in Startmaske oder einer Eingabdatei stehen, damit die Lösung
allgemein (und nicht spezifisch für bestimmte Jahre und Regionen ist)
Die Sterberate ab 30 steigt
exponentiell an,
d.h. im 2. Halbjahr sterben jeweils mehr Personen als im ersten Halbjahr.
Soll dieser Effekt bei der Verschiebung der Altersgruppe um ein halbes Jahr
berücksichtigt werden ?
Stimmt die Berechnung Lebenserwartung als
"Summe akkumulierte Überlebenswahrscheinlichkeit + 0,5"
im Prognoseprotokoll, Indikatorentool,
und Extras/Eigene scripts/lebenserwartung.pl, oder soll sie dem Verfahren
destatis
wie in Extras/Eigene Scripts/le_destatis.pl angepasst werden ?
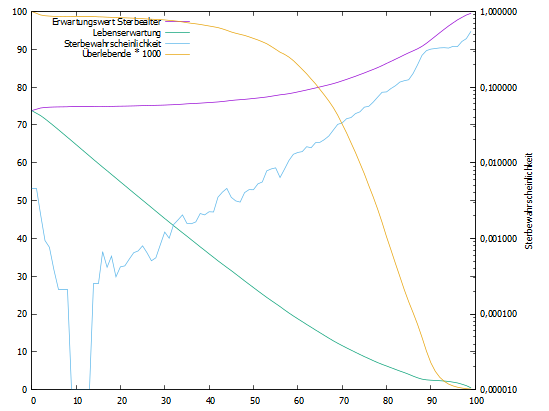
Beispiel Lebenserwartung aus .../beispiel/regtest/strb1992.csv:
# lebenserwartung ; le_destatis 1;1;1;0;73,7886112044886;73,7879572814655 1;1;2;0;79,6156265704044;79,6103178857868 1;2;1;0;81,1099888938062;80,9471352956605 1;2;2;0;89,0462746980029;88,8227386033458Im Prognoseprotokoll wurde die Berechnung der Lebenserwartung auf die destatis-Methode umgestellt. Je nach Protokollumfang enthält diese
- nur die Altersgruppe 0
- alle Altersgruppen
- zusätzlich Zwischenergebnisse
!option($LE 1)kann auch die einfache Berechnungsmethode angesteurt werden (siehe Einwohner/Prognose/Berechnen/?/Notiz/Optionen/LE)
Mit SIKURS-Hauptmaske/Extras/Eigene Scripts/Start/gompertz.pl
kann man den Gompertz-Koeffizienten und die
MRDT (mortality rate doubling time) berechnen und mit
dem logarithmischen Gompertz-Diagramm die Plausibilität der Sterberaten
insgesamt überprüfen.
siehe roadmap 013, 068
siehe auch GREVILLE-Methode, REED-Merell-Mehode in "Vogel, Grünwald: Kleines Lexikon der Bevölkerungs- und Sozialstatistik"
uls: Ich habe mir das jetzt genauer angesehen, insbesondere weil ich in das Handbuch auch einen Abschnitt zur Thematik aufgenommen habe.
Angehängt habe ich Original-Sterberaten der Perioden-Sterbetafel aus den Jahren 2014 bis 2016 (098_sterbetafel_sterberaten.csv). Laut Statistischen Bundesamt betrug damals die Lebenserwartung bei Geburt bei den Männern 78,18 Jahre und 83,06 Jahre bei den Frauen.
Die von SIKURS mithilfe des Tools generierten interpolierten Sterberaten und mit den korrigierten Sterberaten für die Altersgruppen 0, 1 und 99 habe ich als 098_strb2016_roh.xlsx angehängt. Ich komme bei den interpolierten Daten auf Lebenserwartungen von 78,15 / 83,00 und bei
den korrigierten auf 78,16 / 83,00. Die Formel in den Zellen J5 und Q5, bzw.J105 und Q105 sollten Sie sich kurz ansehen. Die Berechnung der durchschnittlich
Zahl durchlebter Jahre weicht in der Altersgruppe 0 (0 bis 0,5jährige) von den Berechnungen in den anderen Altersgruppen ab.
Ich würde bei meinen Prognosen die von SIKURS generierten Sterberaten korrigieren, weil die Sterberaten der Altersgruppe 0 durch die Interpolationen zu niedrig
und der der Altersgruppe 1 zu hoch geschätzt würde. In der Altersgruppe der 99jährigen würde ich eine Rate verwenden, die dafür sorgt, dass ein natürliches
Höchstalter (116 Jahre) von praktisch niemand überschritten wird. An der Lebenserwartung ändert sich dadurch kaum etwas, die Raten werden nur hinsichtlich der
Säuglingssterblichkeit etwas plausibler und ein mit jedem Prognosejahr wachsender Überbau (in der Altersgruppe 99) in der Bevölkerungspyramide vermieden.
Insgesamt kann ich den starken Rückgang der Lebenserwartung durch die Anwendung des SIKURS-Tools bei meinen Daten nicht beobachten.
Bei der Quotenberechnung legt der Anwender zwei Altersindices fest
[35 ] Untere Altesgrenze (jung) [65 ] Obere Altersgrenze (alt)Mit diesen Werten gibt es in der Haushalteprognose bei den verschiedenen Indikatoren folgende Altersgruppen mit den Altersgrenzen:
| fein | 0 35 65 1000 |
| grob_jung | 0 35 1000 |
| grob_alt | 0 65 1000 |
- eine neue feinere Definiton obiger Tabelle
- die Auswahl von 2 oder 3 Tabellen für den Anwender
- die Möglichkeit für den Anwender die Altersgruppen obiger Tabelle selbst beliebig zu verfeinern
- Umbenennen Eingabedateien
ECK(GEB,GEBG,GEM,REG,STRB,STRBG,TYP)in PrefixZIELstattECK, da Zielwert als Begriff beser passt als Eckwert.
Ersetze bei Zielwerdateien .GEB, .GEBG, .REG, .STRB, .STRBG Zielwert durch Unter- und Obergrenze, um z.B. bei Baustein M2 für einzelne demografische Gruppen einen Zielwert (Unter- = Obergrenze), für andere ein Zielwertintervall (Unter- < Obergrenze) oder freie Entwicklung (kein Eintrag, d.h. Untergrenze = 0, Obergrenze = ∞) vorgeben zu können. - Bausteinabhängige Dateinamen
Einige Bausteine sind in ihrer Struktur/Differenzierung abhängig vom verwendeten Baustein. Wenn man einfach Eingabedateien für mehreren Bausteinausprägungen im Eingabeverzeichnis halten möchte, könnte man folgende Dateienamen anpassendsg2020_R1-2 eckreg_M1-2 saldvol_N1-4 wegvol_C1-4 zuaq2020_k1-4 zudq2020_K1-4 zuvol_K1_4
Bisher muss man sich mit Befehlen vor/nach der Prognose behelfen:shortcut qw(zuvol_K2 zuvol); shortcut qw(zuaq2020_K2 zuaq2020); shortcut qw(zudq2020_K2 zudw2020); ... remove qw(zuvol zuaq2020 zudq2020);
- Bausteine C, M, N erweitern
Wenn für eine vorgesehene Differenzierung kein Zielwert vorgegeben wird, dann sollte für diese Teilmenge (anlaog zu Baustein G und S) keine Anpassung vorgenommen werden.
Alternativ könnte man für die Zielwertdateieneckgeb, eckgebg, eckreg, eckstrb, eckstrbgstatt eines eventuell fehlenden Zielwertes Unter- und Obergrenzen wie bei den Dateieneckgem, ecktypeinführen. - Baustein V entfernen
Bei Baustein D und E werden immer Gewichte für die Wanderungen eingelesen.
Wünscht man keine Gewichtung gibt man z.B. alle Gewichte 1 vor:nebgqt.csv # Neubauerstbezug mit Gewichten Quellen Binnentypen #Jahr;tynee;tyb;Gewicht *;*;*;1
Wenn man den Baustein V entfernt, dann wird man immer die Datei
attr2020.csv, umbenannt inbwgqg.csveinlesen.bwgqg.csv # Binnenwanderung mit Gewichtung der Quellgebiete #Jahr;gkz;Gewicht *;*;1
- Bausteinkombination E1V1 prüfen:
Bei Bausteinkombination E1I1T1V1 muss noch geprüft werden, ob die Gewichte ATTR0000.csv und REAGZT.csv zusammenpassen (hst vermutet ja):
DG4IBR Binneneinzug aus Rückbauendauszug wird erst mit REAGZT gewichtet und anschließend mit der mit ATTR0000 gewichteten freien Wohnkapazität auf die Gebiete verteilt - siehe Laufprotokoll:attr2020.csv -> GG1ATTR -> FWKG -----------> DR4IBR reagzt.csv -> GR2IBR -> DR5IB -> DR3IBR -/ DR5IB = DR4IB * BR30C * GR2IBR FWKG *= GG1ATTR DR3IBR = DR5IB * DR4OBR_REA DG4IBR = DR3IBR * FWKG/FWKT
- Baustein T entfernen
wünscht man keinen Außenwegzug, kann man folgendes vorgebenwegz2020.csv # leer, kein Außenwegzug
(siehe 062); - 32-bit Version auslaufen lassen
SIKURS 5.4.1035 mit gnuplot 5.2.7 32-bit als letzte 32-bit Version einfrieren
SIKURS 5.5 nur noch als 64-bit Version (mit gnuplot 5.2.8 64-bit) erstellen. - Visualisierung/Indikatoren
Erweiterung Berechnung Lebenserwartung auf destatis Verfahren (siehe roadmap 098) - Berechnen/Cluster-Analyse Reiter GEM
Funktion Clustervektor aus GEM-Datei ableiten könnte gestrichen werden, weil man dies leicht z.B. durch Ergebnis/Zeitreihe erledigen kann - Nachfolge Pflege Handbuch Haushalteprognose, z.B.:
Siehe Hauptmaske/Haushalte/Quoten/Berechnen/HHProg-Verzeichnis/?
Kurzfassung und Anmerkungen - folgende in der Haushalteprognose verwendeten Variablen können
den Wert "blank", das heißt, Feld ist nicht versorgt haben:
HPAAR, HELT, KERNS, HVOR, HNACH, HHNR
Derzeit wird nur KERNS geprüft und falls blank wird mit "Haushaltegenerierung noch nicht durchgeführt" abgebrochen.
A01 - Merkmalsableitung nicht möglich
A03, A06 - Merkmalsableitung noch nicht durchgeführt
A07 - Merkmalsableitung noch nicht durchgefühft oder Person gehört nicht zu Bevölkerung in Haushalten
Hier werden blank-Felder als 0 gewertet.
Sollen die Felder auf "blank" geprüft werden, wenn ja, was ist jeweils zu tun ?- Abbruch mit Warnung bei ersten Auftreten
- Warnung im Protokoll bei jedem Auftreten
- Fälle zählen und am Ende Statistik: unversorgte Felder HAPAAR 3, HELP 0, KERNS 543, ...
- gnuplot ab 6.0 webp statt png, gif verwenden und Alternativen prüfen:
- bokeh
- Shiny
- Plotly JavaScript Open Source Graphing Library mit Julia, R, Python, Mojo
- Google Charts die Beispiele "Extras/Eigene Scripts/Start
- bubble_chart.pl Blasendiagramm
- treemap.pl treemap_csv.pl Kacheldiagramm
- Steuerung Ausgabe Binnenwegzugsmatrix verbessern
Einwohner/Prognose/Berechnen/AusgabeAusgabe [vn] Differenzierung Binnenwegzugsmatrix
mit folgenden sinnvollen Spaltennummern aus reftyp
Die Ausgabedatei enthält die Differnzierung im Dateinamen, z.B.vn Wirkung 0 keine Ausgabe Binnenwanderungsmatrix 1 nur Ausgabe unsortierte Rohdatei gstrom.csv0101 von Gebiet nach Gebiet (evtl. sehr groß) 0105 von Gebiet nach TYB 0501 von TYB nach Gebiet 0505 von TYB nach TYB -0505 von TYB nach TYB (ohne Aufbau von gstrom.csv)1313 von räumlichen Aggregat 1 nach räumlichen Aggregat 1 1305 von räumlichen Aggregat 1 nach TYB -1414 von räumlichen Aggregat 2 nach 2 und löscht gstrom.csv gstrom01_01.csv
Bis auf0505wird die unsortierte Dateigstrom.csvohne Spaltenüberschriften in Differenzierung "Jahr, Quellgebiet, Zielgebiet, BG, GG, AG, Anzahl" ausgegeben und anschießend in die gewünschte Differenzierung aggregiert. Ein negatives Vorzeichen bewirkt die anschließende Löschung vongstrom.csv. Behält man die Dateigstrom.csv, kann man daraus weitere Dateien in gewünschter Differenzierung berechnen, z.B. durch Befehle nach der Prognose:# aggregiere gstrom auf räumliches Aggregat ohne demografische Differenzierung zeitreihe 'gstrom', 'gstrom13_13', ['$i', 'reftyp 1 13', 'reftyp 1 13', 1, 1, 1], { subset => 0 }; # Ausgabe Wanderungsmatrix als "heatmap" matrix(fn => 'gstrom13_13', shape => 4, size => 1000); # zeige heatmap im Browser (evtl. Umstellung gif nach webp) start('gstrom13_13.gif'); - Wenn man die Binnenwegzugsmatrix als
floatstattdoublespeichert, könnte man mit erhöhter Anzahl Binnentypen rechnen.
Eine Änderung der Reihenfolge#TYV;TYN;BG;GG;AG;Rate in #BG;GG:AG:TYV;TYN;Rate
könnte Vorteile bringen. - ini-Dateien im TOML (oder YAML, JSON) Format speichern
mit folgenden Vorteilen:
- Routinen für viele Programmiersprchen verfügbar
- bessere Unterstützung mehrzeiliger Texte (z.B. Notiz)
- Unterstützung von Arrays und Tables
- Vorschlag blh:
wählt man bei der Quotenberechnung:
[3 ] Abbildung R02...
so braucht man eine reftyp.csv mit einer Abbildung einer 3-Stelligen Gebitesnummer in Typen.
Bei der Prognose muss dann die Datei gem.csv diese gleichen 3-stelligen Gebietsnummern haben.Wunsch: Bei der Prognose optional eine gem.csv verwenden mit einer Differenzierung nach den Typen aus reftyp.csv.
Dazu müsste die Quotenberechnung die Differenzierung der Werte GT2, SPKV, SH2i in der Transferdatei q.csv von Gebietskennzeichen auf Gebietstyp aggregieren. - Alternativer Vorschlag wib:
Bei der Ableitung der gem-Datei aus dem Statistikdatensatz im Schritt- Ableitung Makrodateien aus dem Statistikdatensatz oder
- Ableitung Raten/Quoten aus Makrodateien
[3 ] Abbildung R02/R02U2/ANSTE/ANSTI [ ] räumliche Aggregation
den Schlüssel für die Aggregation von dstbest vor.
Das Programm sollte eine zuätzliche Datei ausgebenrefra.csv: # Referenzdatei räumliches Aggregat Gebiet;Räumliches Aggregat 012;1 ... 097;1
Der Anwender kann diese Datei editieren und räumliche Aggregate definierenrefra.csv: # referenzdatei räumlichen Aggregat Gebiet;Räumliches Aggregat 012;11 ... 097;23
Bei einem wiederholten Lauf kann er dann vorgeben[3 ] Abbildung R02/R02U2/ANSTE/ANSTI [v] räumliche Aggregation
Dann wird aus dstbest gem und reftyp mit den Gebietskennzeichen 11-23 abgeleitet.
In reftyp kann man dann in Spalte hhprog die Abbildung der Schlüssel 11-23 auf Haushaltetypen z.B. 1-5 festlegen.Die Haushalte-Quotenberechnung müsste dann ebenfalls die zweistufige Aggregation von dstbest unterstützen
- Option Ausgabe Datensätze mit Wert 0
Bei dünn besetzter Eingabedatei gem.csv enthält die Ausgabedatei person.csv sehr viele Sätze mit Wert 0.
Soll das Programm auf die Ausgabe dieser Null-Sätze immer oder optional
[v] Ausgabe Nullsätze in person.csv, haushalt.csv, kinder.csv
verzichten ?
Mit Extras/Eigene Scripts/Start/dzr.pl kann man nachträglich Null-Sätze aus person.csv entfernen.
- Benutzerhandbuch Haushalteprognose 10.3
siehe Haushalte/Prognose/Berechnen/Auswahl Verzeichnis/?
Kurzfassung und Anmerkungen - Diagramm SIKURS-Prognosekonzept Handbuch Seite 8
Gewichte für Neubau und Rückbau - Stein-Handbuch 10.4
- Anpassung SIKURS-EXCEL-Beispiele an 10.5 (Gewichte Neu-/Rückbau) und Vergleich Prognoseergebnisse EXCEL mit Programm
Für die zukünftige Weitereinwicklung von SIKURS (siehe auch 021 022 025 032 106 111) müssen folgende Fragen geklärt werden:
- Soll SIKURS ein Programm Bevölkerungs-, Haushalte-Prognose und
vielen Zusatztools bleiben,
oder soll es einen Wizard,
oder soll es in eine Statistik-Software
integriert werden (z.B. R, Python, Mojo, Julia) ?
Eine einfache Integration mit R existiert bereits, man kann aus R SIKURS Prognosen und diverse Tools starten und SIKURS kann R-Prozeduren starten (siehe Handbuch - externe Programme). - soll SIKURS außer unter Windows (10/11/365) auf weiteren Plattformen (z.B. Linux (z.B. raspi), MacOS) lauffähig sein ?
- sollen weiterhin csv-Dateien verarbeitet werden, oder soll eine
Datenbank oder hdf5
eingesetzt werden ?
Die Zugriffe lesen und schreiben auf die csv-Dateien sind in C++ (Modul fn) und Perl (Modul CSV) stark gekapselt.
Eine Umstellung auf eine Datenbank müsste mit begrenztem Aufwand möglich sein. (siehe 021) - Sollen für globale Parameter
sikurs.iniund Projektparameter.../bprog/v3.iniweiterhin "Windows-style-ini-Dateien" verwendet werden, oder auf Windows-Registry bzw. JSON, XML, YAML, ... umgestellt, oder in eine Datenbank integriert werden? - Sollen die Protokolle als Verzeichnis mit vielen html-Dateien erhalten bleiben, oder soll auf andere Konzepte, z.B. Datenbank, markdown, ..., gewechselt werden ?
- Welche client server Technologien sollen unterstützt werden (z.B. Apache Web-Server, Citrix Applikations- und Terminalserver) ?
{kind=link}
- Umstellung von Perl und C++ auf C# mit Datenbank
- Tiobe: C++ ist Programmiersprache des Jahres 2022
- F# wäre zur Prüfung der Algorithmen besser
- der Aufwand ist groß, man muss schrittweise vorgehen und mit einem mvp (minimum viable product) beginnen.
- für die Umstellung gibt unterschiedliche Strategien
- analytisch:
Erstellung einer Spezifikation durch- Reverse Engineering
- Perl/C++-Programmquellen
- Handbücher und Hilfeseiten
- über 100 Beispielprognosen verschiedener Bausteinkombinationen, der Eingabedateien, Prognoseprotokolle (Protkollumfang 3), und Ausgabedateien
.../sikurs/html/de/00Hilfe/testprozeduren.htmfür alle Tools- Excel-Beispiele von Herrn Dr. Tüllmann
- Mitarbeit der jeweiligen Experten
- Utz Lindemann oder Nachfolger: Statistikdatensatz
- Dr. Hannes Tüllmann: Bevölkerungsprognose
- Friedrich von Klitzing († 2021), Barbara Lux-Henseler: Haushalteprognose
- GUI-Prototyp mit batch-Aufruf altes Programm
Schreiben einer neuen GUI in C# mit dem kompletten Programmumfang
Starten der Funktionen aus der GUI durch:- Export der benötigten Daten aus der Datenbank als csv-Dateien
- Aufruf des alten Programm im batch modus
siehe Hauptmaske/Prognose/Berechnen/?/Befehle z.B. grnvzgr, hhprog, inndikator, pyramid, report, smooth, srnvle, subsystem, thematicMap, xyplot, zeitreihe.
Fehlende Befehle müssten bei Bedarf nachgerüstet werden- SIKURS Eingabedateien aus Makrodateien (TkRate::runCalc)
- Geburtenraten Hadwiger (TkHadwiger::runVisu/runPar/runFruc)
- Geburten/Sterberaten aus amtlichen Raten (TkRate::runFruc/runStrb)
- Clusteranalyse (TkRate::runClu)
- Glätten über Alter und Jahr (TkSmooth::processFile2d)
- Glätten Rohdaten im Prognoseverzeichnis (smoothraw::run)
- Visualisierung Histogramm, Kacheldiagramm
- Import der csv-Ausgabedateien in die Datenbank
- Reverse Engineering
- incrementell:
Entwurf einer gewünschten Zielarchitektur (Module, Namespaces, Klassen und roadmap 032 Modernisierung, 111 Strukturpflege)
Optional refactoring Ausgangs Perl/C++ Quellen in Richung Zielarchitektur
möglichst automatische Umstellung Perl/C++ nach C#
mehrere refactoring-Schritte in die Zielarchitektur - radikal:
man entwirft eine optimale Architektur für die Zielspache und programmiert incrementell alle Funktionen neu und testet das neue Produkt gegen das alte mit folgendem Problem:
Man muss die Logik einzelner Module genau verstanden haben, z.B.- sikern (kleinraümige Bevölkerungsprognose):
das Zusammenspiel der 17 Prognosebausteine ist komplex und wird nicht identisch in der SIKURS-Excel-Dokumentation von Herrn Dr. Tüllmann abgebildet.
Der iterative Abgleich der Binnenwanderungsmatrix dauert in C# 4 mal, mit optimizer 2 mal so lange als in C++ (.../SUL/Matrix/bench.cs). - hhprog (Haushalteprognose)
Die Spezifikation von Herrn vor Klitzing wurde 2014 von Herrn Hahn und Frau Lux-Henseler um eine Behandlung gleichgeschlechtlicher Partnerschaften erweitert. Beide haben sich sehr tief in das Modell eingearbeitet und konnten mit SPSS viele Plausibilitätschecks mit dem Statistikdatensatz Bestand durchführen. Eine Einarbeitung einer neuen Person könnte aufwändig sein. - dstmak (Berechne Makrodateien aus Statistikdatensatz)
Logik muss entweder aus C++-Programm reverse engineered werden oder mit Statistikdatensatzexperten neu erarbeitet werden -
auf eine Portierung folgender Module kann evtl. verzichtet werden
- adeton: Abgleich Matrix mit ADTEON Table Ranking Procedure
- shp2plt: Thematische Karte
- sikern (kleinraümige Bevölkerungsprognose):
- analytisch:
- Nutze C++ mit
WinUI3
oder Qt QML
statt Perl, dann müsste man schrittweise vorgehen∴
- Erstelle eine Rumpf-Benutzeroberfläche, die nur eine Versionsdatei auswählen kann, eine Pronose starten und das Protokoll anzeigen.
- wenn das Ergebnis befriedigend ist, kann man beginnen die restlichen Funktionen zu programmieren (Methodenauswahl, Haushalteprognose, Eingabedaten berechnen, glätten, dynamisieren, Visualisierung Zeitreihen, Pyramiden, Indikatoren, Ergebnis Zeitreihe, bearbeiten, anzeigen; auf Extras/Eigene Scripts muss man entweder verzichten oder auf einen anderen Interpreter als Perl, z.B. Python, R, Lua, Chaiscript, Angelscript, v8pp wechseln)
- Nutze Jupyter mit R (Julia, Python, Mojo),
dann würde man ähnlich schrittweise vorgehen und gewänne zusätzlich
- Dokumentation der Prognose mit allen Einzelschritten der Vor- und Nachbereitung der Daten
- Ein Hilfsmittel für Schulungsunterlagen ähnlich dem anwenderorientierten Handbuch
- eine komplette Vorlage für eine Wiederholungsprognose mit neuen Eingabedaten und Ideen zur Verbesserung einzelner Prognoseschritte
- Makrodateien aus Statistikdatensatz
- SIKURS Eingabedatien aus Makrodateien
- Glätten
- Bevölkerungsprognose
- Indikatoren
- Reporting
- Haushalteprognose
- ... bei Bedarf weitere Tools
Auch eine Datenbankanbindung (Export/Import von csv-Dateien) wäre damit machbar.
In einem zweiten Schritt könnte man jede gewünschte SIKURS-Funktion mit Rcpp in R integrieren (siehe roadmap 106.3) mögliche Risiken sind höherer- Installationsaufwand
- Schulungsbedarf
folgende Probleme wurden angesprochen
- wenn man mit Excel SIKURS-csv-Dateien einliest, dann werden manche
Felder als Datum interpretiert.
work around: csv in txt umbenennen und in Excel importieren
wib: bitte Beipiel - Tools merken sich das Eingabeverzeichnis nicht, man muss sich
jedesmal durch den Verzeichnisbaum klicken.
Schapper: wenn man mit Einwohner/Versionsdatei/öffnen eine ini-Datei in der Nähe der gewünschten Dateien öffnet, dann funktioniert das.
wib: bitte Beispiel für Tools mit diesem Problem, z.B. "Eingabedaten/Glätten/Glätten über das Alter" merkt sich das Verzeichnis der letzten Glättung solange die Hauptmaske aktiv.
Mögliche Lösung:
Man könnte die Dateiauswahlmaske so konfigurieren, dass sie immer im Verzeichnis steht in dem beim letzen Aufruf der Dateiauswahlmaske eine Datei ausgewählt wurde, d.h. das Startverzeichnis der Dateiauswahlmaske würde vom Verzeichnis der aktiven ini-Datei entkoppelt.
Testweise wurde dieses Verhalten in Ergebnis/Bearbeiten/Datei eingebaut.
KOSIS-DST_Bestand_2021-02.pdf erweitert den Statistikdatensatz Bestand von 321 auf 350 Stellen.
Wer kann überprüfen, ob davon die Haushalteprognose oder die Ableitung Makrodateien betroffen ist ?
- laufen obige Programme mit dem neuen Statistikdatensatz?
- sollen die neuen Felder mit Merkmalen zum Zuwanderungshintergrund RQZU2, M01 Zuwanderungshintgergrund der Person, M02 Zuwanderungshintergrund (HHSTAT zertifiziert), M03, M04, M05, A07X, A05M - Migrationshintergrund im Haushalt, P02MR, P08MR, FIL337, Z01BIS, DS350) ausgewertet werden, um beispielsweise Bevölkerungsgruppe auf 4 Gruppen (nicht deutsch, deutsch - Einbürgerung, Deutsch Aussiedler, Deutsch sonstiger Nachweis) auf 4 Gruppen zu erweitern ?
Wenn man eine lange laufende Prognose gestartet hat, will man sie manchmal vorzeitig abbrechen, z.B. weil Zwischenergebnisse unsinnig erscheinen.
Dies gilt für die Funktionen im Tocherprozess sikern64.exe:
- sikern: Bevölkerungsprognose
- hhprog: Haushalte-Quotenberechnung/Prognose
- keine Programmänderung, nutze Programm
Taskmgr.exevon Windows
- Tastenkombination
<Strg><Alt><Entf>drücken
Task Manager
Zeile mitsikurs64.exemit rechter Maustaste anklicken
Task beenden - Tastenkombiantion
<Strng><Shift><Esc>drücken und obiger Task Manager erscheint sofort - Extras/Eigene Scripts/Start/SIKURS_stop.pl
erstellt ein Icon
 am Desktop.
am Desktop.
Wenn sie dieses Icon während eine Bevölkerungs/Haushalte-Prognose anklicken, so wird diese abgebrochen. Das Icon automatisiert die obigen Windows-Funktionen.
- Tastenkombination
- Erweiterung GUI um "Thread und Queue"
Bei SIKURS 10.5.0.1417 konnte der Tochterprozesssikern64.exeabgebrochen werden, wenn man diese Erweiterung aktivierte:
Rechte Maustaste SIKURS Icon/Eigenschaften
Ziel: [....\sikurs64.exe -t1 ]
(-t1bedeutet: verwende eigenen Perl-Thread fürsikern64.exemit Queue zur GUI)
Mit Hauptmaske- Datei/Beenden oder
- Kreuz rechts oben
Wenn ja, wird er abgebrochen und es erscheint eine Messagebox mit Erfolgsmeldung.
Anschließend wird die Hauptmaske beendet.
Wenn diese neue Funktion gefällt, kann die Option-t1zur Voreinstellung gemacht werden.
Mit
global_dst.pl kann man sich einen Überblick über ein Verzeichnis mit
Statistikdatensätzen verschaffen, hier anonymisierte Testdaten:
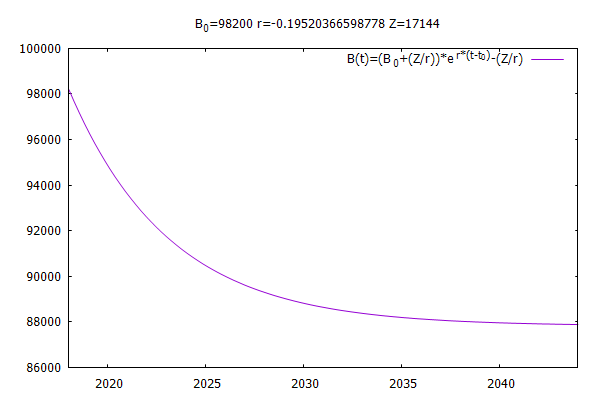
Start Eigene Scripts global_dst.pl C:/trunk/sikurs/extra/Beispiel/DST/350/dst: < dstbest2017.txt 100000 Sätze zu 350 Byte < dstbest2018.txt 100000 Sätze zu 350 Byte < dstbew2018.txt 100000 Sätze zu 371 Byte < dstbew2019.txt 100000 Sätze zu 371 Byte > C:/trunk/sikurs/extra/Beispiel/DST/350/dst/global_dst.csv Ergebnis für Jahr 2018: Bestand 98175, (Binnen-weg=zu-zug 17501), Geburt 2488, Sterbefall 2763, Außenwegzug 18097, Außenzuzug absolut 17565, Geburtenziffer 25,3425, Sterbeziffer 28,1436, Außenwegzugsziffer 184,334, Endbestand 97368 Ergebnis für Jahr 2019: Bestand 98200, (Binnen-weg=zu-zug 17677), Geburt 2276, Sterbefall 2723, Außenwegzug 18722, Außenzuzug absolut 17144, Geburtenziffer 23,1772, Sterbeziffer 27,7291, Außenwegzugsziffer 190,652, Endbestand 96175 Variable: Min Max Mean Stddev Bestand: 98175 98200 98187,50 17,68 Geburt: 2276 2488 2382,00 149,91 Sterbefall: 2723 2763 2743,00 28,28 Wegzug: 18097 18722 18409,50 441,94 Zuzug: 17144 17565 17354,50 297,69 1000 * Bewegung über alle Jahre / Bestand über alle Jahre Geburtenziffer 24,2597 = 1000 * 4764 / 196375 Sterbeziffer 27,9363 = 1000 * 5486 / 196375 Wegzugsziffer 187,4933 = 1000 * 36819 / 196375 Ende Eigene Scripts 6,793 sFür den Bestand (=Hauptwohnsitzler) müsste gelten
Bestand 2019 = Bestand 2018 + Geburten - Sterbefälle - Außenwegzug + Außenzuzug 98724 = 98175 + 2488 - 2763 - 18097 + 17565weil die Bilanz der Binnenwanderung 0 ist.
Dies stimmt im obigen Testdatensatz nicht, weil dieser bei 100000 Sätzen abgeschnitten wurde.
Wenn Sie Statisikdatensätze für mehrere (z.B. 5 oder 10) Jahre verwenden, können Sie mithilfe
der Ausgabedatei global_dst.csv z.B. mit
Eingabdaten/Dynamisieren/...Regression untersuchen,
ob die Geburten-, Sterbe-, Wegzugs-Raten konstant (mit zufälligen Schwankungen)
sind, oder eine steigende oder fallende Tendenz aufweisen
und Sie können überlegen,
ob Sie für die Prognose die Raten dynamisieren wollen:
| #Jahr | Geburt | Sterbefall | Wegzug | Zuzug | Binen-weg=zu-zug | Bestand | Geburtenziffer | Sterbeziffer | Wegzugsziffer | Endbestand |
|---|---|---|---|---|---|---|---|---|---|---|
| 2018 | 2488 | 2763 | 18097 | 17565 | 17501 | 98175 | 25,3425006366183 | 28,1436210847976 | 184,334097275274 | 97368 |
| 2019 | 2276 | 2723 | 18722 | 17144 | 17677 | 98200 | 23,1771894093686 | 27,7291242362525 | 190,651731160896 | 96175 |
global_makro.pl
einen Überblick über die Makrodateien verschaffen,
diese mit dem Ergebnis von obigem global_dst.pl vergleichen
und damit die Plausibilität der Ableitung der Makrodateien prüfen.
Start Eigene Scripts global_makro.pl C:/trunk/sikurs/extra/Beispiel/DST/350/makro < aussenwegzug_2018.csv < aussenwegzug_2019.csv < aussenzuzug_2018.csv < aussenzuzug_2019.csv < baby_2018.csv < baby_2019.csv < bestand_2017.csv < bestand_2018.csv < sterb_2018.csv < sterb_2019.csv Parameter für Jahr 2018: Bestand: 98175 Geburt 2488, Geburtenziffer 25,3425 Sterbefall 2763, Sterbefallziffer 28,1436 Außenwegzug 2763, Außenwegzugsziffer 28,1436 Außenzuzug: 17565 Parameter für Jahr 2019: Bestand: 98200 Geburt 2276, Geburtenziffer 23,1772 Sterbefall 2723, Sterbefallziffer 27,7291 Außenwegzug 2723, Außenwegzugsziffer 27,7291 Außenzuzug: 17144 Ende Eigene Scripts 64,868 sMit dem Ergebnis von wahlweise global_dst.pl oder global_makro.pl kann man mit global_prognose.pl eine Globalprognose auf Basis einer gewöhnlichen Differtialgleichung von Bestand, Änderungsrate (Geburt - Sterb - Außenwegzug) und Außenzuzug absolut starten.
mit den Bewgungsdaten in
global.prognose.csv
Nach der Umwandlung der Statisikdatensätze in Makrodateien und schließlich in SIKURS-Eingabedateien kann man eine differenzierte kleinräumige SIKURS-Prognose durchführen und aus globale Werte hochaggregieren
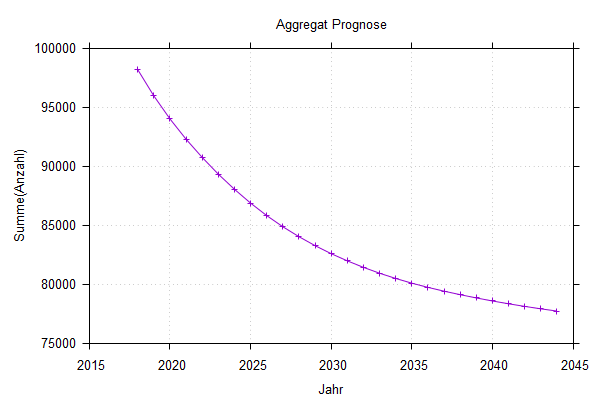
Die Kurve der Differtialgleichung ist viel flacher, weil
diese das Gefälle nicht erst nach einem ganzen Jahr, sondern
kontinuierlich mit dem fallenden Besand reduziert.
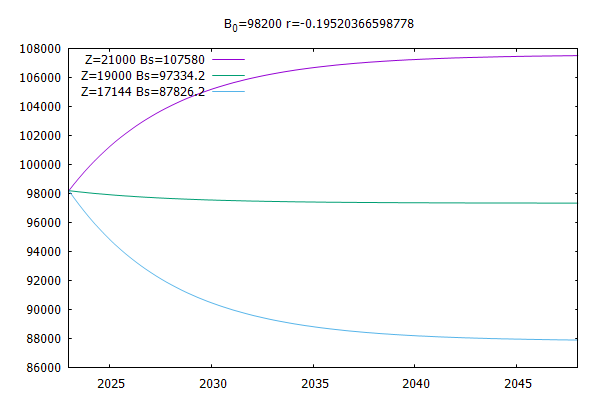
mit global_prognose.pl können Sie mehrere
absolute Außenzuzugsvariaten vorgeben und sich die
zugehörige stabile Endbevölkerung ausgeben lassen:
Erweiterung um räumliche Gliederung (Teilmenge R02)
mit zusätzlicher Berücksichtigung Binnenwanderung.
dst_prognose dst-Verzeichnis 3 2040 global_dst_R02.pl
- liest alle dst-Dateien im dst-Verzeichnis
- Wertet die esten 3 Stellen R02 als Gebiet aus
- aggregiert die passenden Bestands- und Bewegungsdaten
- Rechnet Prognose bis 2040
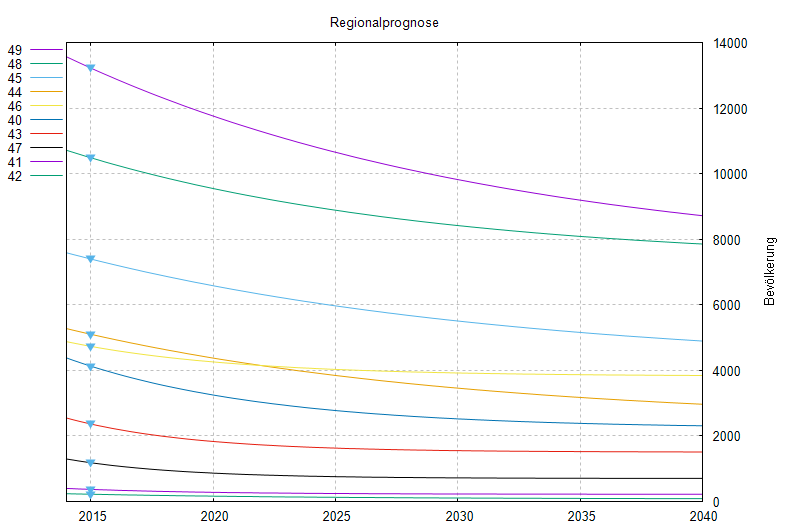
Dazu werden aus dem Statiskdatensatz zwei csv-Dateien
regional.csv: Jahr;Gebiet;Bestand;Geburt;Sterbefall;Außenwegzug;Außenzuzug binnenwanderung.csv: Jahr;Quellgebiet;Zielgebiet;Binnenwanderungabgeleitet und damit eine Prognose grob, d.h. ohne demografische Differenzierung, dafür räumlich fein, d.h. ohne Aggregation der Gebiete in Typen (Geburten-, Sterbe-, -(Außen/Binnen)-Wegzugs-Rate) gerechnet:
- jährliche Fortschreibung wie in SIKURS nur anders differnziert, oder
- numerische Lösung partielle Differtialgleichung (noch nicht realisiert)
- analytische Lösung partielle Differtialgleichung (könnte schwierig werden)
Prognose Bestand:
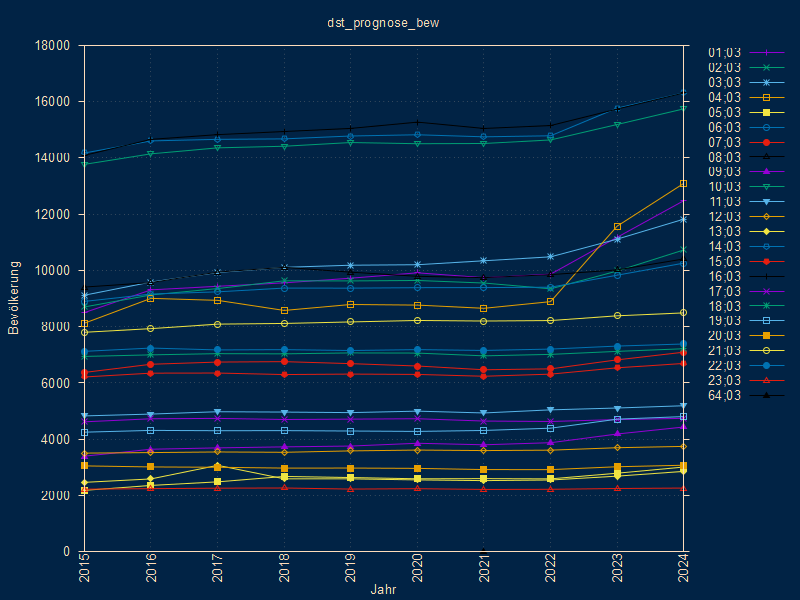
Prognose Binnenwanderung:
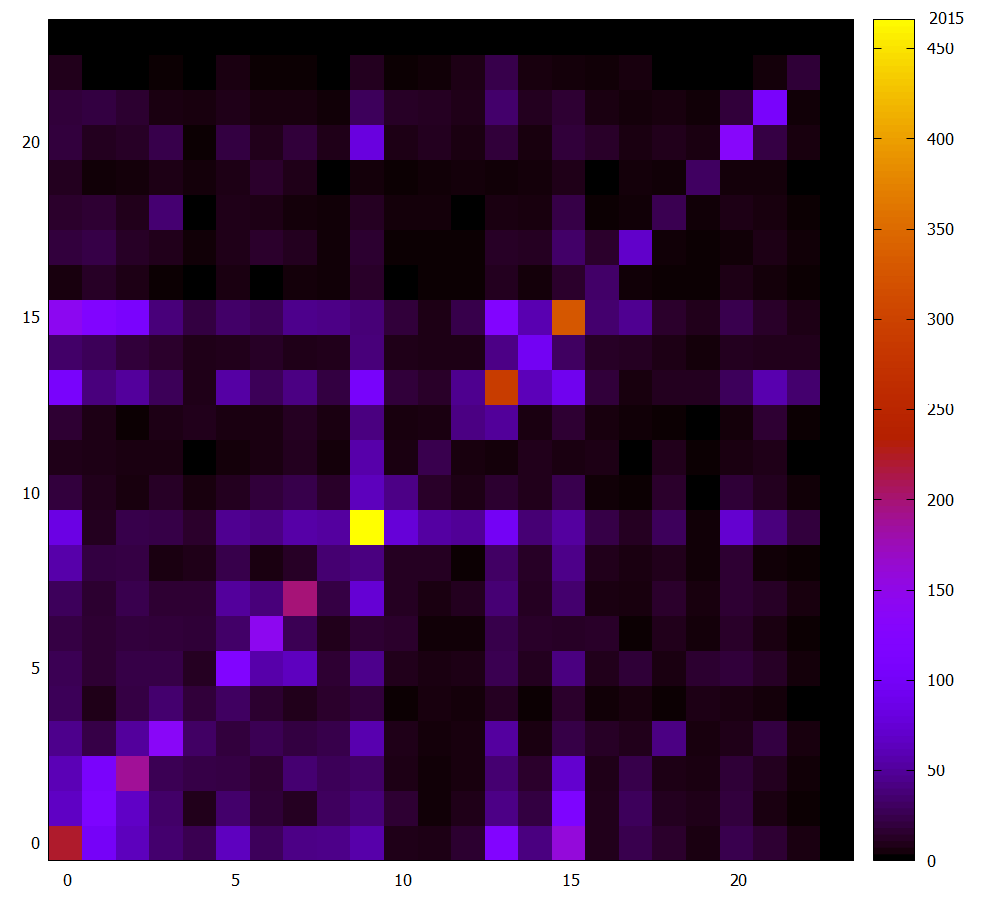
Bei Bedarf könnte man eine weitere Differenzierung nach der erweiterten Bevölkerungsgruppe (roadmap 120) hinzunehmen, um die Außenwanderung differenzierter zu betrachten.
siehe auch roadmap 043
Die Nutzung des Statistikdatensatzes erlaubt eine große Spannweite für die Differenzierung der Eingabedaten
- Gesamtgebietsprognose
- Aufteilung in Gebiete mit mehreren 1000 Einwohnern, die zu "ordentlichen" Bevölkerungspyramiden führen, sowie die Typisierung zu noch größeren Einheiten für die Geburten-, Sterbe-, ..., raten.
- Aufteilung in sehr kleine Gebiete (z.B. Häuserblöcke), Prognose mit Raten aus größeren Typen, und anschließende Aggregation der "fast leeren Pyramiden" zu "ordentlichen" Aussageeinheiten.
Sinnvoll wäre eine Beschreibung einer Beispielprognose durch einen Methodenexperten mit Hinweisen zu den einzelnen Schritten:
- für wie viele Jahre vor Prognosebeginn soll man Statistikdatensätze beschaffen ?
- welche Parameter sind bei der Ableitung der Makrodaten möglich und sinnvoll, insbesondere soll hier bereits, oder erst im nächsten Schritt eine Typsierung erfolgen ?
- Analyse der Makrodaten und mögliche Nachbereitung
- Ableitung der SIKURS-Raten aus den Makrodaten
- Typisierung für genügend Bestand und Bewegungen
- Einsatz Clusteranalyse
- Zusammenfassung kleiner Gebiete für z.B. Sterberaten
- Reduktion demografische Differenzierung (z.B. keine Geschlechtsgruppen, nur 3 oder 5 Altersgruppen) für z.B. Binnenwanderung
- Suche räumlicher Aggregate für Aggregation "zappeliger" Pyramiden nach der Prognose
- Nachbereitung der Raten mit Fragen z.B. was tun bei
- einer Sterberate bei über 90 Jahren von 0, 1, undef, NaN ?
- einer Wegzugsrate von 1 bei beliebigem Alter ?
- wie soll man glätten und wann soll man auf übergeordnete Raten z.B. Sterblichkeitsziffern zurückgreifen und wie diese in SIKURS-Raten umwandeln