Last modified: 31.08.2024
blackbox_test für Überprüfung SIKURS-Excel-Beispiele unter SIKURS 10.5input.csv
input_roh.csv enthält Dezimalpunkt statt Dezimalkomma
set decimalsign ';' ersetzt durchset decimalsign locale 'German_Germany.1252'
[#123456 ] HintergrundfarbeFehlermeldung vor Neustart beheben
eck(gz|le)we.csv immer, nicht nur bei
Protokollumfang Tools 3
bwsaldo.csv
der Binnenwanderungsströme strom.csv,
d.h. vieviel gewinnt Binnentyp a gegenüber Binnetyp b pro
Jahr, BG, GG, AGbwsaldo.csv mitgstrom.csv ist denkbar
.../beispiel/regtest/strb1992.csv)
pngcairo Ersatz durch Format png
$f->(($y<10)?0.1*$y:($y<20)?0.05*$y:0.025*$y); # Polygon in SIKURS 10.4 $f->(polygon([0,10,20,30],[0.1,0.05,0.025,0.0125],$y)); # neues Polygon $f->(spline([0,10,20,30],[0.1,0.05,0.025,0.0125],$y)); # oder etwas runder
dots cs_dots fsteps histeps acs mcs cs acs_points mcs_points acs_dots mcs_dots
refgem.csv um Gebiete aus
räumlichen Aggregaten eines Teilschlüssels R01/R02 zu bilden.saldvol.csv wurden
negative Salden auf 0 gesetzt, jetzt sind positive und
negative Werte möglich.
[2 ] Einschalten experimenteller Programmfunktionen
dstbest2018.txt[1-* ] Satznummern
Auswahl Sätze nach Satzinhalt
$bb->{P08}++;
$add->(A01,P02);
...
[v] Zahlfeldstatistik - min, max, mean, ... der Zahlfelder
mit Ergebnis datbest2018.htm
blackbox_test 1, 0;
log.htm in log.txt umbenannt
SIGMAag.csv altersspezifische Sexualproportion
[1305 ] Binnenwegzugsmatrixgstrom13_05.csv: Aggregation gstrom.csv von Gebiet auf räumliches Aggregat (13) nach Gebiet auf TYB (5)
reftyp Spalte 13, sinnvoll, wenn Gebiete zu klein für
statistisch relevante Aussagen sind.
[2 ] Ausgabe GEM!option($MONTE_CARLO 1 $MBF 2 RANDOMLIMIT 50 ZOMBIE 1);alt: +G-S-WA-OBN-WB-OI-OBR-OAR+IBR+ZA+IBN+IAN+ZB+II-WBGv+WBGnneu: +G-S+ZA-WA+IBN-OBN+ZB-WB+II-OI+OBR-OBR+IAN-OAR+WBGn-WBGv
[#ffffff ] HintergrundfarbeHintergrundfarbe Vordergrundfarbe #ffffff (weiß) #000000 (schwarz) #000000 (schwarz) #ffffff (weiß) #444444 (dunkel) #bbbbbb (hell) #004400 (grün) #ffbbff (rosa)Für Protokolle und Hilfeseiten kann man einen "dark mode" wählen durch Einstellung:
eckgzw.csv und
"Sterberaten nach Vorgabe Lebenserwartung" ecklew.csv
streichen unnötigen Pseudokommentar#! (1..17)(1..2)
# vorläufige Geburenraten #TYG;BG;GG;AG 1;1;1;15;0,123;# vermutlich zu hoch 1;1;1;16;0,234 1;1;1;17;0,345;# sicher richtig ! ...
(*) Linienplot Absolutwerte [cs_points]
[v] Altersgruppen zu ALtersklassen zusammenfassengstrom.csv
[4711 1 100 ] Monte-Carlo Methode!option($MONTE_CARLO 4711) option($ZOMBIE 1) option($RANDOMLIMIT 100) option($MBF 3)
!option($SPARSEGEM 0) und
STRM-Dateien !option($SPARSESTRM 0) 0% statt 30%,adeton.pl und
!option($ADTBW 1) für Tests mit der ADETON-Methode
strb Datei
wurde korrigiert (um 0,5 erhöht).eckle für die Berechnung Sterberaten
nach Vorgabe Lebenserwartung sollte man entsprechend anpassen.
!option($LE 6))- nach destatisgrnvzgr('fruc2000'); # Geburtenraten nach Vorgabe zusammengefasste Geburtenrate
srnvle('C:/.../strb2020',57,1)); # Sterberaten nach Vorgabe Lebenserwartung
nach der Prognose
# Indikatoren mit Parametern aus sikurs.ini:
indikator(1);
# Reporting in Differenzierung Gebiet und Parametern aus opt.txt falls vorhanden:
report(2);
# Zeitreihe zr_gem.csv ohne Ausgangsbevölkerung für Haushalteprognose in Unterverzeichnis hhp:
zeitreihe('../hhp/zr_gem', ['$i', 'reftyp 1 12', '$i', '$i', '$i'], { subset => 2 });
hhprog 'hhp'; # Haushalteprognose
# Zeitreihe für X/Y-Plot Entwicklung Gesamtbevölkerung
zeitreihe('zr_gem_agg', '$i,$i,1,1,0');
xyplot('zr_gem_agg'); # > zr_gem_agg.png
# Ausgabe Binnenströme gstrom.csv als heatmap gstrom.png
matrix(fn => 'gstrom', shape => 4, size => 1000);
# Zeitreihen zr_gem2020.csv, zr_gem_2029.csv für Thematische Karte "Prozentuale Zunahme Endbevölkerung 2029 zu Ausgangsbevölkerung 2020"
zeitreihe('gem', 'zr_gem'.$_, [qw($i $i 1 1 0)], { jahre => [$_]}) foreach(2020, 2029);
# Prozentuale Veränderung (100 * (zr_gem2029 - zr_gem2020) / zr_gem2020) -> zr_gem20_29
my $prozent = sub { my $r = shift; $r->[2] = 100 * ($r->[1] - $r->[0]) / $r->[0] }; # p = 100*(e-a)/a
appcol('.', '2..5', $prozent, 'zr_gem2020', 'zr_gem2029', 'zr_gem20_29');
thematicMap(colattr => 6, shapefile = 'C:/.../shapefile.shp', datafile => 'zr_gem20_29'); # > zr_gem20_29.png
# starte R-script für abschließende Berechnungen
system('C:\...\Rscript.exe', 'C:\...\myscript.R');
(roadmap 106)
[3 ] Dateiauswahl (3: manuelle Auswahl)
[2 ] Histogramme der MerkmalswerteLegende für Geschlechtsgruppen
[{/Arial:Bold=50 \U+2642} ] 1
[{/Arial:Bold=50 \U+2640} ] 2
für die Unicode Symbole
\U+2642 ♂
\U+2640 ♀[v] Ausgabe 'Inf' und 'NaN'| Inf | 1 Sterbefälle bei 0 Bestand gibt Rate 'Inf' (infinity) |
|---|---|
| NaN | 0 Sterbefall bei 0 Bestand gibt Rate 'NaN' (not a number) |
!GEMALL 2 -- alt !option($GEMALL 2) -- neusiehe Prognose/Berechnen/?
gem2020.csv gem2012.csv ... dsga2020.csv dsga2021.csv ...
zq2020.csv zq2021.csv
Zeitreihendateien zr_gem.csv dsga.csv zq.csv mit
jeweils Jahr in Spalte 1.
(roadmap 101)
reftyp.csv kann man mit Typ Geburtenraten (...) = 0,
alle Geburtenraten (...) auf 0 setzten.zr_bew.csv
*" für "alle Indices" in csv-Dateien:strb2020.csv mit 7 Typen $NTYS, 2 Alters- $NBG und Geschlechtsgruppen $NGG, 100 Altersgruppen $NAG mit gleicher Sterberate 0,1:
*;*;*;*;0.11..$NTYS;1..$NBG;1..$NGG;0..$NAG-1;0,11..7;1..2;1..2;0..99;0,11;1;1;00;0,1
...
7;2;2;99;0,1eckgem.csv)ecktyp.csv)!option($MRDT 1)eckreg und Vorgabe Mindesthöhe Eckwert
in Warnmeldungblackbox_test 1, 1; für Gebiete ohne Altersgruppenfortschreibung (TYAGF = 0) verbessert
!IPF 1 falsche Ausgabe "#" Ausgabe "inf" für keine Obergrenze
[v] Legende für Bevölkerungsgruppen anzeigen (*) [BG ] Titel für Legende Bevölkerungsgruppen (*) Legende und Farbe der Bevölkerungsgruppen (*) [1;3;0.3 ] 1 [2;1;0.3 ] 2 Legende für Geschlechtsgruppen (*) [männlich ] 1 [weiblich ] 2in der ini-Datei und nutzt die Einstellungen in
[g]strom.csv, Außenzuwanderung [g]zuzug.csv
Außenwegwanderung [g]wegzug.csv, Neubauerstbezug
[g]neba.csv, Rückbauendauszug [g]reaa.csv
wahlweise in Differenzierung Typ oder Gebiet (Präfix g).[v] Byte Order Mark
[v] Verwende Umlautezudq skalierenzuaq) mit Hinweis
im Protokoll automatisch skaliert.nebq, E reaq,
Y bgwgq
reftyp-EintragTYAGF = 0: (statt 2) keine Altersgruppenfortschreibung1 oder 1..$NTYG1, 1..2 oder
1..$NBG[100 ] Anzahl Altersgruppen1 oder 1..$NTYS1, 1..2 oder
1..$NBG
(siehe roadmap 053.11)
#Geburtentyp;Bevölkerungsgruppe;Altersgruppe;Rate 1;1;12..51;hadwiger($3 1,153543498 29,5 29,888691366019 25,9264020056364) 1;2;11..47;hadwiger($3 1,573178309 27,5 28,168260145710 30,8067937264654)
#TYS;BG;GG;AG;Rate 1;1;1;00..06;weibull($4 (-58,6575930054062) 3,61287974369576 13,0651816905308) 1;1;1;07..18;0,000138750000452987 1;1;1;19..99;weibull($4 134,127250235791 462,687761770128 (-5634,22577788568)) ...
[5 ] Hintergrundgitter| 2 | 1/2-Quantil = 50% Perzentil = Median |
|---|---|
| 5 | 1/5-Quantil = Quintil = 20% Perzentil, ..., 4/5-Quantil = 80% Perzentil |
| 20 | 1/20-Quantil = 5% Perzentil, ..., 19/20-Quantil = 95% Perzentil |
[v] Pyramide pro Bevölkerungsgruppe[5 ] Anzahl Altersgruppen pro BalkenOptionen/Systemeinstellungen/CSV/Kommentar mit Datum
zr_gem.csv: #Aggregation Zeitreihe, 5-te Spalte nebeneinander: Altersgruppe(int($i/20)), Entferne Merkmal: Gebietskennzeichen, Aggregationsfunktion: #keine;keine;keine #SIKURS 10.3.0.831: Donnerstag, 10. Mai 2018 13:07:03 #Jahr;Bevölkerungsgruppe;Geschlechtsgruppe;0;1;2;3;4 1991;1;1;8045,02413;17216,41273;10475,32581;6206,6177;924,01034 ...
#!cut(4)
Zeitreihe [v] Aggregation Zeitreihe [zr_gem_3 ] [ /100 ] Gebietskennzeichen [ entferne Merkmal ] Bevölkerungsgruppe [ keine ] Geschlechtsgruppe [ ^99 ] Altersgruppemit Wahl Ausgabedatei
zr_gem_3.csv und den Formeln
/100 |
Abschneiden von 2 Stellen eines hierarchischen Gebietsschlüssels z.B. 12345 -> 12entspricht int($i/100) oder substr($i,0,-2) bei Ergebnis Zeitreihe
|
|---|---|
entferne Merkmal |
Aggregation Merkmal wie bei alle Ausprägungen,
aber ohne Ausgabe (der Konstante 1) in die Ausgabedatei
|
keine |
keine Aggregation Merkmal |
/5 |
Aggregation von 100 Altersgruppen in 20 Altergruppen zu je 5 Jahren z.B. für die Visualisierung dünn besetzter Pyramiden entspricht int($i/5) bei Ergebnis Zeitreihe
|
^99 |
Altersgruppe 99 enhalte in der Ausgabedatei die Altersgruppen 99 und älter z.B. wenn die Prognose mit mehr als 100 Altersgruppen gerechnet wurde entspricht min($i,99) bei Ergebnis Zeitreihe
|
#!cut(4)
refbg.csv
zr_gem.csv).
Damit kann der Anwender mehreren Aggregaten sinnvolle Namen geben.index.html verschickt,
dann ist auch Inhaltsverzeichnis enthalten
(vorher in Zusatzdatei toc.htm).
eckgem.csv: #jhr;g;gkz;Eckwert 2020;1;101;gem() # Summe Bevölkerung gem2019.csv Gebiet 101(siehe Benutzerhandbuch, Eingabedatei eckgem.csv)
[v] Altersgruppen zu Altersklassen zusammenfassenaltersklassen.csvupgrade_to_sikurs_9_2.pl*_roh.csv Dateien ähnlich
wie in der Standardprognose
#TYA;TYZZA;BG;GG;AG;Quote 1; 1; 1; 1; 0;0,2 1; 2; 1; 1; 0;0,3 1; 3; 1; 1; 0;0,5 # Σ = 1 ... 5; 1; 2; 2;99;0,4 5; 2; 2; 2;99;0,1 5; 3; 2; 2;99;0,5 # Σ = 1um die Summe über die Typen Zuzug von Außen besser berechnen zu können (roadmap 056)
!AUSGABE_GSTROM 2Referenzdatei [referenz ] Name [2 ] Spaltennummer Typ [0 ] Abbildung R02/R02U2wurde das Eingabefeld Name entfernt, die Datei muss immer
reftyp.csv heißen.reftyp.csv benötigt.reftyp.csv mit Spalte
11 für Typen Haushalteprognose zu verwenden wie bei der SIKURS-Prognose.reftyp_roh.csv wurde in die
Berechnung Makrodaten aus Statiskdatensatz Bestand vorverlegt, weil
die den "work flow" vereinfacht.[ ] Raten bis auf DSGR aus Nettobestand (nur bei experimentell)#128 aus
R02/R02U2 sowie RQZ/RQZU2.reftyp_roh.csv wird aus allen Bestanddateien abgeleitet
(statt später aus den Makrodateien)
#! (1..17)(1..2) # für 17 Typen Geburtenraten und 2 Bevölkerungsgruppen $tyg;$bg;15..19;$f->()*$c->() # 1. keine Anpassung an Zielwert $tyg;$bg;20..44;$f->($y/12) # 2. Verschiebe Pyramide pro Jahr um einen MonatAus der Prognose-Ausgabedatei gebam lassen sich mit Ergebnis/Zeitreihe Durchschnittsalter sowie Altersstreuung der Mütter ermitteln.
[1 ] undefinierte WerteFalls in einer Altersgruppe Zähler (Bewegung) und Nenner (Bestand) Null sind wird als zugehörige Rate 'undef' eingetragen.
Prognose/Notiz !GEMALL 2(roadmap 009)
!DSGG 2 3 # REFTYP Spalte TYHH enthält Typ Demographische SondergruppeParameter
#gem2014.csv: 2570000001;1;1;03;2 ...Die ersten z.B. 3 "signifikanten" Stellen des GKZ soll den Untersuchungsraum in für die Typisierung relevante Teilgebiete zerlegen.
#! 7) sollen für
REFTYP irrelevant sein2570000001 bezeichnet Haushalt
0000001 im Teilgebiet
257#GKZ;Name;Geburtentyp;... #! 7 - GEM hat weitere 7 Stellen im Gebietskennzeichen 257;Schwabing;2;3;1;... 259;Freimann ;1;2;2;... ...In Eingabdaten Berechen kann diese Anzahl
[ 7] Abbildung Gebiet GEM in Sammelgebiet REFTYPfür die Erzeugung einer Musterdatei REFTYP angegeben werden
green) zuzuweisen
und eine dbf-Datei als csv-Datei zu exportieren.bewgemagg.csv#1 == 2013 und
linespoints/lines/points/steps für Linienplot Absolutwertezuvol.csv.lnk, dstbest.txt.lnk.lnk nach der Endung für den Dateityp..lnk sieht man im file explorer nicht.reftyp.csv für die Abbildung Gebiet
in Typ bei der Quotenberechnung[1-* ] Satznummern [ ] Ausgabe Sätze in Tabelle [ ] Ausgabe Sätze in csv-Datei [v] Histogramm der Merkmalswerte
dstbest (statt bestand ist der Name für
die Datei Statisikdatensatz Bestanddstbew heißt der Staistikdatensatz Bewegung
size 1600,1200" und
"font 'Arial,7' optimiert
dstbew weiter Makrodateien oder Makrodateien
mit anderen Filterbedingugen abgeleitet werden.
"#Ausgangsbevölkerung";;;;; "#Jahr";"Gebiet";"Gruppe";"Geschlecht";"Alter";"Anzahl"zu machen
sikurs_9_..._x86.exe für alle Windows-Versionen, nutzt 32-Bit Modus, d.h. max. 4GByte Arbeitsspeicher
sikurs_9_..._x64.exe ausschließlich für 64 Bit Windows, nutzt mehr als 4 GByte Hautspeicher (falls vorhanden)
!link eckgem_v2.csv eckgem.lnk # alt
!unlink eckgem.lnk # alt
shortcut('eckgem_v2.csv', 'eckgem.lnk'); # neu
remove 'eckgem.lnk'; # neu
und es kommen neue Befehle für Plausibiltätschecks dazu
(siehe Hilfe in Startmaske Prognose)
| alt | neu |
|---|---|
| L0 | G0 S0 |
| L1 | G1 S0 |
| L2 | G0 S1 |
| L3 | G1 S1 |
| alt | neu |
|---|---|
| D0 | D0 |
| D1 X1 | D1 |
| D1 X2 | D2 |
#$expand(1) sich im
Versionsunterzeichnis als expandierte Kopie befindet,
dann wird nur letztere in der Indikatoren-Zeitreihe berücksichtigt.
let($Q read(demoq)) 2011;1000;1..$NBG;1..$NGG;0..$NAG-1;7052*$Q($3 $4 $5)siehe auch Verzeichnis .../sikurs/Beispiel/generic/ die Dateien gem1999.csv fruc2000.csv strb2000.csv jeweils Variante ?$G8:
#$list(1)expand(1) wird ersetzt durch
Funktionsaufruflist(1) expand(1)
attrib -R v.ini#! (1..17)(1..2)(1..2)
1..NTYG
1..$NTYS
1..$NTYS;1;1;3;0,02 1..$NTYS;1;1;97;0,4d.h. die Eingabedateien können Variable wie "1..$NTYS" beinhalten, dann muss aber die ganze Spalte "1..$NTYS" enthalten. Weiterhin können die Altersindices luckenhaft sein.
2012;1..$NTYB;1..$NBG;1..$NGG;00;0,3 ... 2020;1..$NTYB;1..$NBG;1..$NGG;99;0,2Die alte Version steht vorübergehend zum Vergleich unter "Start/Datenaufbereitung/Zeitreihe (alt)" bereit.
| -p | d | r |
|---|---|---|
| 0 | 37143 208110 | 2792 2870 |
| 1 | 13880 518719 | 1841 1685 |
...\sikurs.exe -p=0 erzwingt sequentielle Verarbeitung.
...\sikurs.exe -m=r321..$NTYS;1..$NBG;1..$NGG;00;0,01
| # | alt | neu | Quelle neu | Kommentar neu |
|---|---|---|---|---|
| 1 | GKZ | GKZ | 1 | Gebietskennzeichen |
| 2 | Name | Name | 2 | Gebietsname |
| 3 | NTY | NTYG | 6 | Typ Geburtenrate |
| 4 | NRA | NTYS | 6 | Typ Sterberate |
| 5 | NTYE | NTYB | 3 | Typ Binnenwanderung |
| 6 | NTYN | NTYE | 5 | Typ Erstbezug |
| 7 | NTYZZA | 5 | Zieltyp Außenzuwanderung (*) | |
| 8 | NTYQWA | 5 | Quellentyp Außenwegwanderung (*) | |
| 9 | NTYW | NTYW | 7 | Typ Wechsel der Bev.Grp. |
| 10 | NTYHH | Typ Haushalteprognose | ||
| 11 | NRA1 | 4 | Schlussel Aggregationseinheit 1 | |
| 12 | NRA2 | Schlussel Aggregationseinheit 2 |
Beim Upgrade der ini-Dateien wird der Wert von NTYA auf NTYZZA, NTYQWA, der von GNTYN auf GNTYG, GNTYS abgebildet und die Einträge NTY, NTYA, NTYE, NTYW gestrichen, da diese Werte aus reftyp abgeleitet werden.
plot sin(x) load 'C:\...\gnuplot.txt' exit
batch_all_parallel.pl C:\...\meine_Prognosen 4 rsikernr.exe -m=0" eingeführt,
die das Mutex gegen mehrfache Ausführung und die Ausgabe in die
log-Datei ausschaltet.
#Jahr;Gebiet;BG;GG;AG;Wert
| alt | neu M | neu N |
|---|---|---|
| M0 | M0 | N0 |
| M1 | M1 | N0 |
| M2 | M2 | N0 |
| M3 | M0 | N1 |
| M4 | ||
| M5 | M0 | N2 |
| M6 | M0 | N3 |
| M7 | M0 | N4 |
$list 0 $expand 0 mit führendem Kommentarzeichen versehen #$list 0 #$expand 0
BSL():!Test natürliche Bevölkerungsprogose(siehe ...\sikurs\beispiel\generic\nbb.ini), dann wird diese Zeile zusätzlich zum Ablaufprotokoll im sogannten Miniprotokoll ausgegeben, d.h. er erscheint zusätzlich im Textfenster der Hauptmaske, in der Logdatei (Hauptmaske/Datei/Logdatei) und im Sammelprotokoll von Hauptmaske/Start/Eigene Scripts/Start/batch_all.pl.
| m BG | AG | BG w | ||
|---|---|---|---|---|
| 2 | 1 | 1 | 2 | |
| 20 | 40 | 00 | 30 | 50 |
| 16 | 22 | 01 | 21 | 33 |
| ... | ||||
| 5 | 3 | 99 | 6 | 2 |
SIKDIR=C:/home, sondern als
Aufrufparameter -w=D:/home -e=1
oder Umgebugsvariable SIKURSOPT=-w=D:/home -e=1
(siehe Sikurs/Hilfe/Installationsanleitung)
a: Indices b: Ausgangsvektor [0 .. 4] alle Werte 1 c: geglätteter Vektor über den Rand "verschmiert" [-2 .. 6] d: altes Verfahren: überstehenden Rand auf [0] und [4] addieren e: neues Verfahren: überstehenden Rand auf [0 .. 1] bzw [3 .. 4] verteilen a b c d e --+---+----+----+---- -2 1/5 -1 2/5 0 1 3/5 6/5 5/5 1 1 4/5 4/5 5/5 2 1 5/5 5/5 5/5 3 1 4/5 4/5 5/5 4 1 3/5 6/5 5/5 5 2/5 6 1/5
K0 keine Vorgabe: bleibt K1 Zielwert global: neu definiert - aber noch nicht implementiert K2 Zielwert NTYA (K1) K3 Zielwert NBG NTYA (K2) K4 Zielwert NGG NBG NTYA (K3)
if (A1<18 && P03==1 && KERNS!=2 && HNACH!=2 && HNACH!=6) PDO[i]=1;
erf (Integral Gaußsche Normalverteilung) und Auswahl der
gewunschten Kurven.
2000..2003;1..$NTY;1..2;1..2;75,9.
Fehlende Werte in den Eingabedateien werden durch 0 (strb, eckle) bzw 1
(weight) ergänzt.
my $ppa = 5;
'format' => 'gif',
'frames' => [[1,1,1]],
'pyramid' => {
'scale' => 'bar',
},
'circle' => {
'show' => 0, # Anzeige 0=nein 1=ja
},
'animation' => {
'duration' => 500, # ms Dauer Animation für ein Jahr
},
| batch_all batch_all_clean | Wählt ein SIKURS Datenverzeichnis und startet Prognosen für alle ini-Dateien im Verzeichnis und allen Unterverzeichnissen Löschen der Prognoseergebnisse |
|---|---|
| csv2xls xls2csv | v1.ini sei die aktuelle ini-Datei: kopiert alle zu v1 gehörigen csv-Dateien in eine Excel Datei v1.xls, zu große csv-Dateien werden aufgeteilt extrahiert alle Blätter von v1.xls in ein Unterverzeichnis tmp |
| glätten | Test Savitzky-Golay Glättung |
| testrandom | Startet eine wählbare Anzahl von SIKURS Prognosen mit zufälligen aber gultigen Parametern Kann alle Prognoseergebnisse wieder löschen |
SIKDIR=C:\Verzeichnis mit Schreibrechten| %.0f | 120409 | ohne Nachkommastellen |
| %.2f | 120409,34 | Voreinstellung für Anzahl |
| %.6f | 0,345678 | Voreinstellung für Rate/Quote |
| %.15g | 0,345678012345654e-12 | Fur sehr kleine/große Werte |
!link v1_zuvol.csv zuvol.lnk
!link ../generic/bgwr2000.csv bgwr2000.lnk
!link F:/pool/gem2001.csv gem2001.lnk
bzw. am Ende wieder zu löschen
!unlink zuvol.lnk
!unlink bgwr2000.lnk
!unlink gem2001.lnk
rem Diese Zeilen werden von CMD.EXE ausgeführt echo Parameter sind Sikurs-App=%1 Verzeichnis=%2 Version=%3 Jahr=%4 cd %1 shortcut /a:c /t:%2\sterberaten2003.csv /f:%2\strb2003.lnkDer Kommandozeileninterpreter wird mit 3 Parametern aufgerufen:
Das Kommando shortcut erzeugt Verknüpfungen. Eine genaue Beschreibung erhält man dirch den Aufruf "shortcut/?".
Wem die Möglichkeiten des Kommandozeileninterpreters nicht reichen, der kann andere Scriptsprachen (z.B. sh, bash, tcl, lua, ruby, perl, ...) einsetzen:#! perl -w print "Hallo hier ist Perl\n"; print "hier könnten beliebige SIKURS-Ein/Ausgabedatein bearbeitet werden\n";oder ein realistischeres Beispiel für ein Perl-Script zwischen den Prognosejahren findet sich in beisp_1.
rem \windows\sikurs.ini: [DEFAULTS] Directory muss richtig gesetzt sein c:\...\sikurs\App\sikernr.exe -v=version1 c:\...\sikurs\App\sikernr.exe -v=version2 c:\...\sikurs\App\sikernr.exe -v=version3erledigen.
c:\...\sikurs\App\sikernr.exe -d="c:/Mein Verzeichnis1/" -v=version1 c:\...\sikurs\App\sikernr.exe -d=f:/pool/dat/ -v=versiona c:\...\sikurs\App\sikernr.exe -d=f:/pool/dat/ -v=versionb rem HHPROG mit Quotenberechnung (-q=1) und Prognose (-p=1) von 2000-2003 c:\...\sikurs\App\hhprogr.exe -d=c:/hhprog/dat/ -m=1 -a=0 -q=1 -p=1 -s=2000 -e=2003 -v=1 -z=100Beachte:
rem setze Werte in windows\sikurs.in (mind. Directory und Version) rem setze Werte in version.ini (mind. startjahr = endjahr = j) c:\...\sikurs\App\sikernr.exe -a=1 rem analysiere Ausgabedateien aus Jahr j und setzte Eingabe für Jahr j+1 c:\...\sikurs\App\sikernr.exe -a=100 rem analysiere Ausgabedateien aus Jahr j+1 und setzte Eingabe für Jahr j+2 ... rem analysiere Ausgabedateien aus Jahr j+8 und setzte Eingabe für Jahr j+9 c:\...\sikurs\App\sikernr.exe -a=902Beim Schalter -a zählt die Hunderterstelle die Prognoseabschnitte, die Einerstelle bedeutet:
[METHODE]
NAG=10 ;Anzahl Altersgruppen, Default 100
NAGFU=3 ;Fruchtbarkeit Untergrenze, Default 15
NAGFO=6 ;Fruchtbarkeit Obergrenze, Default 44
Damit läßt sich eine kleinräumige Prognose einer
Kaninchenpopulation rechnen (siehe generic/rabbit.ini) ;-)
In Laufzeitparameter/Notiz kann man folgendes eingeben:
!link eckgem_v1.csv eckgem.lnk
!link "zuvol v1 mit blanks im Namen.csv" zuvol.lnk
!link ../../dat/sub/refagg.csv refagg.lnk
Dann werden vor der Prognose im aktuellen Datenverzeichnis
diese Verknüpfungen erzeugt....\sikurs.exe /e=1Die Animation besitzt bisher keine Benutzeroberfläche
Bedienung:prot.htm mit einem Texteditor öffnen und die
html-Tages wie z.B. <pre> ignorieren oder entfernen.
Bewegungen in Gebiet #1 im Jahr 1994:
Geburten : 1165,68
Sterbefälle : -1010,33
Außenwegzug : -9688,31
Außenzuzug : 10532,96
Binnenauszug : 0,00
Binneneinzug : 0,00
GEBURTEN (in Binnentypen):
DR2G(NGG:1-2 NBG:1-2 NTY:1-1) = 1165,6786191
DR2G(NGG:1-2 NBG:1 NTY:1 ) = 992,1919826
513,36013181658 478,83185082080
DR2G(NGG:1-2 NBG:2 NTY:1 ) = 173,4866365
89,76198570233 83,72465075366
STERBEFAELLE NACH GESONDERTER TYPISIERUNG (NAT-TYP):
DR3SN(NAG:0-99 NGG:1-2 NBG:1-2 TNTY:1-1) =-1010,3261896
...
abs(1 - SummGebiete/SummeTypen) > EPSeine Warnung ausgegeben.
int = floor(double) : Gleitkommazahl auf Integer abschneiden
int = ceil(double) : Gleitkommazahl auf nächtst höhern Integer setzen
double = max(double, double) : Maximum ermitteln
double = min(double, double) : Minimum ermitteln
Nicht abgefangene Ausnahme in Sikurs.exe (GDI32.DLL):
0xC0000005: Access Violation.
--M A B C--------
..0-0-0-0/1/2/3/4
1/3-0-1-0/1/2/3/4
...+1-0-0
...+1-1-0
2/4-0-2-0/1/2/3/4
...+2-0-0
.....+2-0
| N | A | B | C |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 |
| 2 | 2 | 0 | 0 |
| 3 | 0 | 1 | 0 |
| 4 | 0 | 2 | 0 |
| 5 | 1 | 1 | 0 |
| 6 | 2 | 2 | 0 |
| 7 | 0 | 0 | 1 |
| 8 | 0 | 1 | 1 |
| 9 | 0 | 2 | 1 |
| 10 | 0 | 0 | 2 |
| 11 | 0 | 1 | 2 |
| 12 | 0 | 2 | 2 |
| 13 | 0 | 0 | 3 |
| 14 | 0 | 1 | 3 |
| 15 | 0 | 2 | 3 |
| 16 | 0 | 0 | 4 |
| 17 | 0 | 1 | 4 |
| 18 | 0 | 2 | 4 |
| Definition | Nr. | Wenn |
|---|---|---|
| keine Anpassung, Trend/Status-Quo-Berechnung | N0 | M0 |
| Anpassung Wegzugsvolumen | N1 | M1,M3 |
| Anpassung Wegzug in demographischer Gliederung | N2 | M2,M4 |
| Anpassung Zuzugsvolumen | N3 | M1,M3 |
| Anpassung Zuzug in demographischer Gliederung | N4 | M2,M4 |
| Simultane Anpassung Zu- und Wegzugsvolumen | N5 | M1,M3 |
| simultane Anpassung Zu- und Wegzug in demograph. Gliederung | N6 | M2,M4 |
| wie N0, zusätzlich Zielwert für Wegzugsstrome | N7 | M0 |
| wie N3, zusätzlich Zielwert für Wegzugsstrome | N8 | M1,M3 |
| wie N4, zusätzlich Zielwert für Wegzugsstrome | N9 | M2,M4 |
| wie N0, zusätzlich Zielwerte (NTYA) für Wegzugsströme | N10 | M0 |
| wie N3, zusätzlich Zielwerte (NTYA) für Wegzugsströme | N11 | M1,M3 |
| wie N4, zusätzlich Zielwerte (NTYA) für Wegzugsströme | N12 | M2,M4 |
| wie N0, zusätzlich Zielwerte (NBG*NTYA) für Wegzugsströme | N13 | M0 |
| wie N3, zusätzlich Zielwerte (NBG*NTYA) für Wegzugsströme | N14 | M1,M3 |
| wie N4, zusätzlich Zielwerte (NBG*NTYA) für Wegzugsströme | N15 | M2,M4 |
| wie N0, zusätzl. Zielwerte (NGG*NBG*NTYA) für Wegzugsströme | N16 | M0 |
| wie N3, zusätzl. Zielwerte (NGG*NBG*NTYA) für Wegzugsströme | N17 | M1,M3 |
| wie N4, zusätzl. Zielwerte (NGG*NBG*NTYA) für Wegzugsströme | N18 | M2,M4 |
P ist soll -+----+---- 0 NGRT - 1 NGR NGR 2 NGR NGR 3 NGR NGRT 4 NGRT NGRT
Zweck: Aufbau eines umfassenden Regressionstests und
Ausführung von Prognosereihen.
Dynamisierung beliebiger Eingabedateien nach
selbstdefinierten Kriterien.
Syntax:
SIKURS/S section key
SIKURS/M section key
SIKURS/s section key value
SIKURS/m section key value
SIKURS/p
Bedeutung:
/S Kopieren Systemeinstellung in Datei SIBATCH.TMP
/M Kopieren Methodeneinstellung in Datei SIBATCH.TMP
/s Änderung von Systemeinstellungen:
Datei: \windows\sikurs.ini
Abschnitt: [section]
Wert: key=value
/m Änderung von Methodenparametern:
Datei: (siehe Einträge in Systemeinstellungen)
Abschnitt: [section]
Wert: key=value
/p Start eines Prognoselaufes
Beispiel siehe SIBATCH.BAT, BATCH?.PL
Zeichenkettenbegrenzer: (leer) Ganzahlformat : (leer) Gleitkommaformat : (%.10g) Stapelhöhe : 5
1;1;1;0;0,23 1;1;1;1;0,24 ....Die Zahl der Indices variiert und GEM beginnt mit einer Jahreszahl. Jeder der obigen Indices kann durch ein Intervall ersetzt werden:
1-5;1-2;1-2;0-99;0,1
Dies ist eine Abkürzung für:
1;1;1;0;0,1
...
5;2;2;99;0,1
Wozu ist das gut ?
a) Zum Test bestimmter Versionen
Bei systematischen Testdaten sind die Eingabedateien dann
sehr übersichtlich (siehe Verzeichnis BEISPIEL\MINI und
\BEISPIEL\MAXI
b) Wenn man noch nicht alle Eingabedateien hat, dann kann
man fehlende Daten näherungsweise simulieren.
P3 - P4
siwinrel.exe -> sikurs.exe siwindeb.exe -> sikursd.exe und verlagern in Unterverzeichnis bin
Wenn alle Elemente einer Teilmatrix gleich (z.B. 0,0) sind, dann 0,0 ... (*100)
Protokollausgabe unterdrücken wenn z.B. Sterberaten bereits letztes Jahr protokolliert wurden.
Diese Änderungen bringen ein Reduktion der Protokolldatei um (je nach Daten) 30 Prozent und eine Verbesserung der Laufzeit um 5 Prozent.
Konzept:
Ergebnismatrix = undef
loop über alle Eingabezeilen
eingabeZeile = k1, i1, i2, ..., wert
if (Ergebnismatirx(i1, i2, ...) == undef) Fehler "Zeile doppelt"
Ergebnismatrix(I1, i2, ...) = wert
end loop
loop über die Ergebnismatrix
if (Ergebnismatrix(i1, i2, ...) = undef) null_setzen mit Warnung
end loop;
Dabei wurde die Dateistruktur vereinheitlicht.
ECKREG: Erste leere Spalte weg
MEPTxxxx: + Spalte Jahr
NEUBAUB : NGZ -> indNGZ
NEBQxxxx, ZUQxxxx, FRUCxxxx, WEGZxxxx, STRMxxxx: + Spalte Jahr
Vorteil für den Benutzer: Fehlermeldungen wurden verbessert
Leichter Performanzgewinn
Vorteil für die Wartung : wesentlich leichter wartbar
K0 -> K1 K1 -> K2 K2 -> K3 K3 -> K4 M1 -> M0 M2 -> M1 M3 -> M2 N1 -> N0 ... N10 -> N9 P3 -> P0 P4 -> P3 P5 -> P4
SIKURS -> Prognose ZEITREIH -> Zeitreihe
Fehlerbehandlung verbessert Spaltentrennzeichen = blank getestet Zeichenkettenbegrenzer=nichts es wird " genommen
anstalt anst0000 frucht fruc0000 efrucht fruc9999 meptyp mept0000 neubauq nbq0000 sterb strb0000 esterb strb9999 strom strm0000 stwechs stwe0000 wegzug wzug0000 ewegzug wzug9999 zuallq zaq0000 zudemq zdq0000Dabei bedeutet anst0000: wenn das Prognosejahr 1992 ist, dann wird nach der Datei anst1992.csv gesucht - wenn diese nicht vorhanden ist, dann wird nach anst1991.csv gesucht - usw.
fruc9999 bedeutet: im Prognosejahr wird die Datei fruc1993.csv oder von einem späteren Jahr gesucht.
Durch obige Massnahmen wird SIKURS offen für dynamische Vorgaben, d.h. der Benutzer kann z.B. eine einzige Datei fruc1992.csv für alle Prognosejahre vorgeben, oder eine Dateienfolge fruc1992.csv, fruc1995.csv, fruc1998.csv ...
SIWINDEB.EXE debug-version mit SIWINDEB.INI SIWINREL.EXE release-version mit SIWINREL.INIFür die Benutzung wird folgendes empfohlen: Wenn eine Prognose mit neuen Daten oder mit einer neuen Version (wesentliche Änderungen in Versionsdatei) gerechner werden soll:
Das Protokoll der Zeitreihenprogramme heisst:
version\zeitreih.txt
version\zeitproz.txt
GENDATA.PL Generierung Testdaten für AGG1-4 AGG(1-4).PL Aggregationsprogramme CSTERB.PL Umwandlung "altes" STERB-Format in STERB.CSV GSTERB.PL Gleitendes Mittel für STERB.CSV (verwendet SMOOTH3.PL)
Spaltentrennzeichen=;
Zeichenkettenbegrenzer="
GanzzahlAusgabeformat=%d
Gleitkommaausgabeformat=%g
Für die Einstellbarkeit der Zahlformate drei Beispiele:
Einstellung Ergebnis Anmerkung
--------------+-----------------------------+----------------------------
; " %d %g : 1992;1;1;0;123,456 (kompaktes EXCEL-Format)
; " %2d %10g : 1992; 1; 1; 0; 123,456 (dabank-Format)
; " %2d %12.6f: 1992; 1; 1; 0; 123,456000 (feste Kommastelle)
Diese Einstellungen wirken sich nur auf die Ausgabe aus.
Bei der Eingabe werden nur das Spaltentrennzeichen und
der Zeichenkettenbegrenzer beachtet, d.h. beide obige
Eingabeformate werden problemlos gelesen.
Ein/Ausgabe ohne Spaltentrennzeichen (Spaltentrennzeichen=)
sollte ebenso funkionieren (nicht getestet):
" %2d %8g: 1992 1 1 0 123,456 (dabank-verträgliches Format)
Der Zeichenkettenbegrenzer (z.B. " oder ') wird z.B. in der Datei
reftyp.csv benötigt:
10;"Stadt Erlangen";1;"Aggregat Nr. 1";1;0;1
Eine Kombination ohne Zeichenkettenbegrenzer und ohne Spaltentrennzeichen
kann nicht richtig gelesen werden:
10Stadt Erlangen1Aggregat Nr. 1101
open (INP, "<frucht") || die "fehler: $!";
open (OUT, ">frucht.csv") || die "fehler: $!";
# Umformung Fortran Format in csv-format
while (<INP>) {
($i1, $i2, $i3, $f) = unpack("A2 A1 A2 A12", $_);
print OUT "$s1;$s2;$s3;$f\n";
}
4.1: Kleine Korrekturen bei Bausteinen M, N, P
Index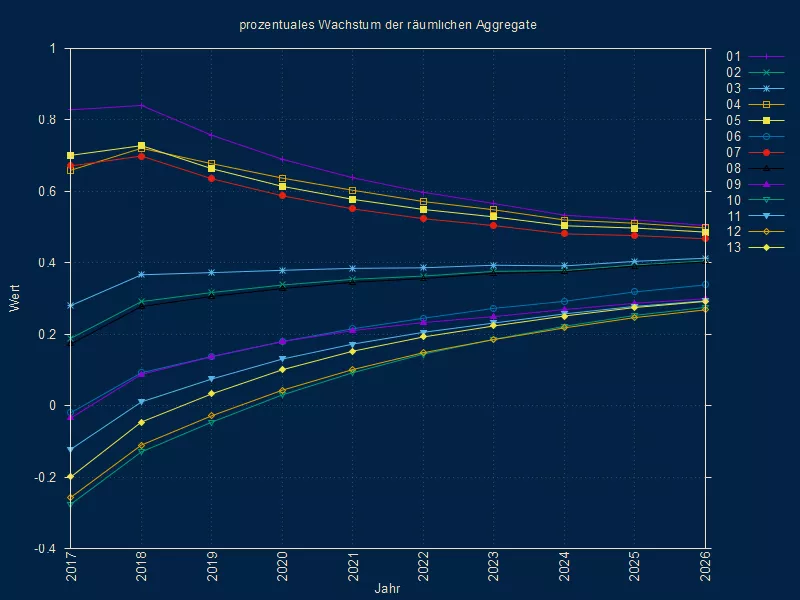{kind=link}
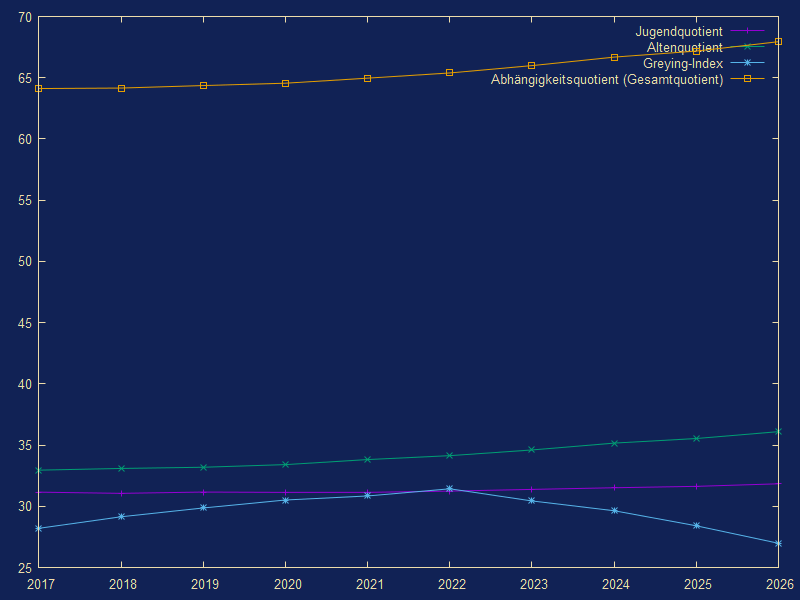{kind=link}
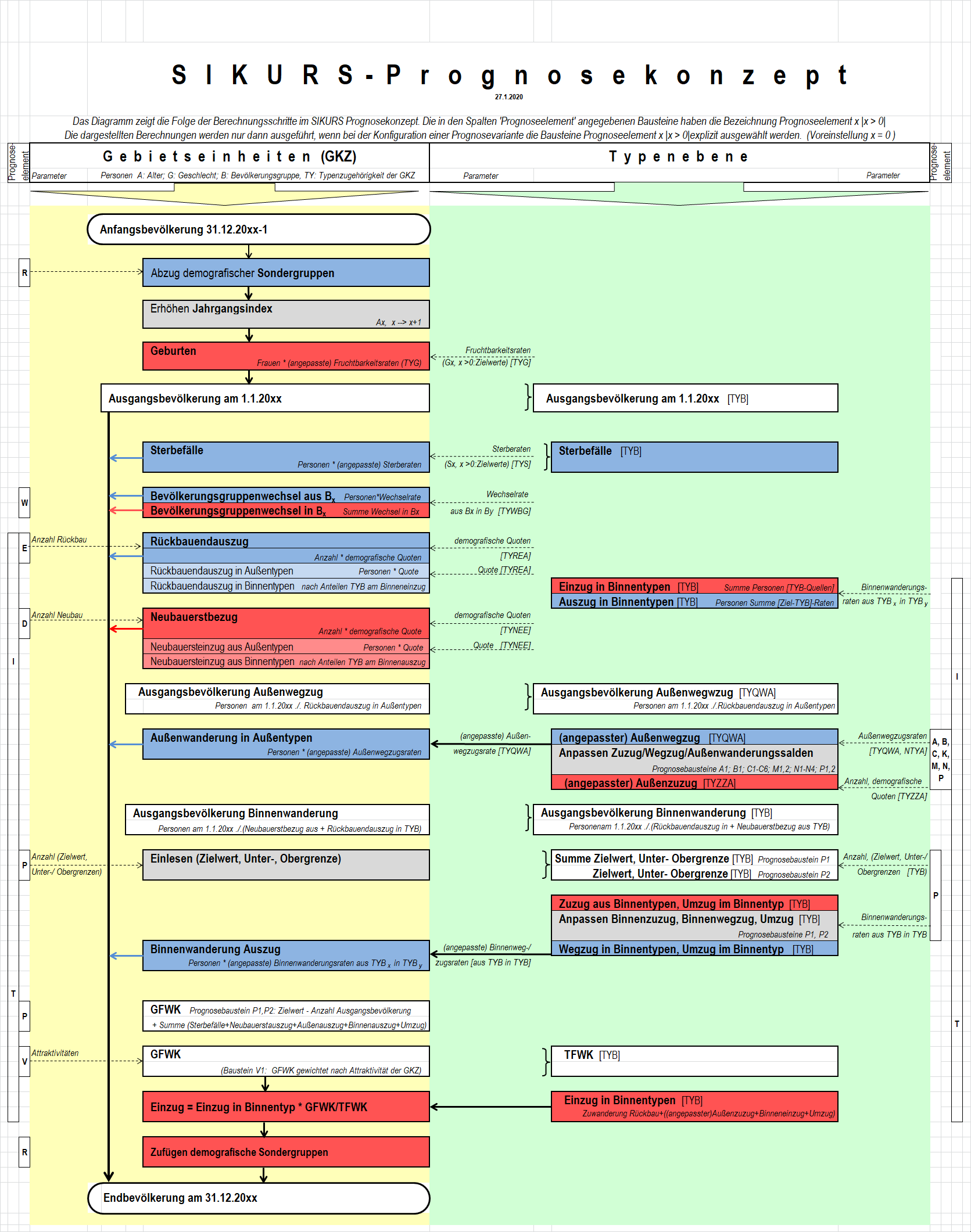{kind=link}
{kind=link}